Линейная множественная регрессионная модель
На основе предыдущем этапе были изложены причины использования именно линейной модели по каждому фактору.
Тогда для моделирования используем линейную множественную регрессионную модель  для генеральной совокупности.
для генеральной совокупности.
Для выборки модель также линейна:  . В результате отбора факторов найдём наиболее качественную модель.
. В результате отбора факторов найдём наиболее качественную модель.
Найдем объяснённую часть модели - линейное уравнение регрессии по выборке:  . Пока окончательное количество факторов m нам неизвестно.
. Пока окончательное количество факторов m нам неизвестно.
Этап 5 Идентификация
Для построения модели используем классический подход - метод наименьших квадратов МНК.
С помощью Exel проведём расчёты первой модели, с факторами Х1, Х2, Х3, Х4, Х5,Х6. Получим уравнение множественной регрессии и наблюдаемое значение t-критерия для каждого коэффициента регрессии aj:

t набл по модулю: 0,58 4,65 2,76 1,34 1,41 3,34 0,63
Сравним  с табличным на уровне значимости d=0,05 с (n-m-1)=(47-6-1)=40 степенями свободы tтабл=2,02.
с табличным на уровне значимости d=0,05 с (n-m-1)=(47-6-1)=40 степенями свободы tтабл=2,02.
 Так как a0 не статистически значимо, то получаем уравнение:
Так как a0 не статистически значимо, то получаем уравнение:
tнабл по модулю: 0 4,67 3,13 1,26 2 3,54 0,4
Из всех коэффициентом статистически значимыми могут быть признаны коэффициенты при Х1, Х2,Х5.
Коэффициент при Х3 – не может быть признан статистически значимым, поэтому фактор Х3 удаляем из модели. Т.е. несмотря на то, что утечка умов влияет на фундаментальные исследования, но все таки ее влияние не значительно, т. к. наука постоянно развивается, поэтому происходит замена в кадровом составе и им на смену приходят молодые ученые.
Коэффициент при Х4 – не может быть признан статистически значимым, поэтому фактор Х4 удаляем из модели. Т.е. несмотря на то, что качество жизни влияет на фундаментальные исследования, но все таки ее влияние не значительно, т. к. в каждой стране происходят фундаментальные исследования, независимо от качества жизни. И как мы предполагали ранее, Х6 также следует исключить, так как ВВП является не всегда важным показателем развития науки, хотя и влияет на финансовые возможности страны.
Итак, оставляем в модели Х1, Х2, Х5
С помощью Exel проведём расчёты второй модели, с факторами Х1, Х2, Х5. Получим уравнение множественной регрессии и наблюдаемое значение t-критерия для каждого коэффициента регрессии aj:
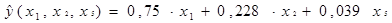 |
tнабл по модулю: 10,39 3,014 3,82
Сравним с табличным на уровне значимости d=0,05 с (n-m-1)=(47-3-1)=43 степенями свободы tтабл=2,02.
Как видим, все коэффициенты получились значимыми.
| У | Х1 | Х2 | Х5 | |
| У | ||||
| Х1 | 0,884148423 | |||
| Х2 | 0,526521959 | 0,533871035 | ||
| Х5 | 0,441017751 | 0,273023712 | -0,045987724 |
Но мультиколлинеарность высокая между факторами Х1 и Х2.
Рассмотрим две модели: Х1, Х5; Х2,Х5
Рассмотрим модель Х1 , Х5:
 |
tнабл по модулю: 44,55 2,94
Сравним  с табличным на уровне значимости d=0,05 с (n-m-1)=(47-2-1)=44 степенями свободы tтабл=2,02.
с табличным на уровне значимости d=0,05 с (n-m-1)=(47-2-1)=44 степенями свободы tтабл=2,02.
Как видим, все коэффициенты получились значимыми.
 |
Fнабл= 1527,72>Fтабл
Рассмотрим модель Х2 Х5:
 |
tнабл по модулю: 24,56 4,69
Сравним с табличным на уровне значимости d=0,05 с (n-m-1)=(47-2-1)=44 степенями свободы tтабл=2,02
Как видим, все коэффициенты получились значимыми.
 | ||
 |
Fнабл=519,0835>Fтабл
Все модели хорошего качества, их все можно использовать для дальнейшего исследования, но по t-критерию фактор Х1 (44,55) выше фактора Х2 (24,56), ошибки аппроксимации в первой модели меньше, чем во второй.
Для дальнейших этапов исследуем первую модель с Х1 , Х5. И при этом практически не изменились по сравнению с первой моделью. Можно сделать вывод:
1) эти факторы действительно являются определяющими и показывают истинную зависимость
2) в модели невелика мультиколлинеарность.
