Для решения задачи глобальной трассировки используются генетические методы оптимизации. Представим решение в виде хромосомы. Кодирование осуществляется следующим образом. Хромосома состоит из генов. Количество генов в хромосоме Hi равно количеству ребер минимальных связывающих деревьев для всех цепей, расположенных на КП. Значением гена является номер варианта из заданного набора вариантов маршрутов, связывающих на графе G соответствующие вершины.
Например, дано КП, на котором расположено множество цепей Т = {t1, t2, t3}, рис. 2.


Так как мы используем графовую модель, то КП можно представить соответственно рис. 3.
Для цепи t1 множество связуемых вершин – Х1 = {x6, x2, х11}. Для цепи t2 множество связуемых вершин – Х2 = {x7, x9, x13 }. Для цепи t3 множество связуемых вершин – Х3 = {x5, x14}. С помощью алгоритма Прима для каждой цепи строится минимальное связывающее дерево МСД. Для каждой из цепей это выглядит так:рис. 4.
 После этого для каждого ребра rij МСД формируется набор вариантов маршрутов, связывающих на графе G соответствующие вершины.
После этого для каждого ребра rij МСД формируется набор вариантов маршрутов, связывающих на графе G соответствующие вершины.
Ребро г11 (то есть первое ребро МСД для цепи 1) имеет два варианта прохождения маршрута r11 = {v111, v112}: v111={x6,x1,x2}, v112={x6,x7,x2}.
Ребро r12 (второе ребро цепи 1) имеет один вариант V121={x6,x11}
Ребро г21 (то есть первое ребро МСД для цепи 2) имеет два варианта прохождения маршрута r21={v211,v212}: v211={x7,x8,x13} v212={x7,x12,x13}.
Ребро r22 имеет два варианта v221={x13,x8,x9}, v222={x13,x14,x9}.
Ребро г31 (то есть первое ребро МСД для цепи 3) имеет три варианта прохождения маршрута, r31 = {v311, v312, v313}, v311={x5,x10,x9,x14}; v312={x5,x4,x9,x14}; v313={x5,x10,x15,x14}.
Для решения представленного на рис. 2. структура хромосомы имеет вид рис. 5

Рис. 5
Число генов равно 5. Гены g1 и g2 соответствуют ребрам r11 и r12 дерева D1; g3 и g4 соответствуют ребрам r21 и r22 дерева D2; g5 соответствует ребру r31 дерева D3. Значение g1 равно 2, т.к. для реализации r11 выбран вариант V112. g2 равно 1, т.к. r12 реализован вариантом V121. Аналогично, т.к. r21,r22 и r31 реализованы соответственно вариантами V211, V221 и V313, то g3=1, g4=1, g5=3.
Отметим, что между структурой и видом хромосомы с одной стороны и решением (распределением соединений на КП) с другой стороны существует взаимно - однозначное соответствие. Отличительной особенностью предложенной структуры хромосомы является то, что отсутствует какая либо зависимость между генами, обусловленная самой структурой. Это свойство исключает возможность появления нелегальных хромосом, подобно тому, как это происходит с хромосомами, представляющими собой списковые структуры. В свою очередь это упрощает реализацию рассматриваемых ниже генетических операторов.
Пусть L – число всех ребер всех МСД. L= число выводов – число цепей. Тогда объем V1 ОЗУ, необходимой для хранения информации об вариантах реализации ребер МСД, будет  , где nv – число вариантов реализации одного ребра.
, где nv – число вариантов реализации одного ребра.
Объем V2 ОЗУ необходимый для одной хромосомы  . К2 помимо всего прочего учитывает необходимость хранения фитнесса хромосомы.
. К2 помимо всего прочего учитывает необходимость хранения фитнесса хромосомы.
Для популяции состоящей из М хромосом  .
.
Таким образом, общий объем памяти  имеет линейную зависимость и при заданных параметрах nv и M пространственная сложность алгоритма ~ O(L).
имеет линейную зависимость и при заданных параметрах nv и M пространственная сложность алгоритма ~ O(L).
3.2 Формирование исходной популяции
Для организации генетического поиска формируется исходная популяция особей P={Hi|i=1,2,..,M}, где М размер популяции. Популяция Р- представляет собой репродукционную группу – совокупность индивидуальностей, любые две из которых HiÎP и HjÎP, i ¹ j могут размножаться выступая в роли «родителей». Предварительно с помощью процедуры FORM осуществляется разбиение КП на области и формирование модели КП в виде графа W=(X,U). Далее для каждой цепи ti Î Т строится алгоритмом Прима один из вариантов минимального связывающего дерева Di={ri, li=1, … ni}
Затем для каждого rij синтезируется набор Vij вариантов маршрутов в ортогональном графе G, реализующих ребро rij. Пусть nij=| Vij | - число вариантов реализации ребра rij.
Определяется длина L хромосомы, являющейся носителем информации о конкретном решении:

