Обработка числовой информации на ЭВМ, как правило, происходит следующим образом. Поскольку исходные данные и результаты записываются в привычной для людей десятичной системе, а ЭВМ работает с двоичными числами, то при вводе числа переводятся в двоичную систему, после чего происходит обработка двоичных чисел, а при выводе результаты переводятся в десятичную систему. При этом на перевод чисел из одной системы в другую, естественно, тратится время. Но если исходных данных и результатов немного, а их обработка данных занимает значительное время, тогда затраты на переводы не очень заметны.
О вещественных числах
В ПК нет команд, реализующих арифметические операции над вещественными числами. Это связано с тем, что аппаратная реализация этих операций - вещь дорогая, а при создании ПК во главу угла всегда ставили дешевизну; поэтому, чтобы сократить стоимость ПК, в его систему команд и не включают команды вещественной арифметики.
Как же тогда работать на ПК с вещественными числами? Возможны два решения данной проблемы.
Во-первых, на основе имеющихся команд можно написать процедуры, реализующие арифметические операции над вещественными числами, и в те места программы, где требуется выполнить операции над вещественными числами, нужно вставить обращения к этим процедурам.
Во-вторых, к ПК можно присоединить специальное устройство - арифметический сопроцессор, который умеет выполнять арифметические операции над вещественными числами. Центральный процессор взаимодействует с этим сопроцессором по следующему сценарию: когда надо выполнить вещественную операцию, центральный процессор посылает сигнал сопроцессору и передает ему соответствующие операнды (в ПК есть специальная команда для этого); сопроцессор выполняет указанную операцию, записывает результат в определенное место и возвращает управление центральному процессору, который после этого продолжает свою работу.
Рассказ про арифметические сопроцессоры - это большая самостоятельная тема, которой мы не будем касаться в данной книге. Поэтому в дальнейшем мы не будем рассматривать вещественные числа и связанные с ними команды ПК и средства языка ассемблера (например, директивы DQ и DT).
Представление символьных данных
Как и любая другая информация, символьные данные должны храниться в памяти ЭВМ в двоичном виде. Для этого каждому символу ставится в соответствие некоторое неотрицательное число, называемое кодом символа, и это число записывается в память ЭВМ в двоичном виде. Конкретное соответствие между символами и их кодами называется системой кодировки.
В ЭВМ, как правило, используются 8-разрядные коды символов. Это позволяет закодировать 256 различных символов, чего вполне достаточно для представления многих символов, используемых на практике. Поэтому для кода символа достаточно выделить в памяти один байт. Так и делают: каждый символ представляется своим кодом, который записывают в один байт памяти.
- В ПК обычно используется система кодировки ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информации).
Что касается машинного представления строк, т. е. последовательностей символов, то под каждую строку отводят нужное число соседних байтов памяти, в которые записывают коды символов, образующих строку. Адрес первого из этих байтов считается адресом строки. Отметим, что эта последовательность кодов записывается в ПК в нормальном, неперевернутом виде. Например, строка 'аbс' будет представлена в памяти так (А - адрес строки):
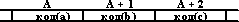
Лекция 4
Тема: Представление команд. Форматы команд.
Содержание: Формат «регистр – регистр». Формат «регистр – память». Формат «регистр – непосредственный операнд». Формат «память – непосредственный операнд».