По t-критериям эту модель можно признать наиболее качественной.
Чтобы установить окончательно, так ли это, проверим мультиколлинеарность в ней.
Рассчитаем линейные парные коэффициенты корреляции между Y и каждым фактором, и попарно между всеми факторами. Составим общую корреляционную матрицу:
| У | Х1 | Х5 | |
| У | |||
| Х1 | 0,884 | ||
| Х5 | 0,441 | 0,273 |
Видим, что корреляция между Х1 и Х5 (0,273) крайне слаба, можно сказать, практически отсутствует.
Рассчитаем определитель матрицы межфакторной корреляции:
| Х1 | Х5 | |
| Х1 | ||
| Х5 | 0,273 |

 , это означает, что проблема мультиколлинеарности невелика, можно сказать незначительна.
, это означает, что проблема мультиколлинеарности невелика, можно сказать незначительна.
А также учитывая, что коэффициенты модели оказались устойчивы к изменению модели, можно постановить, что проблема мультиколлинеарности практически не искажает результаты моделирования, и её последствия незначительны.
Можем провести дальнейший анализ модели.
Этап 6 Верификация
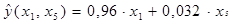 |
Итак, получена модель:
Экономическая интерпретация коэффициентов множественной регрессии
а 1=0,96 – показывает, что при уменьшении развития технологии на 1 ед., увеличивается уровень фундаментальных исследований на 0,96 балла.
а 2=0,032 – показывает, что увеличение общих расходов на НИР на 1 млрд. долл. приведет к увеличению фундаментальных исследований на 0,032 балла.
Доверительные интервалы для параметров множественной регрессии aj:  .
.
При уровне значимости d=5%, используя расчёты Exel, получаем 95%-ные доверительные интервалы:
для a1: (0,913; 1,004), для a2: (0,005; 0,01).
Ширина интервалов маленькая, можно предположить, что точность модели будет хорошей.
Коэффициент детерминации
R2= 0,985
Скорректированный коэффициент детерминации  63 показывает, что изменение числа фундаментальных исследований Y на 96,3% обусловлены совокупным изменением таких факторов, как финансирование развития технологии и технологии и общие расходы на НИР.
63 показывает, что изменение числа фундаментальных исследований Y на 96,3% обусловлены совокупным изменением таких факторов, как финансирование развития технологии и технологии и общие расходы на НИР.
Остальные 3,7% изменений стоимости обусловлены другими факторами, не включёнными в модель или необнаруженными в данном исследовании и случайными.
Средние коэффициенты эластичности
Для линейной регрессии:  .
.
Рассчитаем сначала средние значения:  ,
,  , млрд. долл.,
, млрд. долл.,
 .
.
 | ||
 |
Как видим, эластичность Y по каждому фактору разная. Наиболее сильна эластичность Y по фактору Х1, а по фактору Х5 очень мала.
При увеличении финансирования развития технологии на 1% от среднего балла фундаментального исследования увеличивается на 0,95% от среднего балла фундаментального исследования.
При увеличении общих расходов на НИР на 1% от среднего балла фундаментального исследования в среднем увеличивается на 0,038% от среднего балла фундаментального исследования.
Чтобы достоверно ранжировать факторы по силе влияния на Y найдём уравнение множественной регрессии в стандартизированном масштабе:  .
.
Составляем систему нормальных уравнений в стандартизированном масштабе, чтобы найти стандартизированные коэффициенты регрессии bj:
 |
Подставляем коэффициенты корреляции (они уже вычислены в общей корреляционной матрице):
 |
 Решаем его алгебраическими методами и получаем стандартизированные коэффициенты регрессии:1=0,825, 2=0,216
Решаем его алгебраическими методами и получаем стандартизированные коэффициенты регрессии:1=0,825, 2=0,216
и стандартизированное уравнение:.
 |
, значит, наиболее сильное влияние на фундаментальные исследования Y оказывает фактор Х1 – финансирование развития технологии общие расходы на НИР, менее сильное влияние оказывает фактор Х5 – общие расходы на НИР.
Качество уравнения в целом. Ошибки аппроксимации.
F-критерий.
Табличное значение F-критерия на уровне значимости d=5% с m=3 и с(n-m-1)=47-2-1=44 степенями свободы Fтабл=2,02. Fнабл=1527,72>Fтабл – уравнение в целом статистически значимо и надёжно.
Ошибки аппроксимации
Потребуется сделать дополнительные вычисления -  и просуммировать их:
и просуммировать их:
 | |||||
 | |||||
 |
Отклонения смоделированных данных от реальных составляют в среднем 17,05%. Аппроксимацию можно признать приемлемой. Эта модель применима для прогнозирования.