Параметр L определяет число генов в хромосоме. С помощью графика соответствия Q устанавливается соответствие Г(G, Q, R) между генами хромосомы и ребрами минимальных связывающих деревьев для всех цепей.
G={gn| n=1, 2,…,L}; R={rij| i=1, 2, …,ni, j=1,2, … ni}
Образом Г(rij) является ген gn. Прообразом Г-1(gn) является ребро rij Значением гена gn, будет номер варианта реализации ребра rij=Г-1(gn).
Ген gn может принимать любое значение от 1 до nij.
В работе используется принцип случайного формирования исходной популяции.
Для этого в пределах каждой хромосомы Нк каждый ген gn принимает случайное значение в пределах от 1 до nij, где nij число вариантов реализации ребра rij=Г-1(gn).
Управляемыми параметрами при формировании популяции является М - размер популяции, nmax - максимальное число вариантов реализации ребер, т.е. ("ij) [nij  nmax]. Если возможное число вариантов nij больше nmax то возникает возможность формирования альтернативных наборов вариантов Vij для rij. Кроме того существует возможность построения альтернативных МСД Di для одной и той же цепи ti.
nmax]. Если возможное число вариантов nij больше nmax то возникает возможность формирования альтернативных наборов вариантов Vij для rij. Кроме того существует возможность построения альтернативных МСД Di для одной и той же цепи ti.
Все это дает возможность для комбинирования при синтезе исходной популяции. Известно, что для выхода из локальных оптимумов используется механизм смены исходных популяций.
В простейшем случае это можно реализовать с помощью повторной, случайной генерации.
3.3 Генетические операторы
Для получения нового решения (индивидуальности) используются генетические операторы: кроссинговер и мутация.
Кроссинговер заключается во взаимном обмене генами между «родителями» - хромосомами предварительно выбранной пары.
В нашем случае все хромосомы гомологичны, т.к. имеют одну и ту же структуру, одну и ту же длину и несут информацию об одном и том же наборе МСД. Гены, расположенные в одном и том же локусе хромосом, гомологичны, т.к. несут информацию об одном и том же ребре хромосомы.
Предварительно задается величина PK – вероятность кроссинговера и вводится флажок FG с двумя состояниями «выполнять», «не выполнять». Исходное состояние FG «не выполнять». При выполнении кроссинговера последовательно просматриваются локусы выбранной пары хромосом. С вероятностью Pk «флажок» FG переходит в состояние «выполнять». Если FG перешел в состояние «выполнять», то производится обмен генами между парой хромосом в текущем локусе, далее «флажок» переходит в состояние «не выполнять», а затем осуществляется переход к следующему локусу.
Такой алгоритм кроссинговера обеспечивает мультиобмен. Число пар обменивающихся генов определяется параметром Pk.
Операция мутации заключается в изменении значения гена. Алгоритм мутации реализуется следующим образом.
Предварительно, для каждого гена gn, определяется диапазон его возможных значений от 1 до yn, где yn – число сформированных вариантов реализации ребра  .
.
Задается параметр PM – вероятность мутации и «флажок» FG с двумя состояниями «выполнять» и «не выполнять». Исходное состояние FG – «не выполнять».
Последовательно выбираются хромосомы из текущей популяции. В пределах выбранной хромосомы последовательно просматриваются гены. После перехода к очередному гену, FG с вероятностью PM переходит в состояние «выполнять». Если FG перешел в состояние «выполнять», то случайным образом ген gn принимает одно из значений в заданном диапазоне, за исключением значения, которое ген имеет перед мутацией. Далее FG переходит в состояние «не выполнять» и выбирается следующий ген хромосомы, или следующая хромосома.
Для улучшения процесса поиска лучшего решения введем дифференцируемое значение показателя  , принимающего различные значения в зависимости от значения гена.
, принимающего различные значения в зависимости от значения гена.
Введем для гена gn оценку  , где ln – число ребер ui, входящих в маршрут vijk реализующий ребро
, где ln – число ребер ui, входящих в маршрут vijk реализующий ребро  , соответствующее гену gn.
, соответствующее гену gn.  - число таких ui,, входящих в vijk,для которых показатель загрузки ci имеет отрицательное значение.
- число таких ui,, входящих в vijk,для которых показатель загрузки ci имеет отрицательное значение.
Кn меняется от 0 до 1. Чем больше Kn, тем “хуже” маршрут vijk, и тем больше оснований к его смене.
Значение показателя с учетом Кn для гена gn определяется следующим образом

