Цель лекции: изучить построение функции хеширования и алгоритмов хеширования данных и научиться разрабатывать алгоритмы открытого и закрытого хеширования при решении задач на языке C++.
Процесс поиска данных в больших объемах информации сопряжен с временными затратами, которые обусловлены необходимостью просмотра и сравнения с ключом поиска значительного числа элементов. Сокращение поиска возможно осуществить путем локализации области просмотра. Например, отсортировать данные по ключу поиска, разбить на непересекающиеся блоки по некоторому групповому признаку или поставить в соответствие реальным данным некий код, который упростит процедуру поиска.
До сих пор рассматривались способы поиска в таблице по ключам, позволяющим однозначно идентифицировать запись. Такие ключи называются первичными. Возможен вариант организации таблицы, при котором отдельный ключ не позволяет однозначно идентифицировать запись. Такая ситуация часто встречается в базах данных. Идентификация записи осуществляется по некоторой совокупности ключей. Ключи, не позволяющие однозначно идентифицировать запись в таблице, называются вторичными ключами. Даже при наличии первичного ключа, для поиска записи могут быть использованы вторичные.
Идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM в январе 1953 г. с предложением использовать для разрешения коллизий метод цепочек. Примерно в это же время другой сотрудник IBM, Жини Амдал, высказала идею использования открытой линейной адресации. В открытой печати хеширование впервые было описано Арнольдом Думи (1956 год), указавшим, что в качестве хеш-адреса удобно использовать остаток от деления на простое число. А. Думи описывал метод цепочек для разрешения коллизий, но не говорил об открытой адресации. Подход к хешированию, отличный от метода цепочек, был предложен А.П. Ершовым (1957 год), который разработал и описал метод линейной открытой адресации.
В настоящее время используется широко распространенный метод обеспечения быстрого доступа к информации, хранящейся во внешней памяти – хеширование.
1. В настоящее время используется широко распространенный метод обеспечения быстрого доступа к большим объемам информации – хеширование.
2. Для установления соответствия ключей и данных строится хеш-таблица.
3. Хеш-таблица строится при помощи хеш-функций. Практическое применение получили функции прямого доступа, остатков от деления, середины квадрата, свертки.
4. При построении хеш-таблиц могут возникать коллизии, то есть ситуации неоднозначного соответствия данных ключу.
5. Разрешение коллизий проводится методом цепочек (открытое или внешнее хеширование) или методом открытой адресации (закрытое хеширование).
6. Поиск свободных ключей в методе открытой адресации может проводиться методом повторного хеширования с помощью линейного опробования, квадратичного опробования или двойного хеширования.
7. Идентификация данных в таблицах может осуществляться как по первичному, так и по вторичному ключу.
8. Хеширование имеет широкое практическое применение в теории баз данных, кодировании, банковском деле, криптографии и других областях.
Хеширование (или хэширование, англ. hashing) – это преобразование входного массива данных определенного типа и произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свертки, а их результаты называют хешем, хеш-кодом, хеш-таблицей или дайджестом сообщения (англ. message digest).
Словарь (ассоциативный массив, associative array, map, dictionary) – структура данных (контейнер) для хранения пар вида «ключ – значение» (key – value)
§ Реализации словарей отличаются вычислительной сложностью операций добавления (Add), поиска (Lookup)
и удаления элементов (Delete)
§ Наибольшее распространение получили следующие реализации:
1. Деревья поиска (search trees)
2. Хэш-таблицы (hash tables)
3. Списки с пропусками
4. Связные списки
5. Массивы
Хеш-таблица – это структура данных, реализующая интерфейс ассоциативного массива, то есть она позволяет хранить пары вида " ключ - значение " и выполнять три операции в среднем за время О (1): операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу.
Ключи могут быть строками, числами, указателями, …
Хеш-таблица является массивом, формируемым в определенном порядке хеш-функцией.
Хорошей, с точки зрения практического применения, является такая хеш-функция, которая удовлетворяет следующим условиям:
1. функция должна быть простой с вычислительной точки зрения;
2. функция должна распределять ключи в хеш-таблице наиболее равномерно;
3. функция не должна отображать какую-либо связь между значениями ключей в связь между значениями адресов;
4. функция должна минимизировать число коллизий – то есть ситуаций, когда разным ключам соответствует одно значение хеш-функции (ключи в этом случае называются синонимами).
При этом первое свойство хорошей хеш-функции зависит от характеристик компьютера, а второе – от значений данных.
Если бы все данные были случайными, то хеш-функции были бы очень простые (например, несколько битов ключа). Однако на практике случайные данные встречаются достаточно редко, и приходится создавать функцию, которая зависела бы от всего ключа. Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай – когда все ключи хешируются в один индекс.
При возникновении коллизий необходимо найти новое место для хранения ключей, претендующих на одну и ту же ячейку хеш-таблицы. Причем, если коллизии допускаются, то их количество необходимо минимизировать. В некоторых специальных случаях удается избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую инъективную хеш-функцию, которая распределит их по ячейкам хеш-таблицы без коллизий. Хеш-таблицы, использующие подобные хеш-функции, не нуждаются в механизме разрешения коллизий, и называются хеш-таблицами с прямой адресацией.
Хеш-таблицы должны соответствовать следующим свойствам.
- Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение является индексом в исходном массиве.
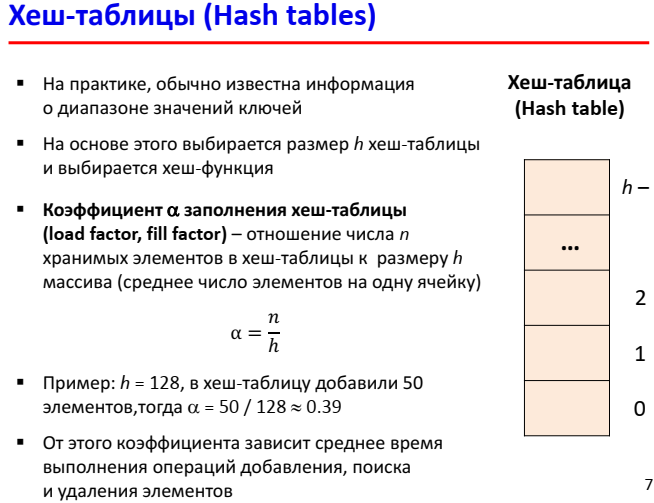
- Количество хранимых элементов массива, деленное на число возможных значений хеш-функции, называется коэффициентом заполнения хеш-таблицы (load factor) и является важным параметром, от которого зависит среднее время выполнения операций.
- Операции поиска, вставки и удаления должны выполняться в среднем за время O(1). Однако при такой оценке не учитываются возможные аппаратные затраты на перестройку индекса хеш-таблицы, связанную с увеличением значения размера массива и добавлением в хеш-таблицу новой пары.
- Механизм разрешения коллизий является важной составляющей любой хеш-таблицы.

Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров, где они повышают скорость обработки таблицы идентификаторов. В качестве использования хеширования в повседневной жизни можно привести примеры распределение книг в библиотеке по тематическим каталогам, упорядочивание в словарях по первым буквам слов, шифрование специальностей в вузах и т.д.