Краткое содержание лекции:Машинные команды ПК занимают от 1 до б байтов. Код операции (КОП) занимает один или два первых байта команды. В ПК столь много различных операций, что для них не хватает 256 различных кодов, которые можно представить в одном байте. Поэтому некоторые операции объединяются в группу и им дается один и тот же КОП, во втором же байте этот код уточняется. Кроме того, во втором байте указываются типы операндов и способы их адресации. В остальных байтах команды указываются ее операнды. Команды ПК могут иметь от 0 до 2 операндов. Размер операндов - байт или слово (редко - двойное слово). Операнд может быть указан в самой команде (это так называемый непосредственный операнд), либо может находиться в одном из регистров ПК и тогда в команде указывается этот регистр, либо может находиться в ячейке памяти и тогда в команде тем или иным способом указывается адрес этой ячейки. Некоторые команды требуют, чтобы их операнд находился в фиксированном месте (например, в регистре АХ), и тогда операнд явно не указывается в команде. Результат выполнения команды помещается в регистр или ячейку памяти, откуда берется один из операндов. Например, большинство команд с двумя операндами реализуют действие
ор1:= ор1 * ор2,где opl - регистр или ячейка памяти, а ор2 - непосредственный операнд, регистр или ячейка памяти, а * - операция, заданная КОПом. Форматы машинных команд в ПК достаточно разнообразны и "затейливы". Для примера рассмотрим лишь основные форматы команд с двумя операндами.
1) Формат "регистр - регистр" (2 байта): Команды этого формата описывают обычно действие regl:=regl*reg2 или reg2:=reg2*regl, где regl и reg2 - регистры общего назначения. Поле КОП первого байта указывает на операцию (*), которую надо выполнить. Бит w определяет размер операндов, а бит d указывает, в какой из двух регистров записывается результат. Во втором байте два левых бита фиксированы (для данного формата), а трехбитовые поля regl и reg2 указывают на регистры, участвующие в операции.
2) Формат "регистр - память" (2-4 байта): Эти команды описывают операции reg:= reg * adr или adr:= adr * reg, где reg - регистр, a adr - адрес ячейки памяти. Бит w первого байта определяет размер операндов (см. выше), а бит d указывает, куда записывается результат: в регистр (d = l) или в ячейку памяти (d = 0). Трехбитовое поле reg второго байта указывает операнд-регистр (см. выше), двухбитовое поле mod определяет, сколько байтов в команде занимает операнд-адрес (00 - 0 байтов, 01-1 байт, 10 - 2 байта), а трехбитовое поле mem указывает способ модификации этого адреса. В следующей таблице указаны правила вычисления исполнительного адреса в зависимости от значений полей mod и mem (а8 - адрес размером в байт, а16 - размером в слово, [r] - содержимое регистра.
3) Формат "регистр - непосредственный операнд" (3-4 байта): Команды этого формата описывают операции reg:= reg * im (im - непосредственный операнд). Бит w указывает на размер операндов, а поле reg - на регистр-операнд (см. выше). Поле КОП в первом байте определяет лишь группу операций, в которую входит операция данной команды, уточняет же операцию поле КОП' из второго байта. Непосредственный операнд может занимать 1 или 2 байта (в зависимости от значения бита w), при этом операнд размером в слово I записывается в команде в "перевернутом" виде. Ради экономии памяти в ПК предусмотрен случай, когда в операции над словами непосредственный операнд может быть задан байтом (на это указывает 1 в бите s при w=l), и тогда перед выполнением операции байт автоматически расширяется до слова. 4) Формат "память - непосредственный операнд" (3-6 байтов): Команды этого формата описывают операции типа adr:= adr * im. Смысл всех полей - тот же, что и в предыдущих форматах.
Лекция 5.
Тема: Основные элементы языка Ассемблер.
Содержание: Лексемы. Идентификаторы. Целые числа. Предложения. Комментарии. Команды. Директивы. Ссылки назад и вперед. Директивы определения данных. Директива DB. Директива DW. Директива DD. Директивы эквивалентности и присваивания. Выражения. Константные выражения. Адресные выражения.
Краткое содержание лекции:
Программировать на машинном языке сложно. Одна из причин этого - цифровая форма записи команд и данных, для людей более привычны символьные обозначения. И уже давно придумали средство, упрощающее составление машинных программ. Это язык ассемблера (другое название - автокод), представляющий собой фактически символьную форму записи машинного языка: в нем вместо цифровых кодов операций выписывают привычные знаки операций или их словесные названия, вместо адресов - имена, а константы записывают в десятичной системе. Программу, записанную в таком виде, вводят в ЭВМ и подают на вход специальному транслятору, называемому ассемблером, который переводит ее на машинный язык, и далее полученную машинную программу выполняют.