параметр D связан с Pm следующим соотношением
 ,
,
т.е. D меняется от 0 до (1-Pm).
В предельном случае

Как видно из алгоритмов, реализующих процедуры кроссинговера и мутации, временная сложность операторов кроссинговера и мутации применительно к одной хромосоме имеют линейную зависимость,  , где L – длина хромосомы.
, где L – длина хромосомы.
3.4 Общая структура генетического поиска для глобальной
трассировки
В соответствии с методикой описанной выше на первых подготовительных этапах осуществляется разбиение КП на плоскости. Для всех цепей строятся минимальные связывающие деревья. Для всех ребер МСД формируются наборы вариантов реализующих их соединений. Управляющими параметрами генетической адаптации являются: М – размер исходной популяции, Т – число генераций, PK – вероятность кроссинговера, Pm – вероятность мутации.
После сформирования исходной популяции Пи для каждой индивидуальности рассчитывается фитнесс.
Алгоритм расчета фитнесса имеет следующий вид: в качестве исходных данных используется вектор А={al| l=1,2, …}, где al – пропускная способность ребра ul. Для расчета фитнесса используется вектор B, имеющий ту же размерность, что и вектор А. Вначале элементы  имеют нулевое значение. Вектор В служит для учета загрузки ребер Ur всеми цепями.
имеют нулевое значение. Вектор В служит для учета загрузки ребер Ur всеми цепями.
Значения 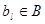 растут последовательно и, после просмотра всех генов, bl является значением числа цепей, проходящих через ul.
растут последовательно и, после просмотра всех генов, bl является значением числа цепей, проходящих через ul.
Имея вектора А и В, рассчитываются значения показателей cl=al-bl для каждого ребра ul. На основании значений cl расcчитываются критерии F1, F2 и F3.
Если учесть, что число вариантов имеет фиксированное значение и обычно, не превышает 4-6, то трудоемкость подсчета вектора В линейна и пропорциональна длине хромосом. Трудоемкость процедуры поиска cmin также линейна. В связи с этим трудоемкость tф расчета фитнесса для одной хромосомы имеет линейную зависимость от длины хромосомы tф~O(L).
После расчета фитнесса для исходной популяции применяется оператор кроссинговера.
Селекция родительских пар хромосом осуществляется либо на основе «принципа рулетки», либо на основе рейтинга популяции.
С этой целью все хромосомы популяции сортируются в соответствии с рассчитанными значениями фитнесса. После этого осуществляется селекция пары родственных хромосом по правилу: i - я с i+1 – ой.
Для каждой новой индивидуальности, образованной в результате кроссинговера, расчитывается фитнесс. После кроссинговера текущая популяция ПТ включает исходную ПИ и популяцию ПК, образовавшуюся в результате выполнения кроссинговера.
ПТ=ПИ+ПК.
Далее ко всем индивидуальнастям ПТ применяется оператор мутации. Для всех индивидуальностей популяции ПМ, образовавшихся в результате мутации расчитывается фитнесс. Заключительным этапом в пределах одного поколения является процесс редукции популяции ПТ=ПИ+ПК+ПМ до размеров ПИ на основе селективного отбора. Селекция осуществляется на основе “принципа рулетки”.
Вероятность выбора индивидуальности определяется как:

С помощью коэффициентов Кi, которые для «лучших» индивидуальностей имеют большие значения, чем у «худших», достигаются увеличение вероятности выбора «лучших» индивидуальностей.
Временная сложность алгоритма определяется общими (подготовительными) затратами to и затратами в пределах каждого поколения td. Общие затраты складываются из затрат на построении минимальных связывающих деревьев td,формирование вариантов реализации ребер tb,и формирования исходной популяции tи: to=td+tb+tи.
Затраты на построение МСД находятся в зависимости от числа МСД. С другой стороны при построении конкретного МСД затраты пропорциональны квадрату числа связываемых вершин. Учитывая, что число ребер n всех МСД пропорционально числу МСД, можно считать, что оценка ВСА tо лежит в пределах О(n)-O(n2), причем чем больше n тем ближе к О(n).
Затраты в пределах поколения tn складываются из затрат на операторы кроссинговера tк, мутации tm,расчета фитнесса tф и селекции tс.
Как уже указывалось выше затраты tк,tм и tф при обработке одной хромосомы имеют линейную зависимость от n. tс имеет линейную зависимость от объема популяции М. Тогда временные затраты в пределах поколения имеют оценку О(n×M). Для Т генераций временная сложность алгоритма имеет оценку О(n×M×T). Учитывая что параметры М и Т сравнимы или значительно меньше n, можно считать, что оценка временной сложности всего алгоритма в целом лежит в пределах О(n2)-O(n3).