Этап 7 Прогнозирование
Полученные показатели и выводы позволяют вполне уверенно использовать эту модель для прогнозирования.
Составим прогноз фундаментального исследования (на примере Греции), при финансировании развития технологии = 5,01 общими расходами на НИР в 1,074 млрд. долл. Запрашиваемое фундаментальное исследование в рассматриваемый период составляла 4,43 балла.
Итак, прогнозные значения факторов х1,прог =5,01, х5,прог =1,074.
Точечный прогноз
 |
При заданных прогнозных значениях факторов можно ожидать, что фундаментальные исследования будут колебаться около 4,844 балла.
Интервальный прогноз
Чтобы вычислить интервальные прогнозы нужно рассчитать ошибки прогнозирования, а для этого потребуются дополнительные матричные вычисления.
Составляем матрицу Х, первый столбец – единичный, а остальные столбцы – это статистические данные по факторам, входящим в модель.
Её размерность в этом случае 47 строк и 3 столбца, dimX=47´3.
| Финансирование развития технологии | Общие расходы на НИР | |
| 7,25 | 6,641 | |
| 3,33 | 0,67 | |
| 5,56 | 5,75 | |
| 4,3 | 0,1 | |
| 3,44 | 5,598 | |
| 5,84 | 34,022 | |
| 4,98 | 0,887 | |
| 3,72 | 0,571 | |
| 7,57 | 1,098 | |
| 5,01 | 1,074 | |
| 6,86 | 5,586 | |
| 7,56 | 5,312 | |
| 5,44 | 3,703 | |
| 3,15 | 0,059 | |
| 7,07 | 2,205 | |
| 6,79 | 0,309 | |
| 4,61 | 9,28 | |
| 3,84 | 13,76 | |
| 6,78 | 18,822 | |
| 4,88 | 23,757 | |
| 3,92 | 0,136 | |
| 6,79 | 0,748 | |
| 2,97 | 2,453 | |
| 6,37 | 7,557 | |
| 5,64 | 0,924 | |
| 2,67 | 1,172 | |
| 5,02 | 1,152 | |
| 5,21 | 16,011 | |
| 3,37 | 6,804 | |
| 8,11 | 2,403 | |
| 3,95 | 0,216 | |
| 3,13 | 0,479 | |
| 7,9 | 31,2535 | |
| 5,04 | 0,444 | |
| 6,8 | 7,805 | |
| 4,27 | 1,223 | |
| 4,08 | 0,107 | |
| Финансирование развития технологии | Общие расходы на НИР | |
| 7,61 | 5,655 | |
| 5,55 | 44,283 | |
| 3,21 | 0,429 | |
| 4,69 | 1,366 | |
| 4,41 | 0,616 | |
| 6,92 | 6,324 | |
| 6,9 | 12,02 | |
| 4,33 | 0,103 | |
| 4,78 | 1,563 |
Транспонируем её – ХТ, размерность транспонированной матрицы dimXТ=3´47
Вычисляем матричное произведение ХТХ, его размерность dimXТХ=3´3.

Находим обратную к ней матрицу, её размерность dim(XТХ)-1=3´3:
 |
Для вычисления стандартных ошибок прогнозирования составим матрицу прогнозных значений: хпрог =(1 5,01 1,074).
И вычислим матричное произведение: хпрог (ХТХ)-1 хпрог Т.
 |
размерность dim хпрог (XТХ)-1=1´3.
 |
1) Доверительный интервал для средних значений Y при х1,прог=5,01, х5,прог=1,074.
 .
.
Стандартная ошибка прогноза для средних значений:
 |
Доверительный интервал для средних значений Y с вероятностью g=95%:
 |
С вероятностью 95% можно ожидать, что средние фундаментальные исследования, которые финансируются на развитие технологии на 5,01, и общими расходами на НИР в 1,074 млрд. долл., колебалась в рассматриваемый период от 4, 153 до 5,535.
2) Доверительный интервал для индивидуальных значений Y при х1,прог=5,01, х5,прог=1,074млрд. долл.
. 
Стандартная ошибка прогноза для индивидуальных значений:
 |
Доверительный интервал для индивидуальных значений Y с вероятностью g=95%:
 |
С вероятностью 95% можно ожидать, что средние фундаментальные исследования, которые финансируются на развитие технологии на 5,01, общими расходами на НИР в 1,074 млрд. долл., колебалась в рассматриваемый период от 3, 291 до 6,397.
Модель для прогнозирования пригодна.