Лексемы
Изучение ЯА начнем с рассказа о том, как в нем записываются лексемы - такие простейшие конструкции, как имена, числа и строки.
Идентификаторы
Идентификаторы нужны для обозначения различных объектов программы - переменных, меток, названий операций и т. п.
В ЯА идентификатор - это последовательность из латинских букв (больших и малых), цифр и следующих знаков:
?. @ _ $
Причем на эту последовательность накладываются следующие ограничения:
- длина идентификатора может быть любой, но значащими являются только первые 31 символ (идентификаторы, отличающиеся только в 32-й и последующих позициях, считаются одинаковыми);
- идентификатор не должен начинаться с цифры (7А - ошибка);
- точка может быть только первым символом идентификатора (.А - можно,А. - нельзя);
- в идентификаторах одноименные большие и малые буквы считаются эквивалентными (АХ, Ах, аХ и ах - одно и то же);
Особо подчеркнем, что в идентификаторах нельзя использовать буквы русского алфавита.
Идентификаторы делятся на служебные слова и имена. Служебные слова имеют заранее определенный смысл, они используются для обозначения таких объектов, как регистры (АХ, SI и т. п.), названия команд (ADD, NEG и т. п.) и т. п. Все остальные идентификаторы называются именами, программист может пользоваться ими по своему усмотрению, обозначая ими переменные, метки и другие объекты программы.
В качестве имен вообще-то можно использовать и некоторые служебные слова, однако настоятельно не рекомендуется этого делать.
Целые числа
В ЯА имеются средства записи целых и вещественных чисел. Но как уже было сказано вещественные числа мы не рассматриваем, поэтому здесь рассматриваются только целые числа.
Целые числа могут быть записаны в десятичной, двоичной, восьмиричной и шестнадцатеричной системах счисления (другие системы не допускаются). Примеры:

.
Если такое число начинается с "буквенной" цифры (A-F), например A5h, тогда становится непонятным, что означает эта запись - число или идентификатор. Чтобы не было путаницы, вводится следующее требование: если шестнадцатеричное число начинается с цифры A-F, то в начале числа обязательно должен быть записан хотя бы один незначащий ноль:
OA5h - число, A5h - идентификатор
Символьные данные
Символы заключаются либо в одинарные, либо в двойные кавычки: 'А' или "А". Естественно, левая и правая кавычки должны быть одинаковыми: 'В" или "В' - ошибка.
Строки (последовательности символов) также заключаются либо в одинарные, либо в двойные кавычки: 'А+b' или "А+В".
Теперь кое-что уточним:
в качестве символов можно использовать русские буквы;
- в строках одноименные большие и малые буквы не отождествляются ('А+В' и 'а + b' - разные строки);
- если в качестве символа или внутри строки надо указать кавычку, то делается это так: если символ или строка заключена в одинарные кавычки, то одинарную кавычку надо удваивать, а вот двойную кавычку не надо удваивать, и наоборот, если внешние кавычки двойные, то двойная кавычка должна удваиваться, а одинарная не удваивается:
'don''t' 'don"t' "don't" "don""t"
Собственно ради того, чтобы не удваивать внутренние кавычки, в язык и введены два вида кавычек, ограничивающих символы и строки.
Предложения
Программа на ЯА - это последовательность предложений, каждое из которых записывается в отдельной строке:
<предложение>
<предложение>
…
<предложение>
Переносить предложение на следующую строку или записывать в одной строке два предложения нельзя. Если в предложении более 131 символа, то 132-й и все последующие символы игнорируются.
