Задается в виде кортежа < D, Q, F, R(d,q)>, где
· D – множество представлений документа
· Q – множество представлений информационной потребности (запроса)
· F – средства моделирования представлений документа, запросов и их отношений
· R(d,q) – функция ранжирования
o Ставит в соответствие d из D и q из Q вещественные числа
o Определяет порядок на множестве документов относительно запроса q
Математические модели документального поиска
· Теоретико-множественные (булевская, нечеткие множества, расширенная булевская)
· Вероятностные (сети вывода, энтропийная и др.)
· Алгебраические (векторная, матричная и др.)
Теоретико-множественная модель



b = c = 0:
идеальное качество поиска
Метрики подобия

Булевская модель
· Самая простая модель, основанная на теории множеств
· Запросы представляются в виде булевских выражений из слов и логических операторов И, ИЛИ, НЕ.
· Релевантными считаются документы, которые удовлетворяют булевскому выражению в запросе.


Расширенная булевская модель
· Взамен бинарных величин термины в документах и запросах описываются весовыми коэффициентами (значимость или статистическая оценка)
· Используется аппарат нечетких множеств, т.е. степень принадлежности элемента к множеству задается величиной из интервала [0,1].
· Степень принадлежности элементов может использоваться для ранжирования результатов запроса
Булевские модели: достоинства и недостатки
Достоинства:
· простая, легко понимаемая структура запроса
· простота реализации
Недостатки:
· недостаточно возможностей для описания сложных запросов
· результатов запроса либо слишком много либо слишком мало
· проблематичность при ранжирования результатов
Альтернативные модели
Требуется метрика для описания подобия между запросом и документом. Для этого необходимо привлекать характеристики документов и запроса. Можно предположить, что лингвистическое подобие документа и запроса подразумевает тематическое подобие, т.е. выражает фактически релевантность документа.
Векторная модель

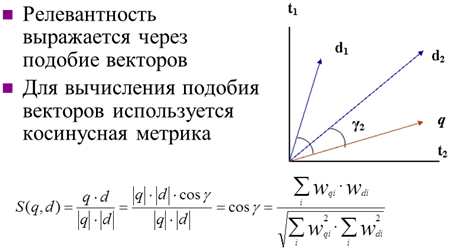
Векторная модель
· Для построения пространства терминов обычно используются основы слов, отдельные слова, а также целые фразы, пары слов и т.д.
· Документы и запросы представляются в виде векторов, компоненты которых соответствуют весам терминов wt.
· Чем больше используется терминов, тем сложнее понять какие подмножества слов являются общими для подобных документов.
Ключевые вопросы:
· Как выбирать размерность пространства терминов N?
· Как вычислять весовые коэффициенты wt?
Закон Ципфа (Zipf)

Принцип Луна (Luhn)

Расчет весов терминов
Бинарные веса:
· Wij =1 если документ di содержит термин tj, иначе 0.
Частота термина tfij, т.е. сколько раз встретился термин tj в документе di
tf x idf:
· чем выше частота термина в документе – тем выше его вес, но
· термин должен не часто встречаться во всей коллекции документов

Векторная модель
Достоинства:
· Учет весов повышает эффективность поиска
· Позволяет оценить степень соответствия документа запросу
· Косинусная метрика удобна при ранжировании
Проблемы:
· Нет достаточного теоретического обоснования для построения пространства терминов
· Поскольку термины не являются независимыми друг от друга, то они не могут быть полностью ортогональными
Имеет преимущество перед другими моделями ввиду простоты и изящества
Вероятностные модели
Заключаются в оценке вероятности того, что документ d является релевантным по отношению к запросу q: Pr(R|d,q).
При ранжировании документов в выборке ключевым являет Принцип Ранжирования Вероятностей, согласно которому если каждый ответ поисковой системы представляет собой ранжированный по убыванию вероятности полезности для пользователя список документов, то общая эффективность системы для пользователей будет наилучшей.