SADT (Structured Analysis and Design Technique) – одна из известных методологий структурного анализа и проектирования систем, введенная Россом в 1973 г.
SADT – это совокупность графического языка и формальных правил описания систем.
С точки зрения SADT модель может основываться либо на функциях системы либо на ее предметах (объектах, данных, информации и т.д.).
Полная методология SADT заключается в построении моделей двух типов (функциональной (активностной) модели и модели данных) для более полного описания сложной системы.
В рамках программы интегрированной компьютеризации производства ICAM на базе SADT была разработана и доведена до уровня стандарта методология IDEF (ICAM DEFinition).
IDEF состоит из трех методологий моделирования, основанных на графическом представлении производственных систем:
· IDEF0 – для создания функциональной модели (структурированное изображение функций производственной системы, информации и объектов, связывающих эти функции);
· IDEF1 – для построения информационной модели (представление структуры информации, необходимой для поддержки функций производственной системы);
· IDEF2 – для построения динамической модели меняющегося во времени поведения функций, информации и ресурсов производственной системы.
Модель IDEF0 представляет собой серию диаграмм с сопроводительной документацией (текст и глоссарий), разбивающих сложный объект на составные части посредством декомпозиции блоков родительской диаграммы.
В состав диаграммы входят блоки, изображающие функции системы и дуги, связывающие блоки вместе, и изображающие взаимодействия и взаимосвязи между блоками.
Создание функциональной модели предполагает осуществление сбора информации в процессе обследования предметной области через (анкетирование, сбор документов, интервьюирование), определение цели моделирования и точки зрения, с которой будет проводиться моделирование.
Целью служит набор вопросов, на которые должна ответить модель. Это то, ради чего создается модель: повышение производительности, улучшение качества образования, повышение прибыли, увеличение числа продаж и т.д.
Цель формулируется в неопределенной форме (идентифицировать, описать, повысить).
Точка зрения – позиция, с которой описывается модель.
Точка зрения должна быть одна: руководитель предприятия, руководитель отдела и т.д.
Диаграммы потоков данных (DFD – Data Flow Diagramming) являются средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных.
Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
Примечание: Наличие в диаграммах DFD элементов для описания источников, приемников и хранилищ данных позволяет более эффективно и наглядно описать процесс документооборота.
В нашем случае мы будем использовать именно эту нотацию, поскольку в рамки рассматриваемой задачи входит изучение документооборота, сопровождающего конкретный процесс.
Основные символы DFD и их графическое обозначение представлены в таблице.
| Основные символы DFD | |
| Название символа и назначение | Обозначение (нотация Гейна-Сарсона) |
| Поток данных | 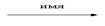
|
| Процесс | 
|
| Хранилище (накопитель) данных | 
|
| Внешняя сущность | 
|
Создаются DFD традиционно с использованием одной из двух нотаций Йодана (Yourdon) или Гейна-Сарсона (Gane-Sarson). В дальнейшем мы будем придерживаться нотации, предложенной Гейном-Сарсоном.
Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации.
Для моделирования информации, которая движется в одном направлении, обрабатывается и возвращается назад к источнику, можно использовать либо два различных потока, либо один - двунаправленный.
Назначение процесса состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым его именем. Оно должно содержать глагол в неопределенной форме с последующим дополнением (например, вычислить максимальную высоту). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы. В целях получения уникального индекса процесса во всей модели этот номер нужно использовать совместно с номером диаграммы.
Хранилище (накопитель) данных позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет «срезы» потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда структура потока данных, входящего или выходящего в/из хранилища, соответствует структуре хранилища, имя потока данных может быть опущено, т.е не отражаться на диаграмме. В общем случае хранилище является прообразом будущей базы данных и описание хранящихся в нем данных должно быть увязано с информационной моделью.
Внешняя сущность представляет сущность вне контекста системы (за границами системы), являющуюся источником или приемником системных данных. Предполагается, что объекты, представленные такими узлами, не должны участвовать ни в какой обработке. Имя внешней сущности должно содержать существительное, например, склад товаров.
Важную специфическую роль в модели играет специальный вид DFD - контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также единственный процесс, изображающий систему в целом.
Основная цель данной диаграммы состоит в установлении границ анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса.
DFD первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме. Она показывает, как система обрабатывает события. На данной диаграмме помимо процессов и потоков данных, их связывающих, добавлены хранилища с целью отражения данных, которые запоминаются по мере выполнения тех или иных событий. Каждый из процессов может быть декомпозирован в DFD нижнего уровня. Декомпозиция продолжается до тех пор, пока процессы не будут представлять элементарные действия по работе с данными системы, которые могут быть эффективно описаны с помощью коротких (до одной страницы) миниспецификаций обработки (спецификаций процессов). Таким образом, строится иерархия DFD с контекстной диаграммой в корне дерева.
В целях создания более ясных и понятных требований посредством иерархического множества DFD, следует руководствоваться представленными ниже рекомендациями:
· не загромождать диаграммы несущественными на данном уровне деталями;
· декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов;
· выбирать ясные, отражающие суть дела, имена процессов и потоков, при этом стараться не использовать аббревиатуры;
· однократно определять функционально идентичные процессы на самом верхнем уровне, где такой процесс необходим, и ссылаться к нему на нижних уровнях;
· отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
1. Расчленение множества требований и организация их в основные функциональные группы.
2. Идентификация внешних объектов, с которыми система должна быть связана.
3. Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
4. Предварительная разработка контекстной диаграммы, на которой основные функциональные группы представляются процессами, внешние объекты – внешними сущностями, основные виды информации – потоками данных между процессами и внешними сущностями.
5. Изучение предварительной контекстной диаграммы и внесение в нее изменений.
6. Построение контекстной диаграммы путем объединения всех процессов предварительной диаграммы в один процесс, а также группировка потоков.
7. Формирование DFD первого уровня на базе процессов предварительной контекстной диаграммы.
8. Проверка основных требований по DFD первого уровня.
9. Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или спецификации процесса.
10. Проверка основных требований по DFD соответствующего уровня.
11. Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
12. Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные. Идентификация процессов или спецификаций процессов, соответствующих этим требованиям.
13. Построение спецификации процесса (а не простейшей диаграммы) в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.