При записи предложений действуют следующие правила расстановки пробелов:
- пробел обязателен между рядом стоящими идентификаторами и/или числами (чтобы отделить их друг от друга);
- внутри идентификаторов и чисел пробелы недопустимы;
- в остальных местах пробелы можно ставить или не ставить;
- там, где допустим один пробел, можно ставить любое число пробелов.
Эти правила не относятся к пробелам внутри строк, где пробел - обычный значащий символ.
- По смыслу все предложения ЯА делятся на три группы:
- комментарии,
- команды,
- директивы (приказы ассемблеру).
Рассмотрим каждый из этих типов предложений.
Комментарии
Комментарии не влияют на смысл программы, при трансляции ассемблер игнорирует их. Они предназначены для людей, они поясняют смысл программы.
Комментарием считается любая строка, начинающаяся со знака "точка с запятой" (перед ним может быть любое число пробелов) либо пустая строка (точнее, строка, в которой нет иных символов, кроме пробелов). В комментариях можно использовать любые символы, в том числе и русские буквы.
Например, комментариями являются 1-я и 3-я строки в следующем тексте:
;это комментарий
ADD AX,О
MOV ВХ,2
Предложения-комментарии обычно используются для пояснения не одной команды (это можно сделать, как увидим, в самой команде), а целой группы команд, следующих за этим комментарием:
;вычисление С=НОД(А,В)
…
Пустые же строки обычно используются для того, чтобы отделить одну часть программы от другой, чтобы сделать нагляднее деление программы на части.
Отметим, что в ЯА допустим и многострочный комментарий. Он должен начинаться со строчки
COMMENT <маркер> <текст>
(COMMENT - это одна из директив ЯА). В качестве маркера берется первый за словом COMMENT символ, отличный от пробела; этот символ начинает комментарий. Концом такого комментария считается конец первой из последующих строк программы, в которой (в любой позиции) снова встретился этот же маркер. Например:
COMMENT * все
это является комментарием * и это тоже
Такой вид комментария обычно используется, когда надо (например, при отладке) временно исключить из программы некоторый ее фрагмент.
Команды
Предложения-команды - это символьная форма записи машинных команд. Общий синтаксис этого типа предложений таков:
[< метка >:] < мнемокод > [< операнды >] [;< комментарий >]
Примеры:
LAB: ADD SI,2;изменение индекса
NEC A
CBW
Метка
Синтаксически, метка - это имя. Если метка есть, то после нее обязательно ставится двоеточие.
Метка нужна для ссылок на команду из других мест программы, например, для перехода на эту команду. В отличие от машинного языка, где надо высчитывать адреса ячеек, в которые попадают команды, чтобы затем указывать эти адреса в командах перехода, в ЯА достаточно лишь пометить команду и затем ссылаться на нее по метке.
В ЯА разрешается в одной строке указывать только метку (с двоеточием) и больше ничего. Такая метка, считается, метит следующую команду программы. Эта возможность полезна, по крайней мере, в двух случаях: когда команду надо пометить двумя или более метками и когда метка очень длинная и потому остальная часть команды слишком сильно сдвигается вправо, что плохо смотрится.
Пример:
INITIALIZATION: LAB: ADD BX,AX
Мнемокод
Мнемокод (мнемонический код) является обязательной частью команды. Это служебное слово, указывающее в символьной форме операцию, которую должна выполнить команда. В ЯА не используются цифровые коды операций, операции указываются только своими символьными названиями, которые, конечно, легче запомнить (слово "мнемонический" означает "легко запоминающийся").
Сами мнемокоды мы будем рассматривать по ходу дела, при описании команд.
Операнды
Операнды команды, если они есть, отделяются друг от друга запятыми. Операнды обычно записываются в виде выражений, о которых мы еще будет говорить. Пока лишь отметим, что частными случаями выражений являются числа и имена переменных. В отличие от машинного языка, в ЯА в командах не указываются адреса ячеек и, чтобы сослаться на какую-то переменную (ячейку), ей дают имя, а затем в командах указывают это имя.
Комментарий
В конце команды можно поместить комментарий, для чего надо поставить точку с запятой и выписать за ней любой текст, который и будет рассматриваться как комментарий. Такой комментарий, в отличие от комментариев-предложений, обычно используется для пояснения именно данной команды.
Лекция 6
Тема: Директивы определения данных.
Содержание: Директива DB. Директива DW. Директива DD. Директивы. Ссылки назад и вперед. Директивы орпеделения данных. Директива DB. Директива DW. Директива DD. Директивы эквивалентности и присваивания. Выражения. Константные выражения. Адресные выражения.
Краткое содержание лекции:
Для описания переменных, с которыми работает программа, в ЯА используются директивы определения данных. Одна из них предназначена для описания данных размером в байт, вторая - для описания данных размером в слово, а третья - для описания данных размером в двойное слово. В остальном эти директивы практически не отличаются друг от друга.
Директива DB
По директиве DB (define byte, определить байт) определяются данные размером в байт. Ее синтаксис (без учета возможного комментария в конце) таков:
[< имя >] DB < операнд > {,< операнд >}
Встречая такую директиву, ассемблер вычисляет операнды и записывает их значения в последовательные байты памяти. Первому из этих байтов дается указанное имя, по которому на этот байт можно ссылаться из других мест программы.
Существует два основных способа задания операндов директивы DB:
- ? (знак неопределенного значения),
- константное выражение со значением от -128 до 255.
Остальные способы задания операндов производны от этих двух.
Операнд?
Возможный пример:
х DB?
По этой директиве описывается переменная X. Для нее отводится один байт памяти, в который ничего не записывается (в этом байте будет то, что остаюсь от предыдущей программы, и предугадать, что там находится, нельзя). В этом случае говорят, что переменная не получает начального значения.
Где отводится этот байт? Транслируя программу, ассемблер просматривает предложение за предложением и размещает соответствующие им машинные представления в последовательных ячейках памяти. Поэтому, встречая директиву DB, он отводит под указанную переменную первый из еще не занятых байтов памяти. Это следует учитывать и, например, не надо вставлять директиву DB между командами.
Выделив байт под переменную, ассемблер запоминает его адрес. Когда он снова встретит в тексте программы имя этой переменной, то он заменит его на данный адрес (в этой замене и заключается трансляция имен). Таким образом, в отличие от машинного языка, в ЯА уже не надо следить за адресами ячеек, в которых размещаются переменные, а достаточно дать переменным имена и затем ссылаться на них по этим именам, все остальное сделает за нас ассемблер.
Адрес ячейки, выделенной переменной с именем X, принято называть значением имени X (не путать с содержимым ячейки по этому адресу!). Кроме того, по описанию переменной ассемблер запоминает, сколько байтов занимает переменная в памяти. Этот размер называется типом имени переменной. Значение (адрес) и тип (размер) имени переменной однозначно определяют ячейку, обозначаемую этим именем. Напомним, что с одного и того же адреса в ПК могут начинаться ячейки разных размеров - и байт, и слово, и двойное слово, поэтому кроме начального адреса ячейки надо знать и ее размер. В связи с этим ассемблер запоминает как адрес переменной, так и ее размер.
Выражения. Операнды директив, как правило, описываются в виде выражений. Выражения используются и для описания операндов команд. В целом выражения ЯА похожи на арифметические выражения языка высокого уровня, однако между ними есть и отличия. Наиболее важное отличие заключается в том, что выражения ЯА вычисляются не во время выполнения программы, а во время ее трансляции: встретив в тексте программы выражение, ассемблер вычисляет его и полученное значение (например, число) записывает в машинную программу. Поэтому, когда программа начнет выполняться, от выражений не останется никаких следов. В связи с этим в выражениях ЯА можно использовать только такие величины, которые известны на этапе трансляции (например, адреса и типы имен), и ни в коем случае нельзя использовать величины (например, содержимое регистров или ячеек памяти), которые станут известными лишь во время счета программы. Вообще говоря, в ЯА для записи операндов директив и команд достаточно только чисел и имен. Более сложные выражения являются лишь удобной формой записи этих чисел и имен. Например, если имеется переменная X размером в слово и нужно описать переменную ТХ, начальным значением которой является тип (размер) этой переменной, то вместо директивы
TX DB 2 лучше использовать эквивалентную ей директиву
РХ DB TYPE X поскольку она более универсальна и ее не надо менять, если изменится тип временной X. В ЯА выражения делятся на два класса - на константные и адресные, в зависимости от типа их значений. Если значением выражения является целое число, оно называется константным выражением, а если значением является адрес, того адресное выражение. Конечно, адрес - это тоже целое число (порядковый номер ячейки в памяти), но по смыслу адреса отличаются от просто чисел, и в ЯА они рассматриваются как самостоятельный тип данных. По структуре и назначению выражения, константные и адресные, можно разлить на простейшие выражения и операторы. Из простейших выражений строятся любые другие выражения. К простейшим выражениям относятся числа, имена констант, имена переменных и т. п. Термином "оператор" в ЯА принято обозначать, что мы обычно называем функциями и операциями. Операторы ЯА делятся одноместные1 (это аналог функций одного аргумента) и двухместные (это аналог парных операций); примером может служить TYPE X или А+1. С помощью операторов из простейших выражений строятся более сложные выражения. С простейшими выражениями и операторами мы будем знакомиться по ходу дела. Однако уже сейчас укажем старшинство всех операторов ЯА (в порядке убывания; в каждой строке указаны операторы одного старшинства):
1. (), [], LENGTH, SIZE, WIDTH, MASK
2..
3.:
4. PTR, OFFSET, SEG, TYPE, THIS
5. HIGH, LOW
6. одноместные + и -
7. *, /, MOD, SHL, SHR
8. двухместные + и -
9. EQ, NE, LT, LE, GT, GE
10. NOT
11. AND
12. OR, XOR
13. SHORT,.TYPE
Константные выражения
Значениями константных выражений всегда являются 16-битовые целые числа (единственным исключением является директива DD, в которой можно явно указывать 32-битовые числа). При этом, если значением (в математическом смысле) константного выражения является отрицательное число, то в формируемую машинную программу оно записывается в дополнительном коде.
К простейшим константным выражениям относятся:
- число от -215 до 216-1 (числа вне этого диапазона рассматриваются как ошибка);
- символ;
- строка из двух символов;
- имя константы.
Адресные выражения
Значениями адресных выражений являются 16-битовые адреса. Все операции над адресами выполняются по модулю 216 (l0000h). К простейшим адресным выражениям относятся:
- метка (имя команды) и имя переменной, описанное в директиве DB, DW или DD;
- счетчик размещения;
Литература:
1. Пильщиков В.Н. Программирование на языке ассемблера IBM РС. – М.: «Диалог - МИФИ», 1999 – 288с.
2. Лямин Л.В. Макроассемлер МАSM. – М.: Радио и связь, 1994. – 320с.
3. Брэдли Д. Программирование на языке ассемблера для персональной ЭВМ фирмы IBM: Пер. с англ. – М.: Радио и связь, 1988. – 448 с.
Лекция 7.
Тема: Команды. ПЕРЕСЫЛКИ. АРИФМЕТИЧЕСКИЕ КОМАНДЫ
Содержание: Обозначение операндов команд. Команды пресылки. Команда MOV. Оператор указания типа. Команда XCHG. Команды сложения и вычитания. Особенности сложения и вычитания целых чисел в ПК. Команды сложения и вычитания. Команды умножения и деления. Команды умножения. Команды деления. Изменение размеров числа. Примеры
Краткое содержание лекции:
Мы переходим к изучению команд ПК и способов их записи в ЯА. В данной главе будут рассмотрены команды пересылки и арифметические команды.