It is possible to compress many types of digital data in a way which reduces the amount of information stored, and consequently the size of a computer file needed to store it or the bandwidth needed to stream it, with no loss of information. Take, for example, a picture. It is converted to a digital file by considering it to be an array of dots, and specifying the colour and brightness of each dot. If the picture contains an area of the same colour, it can be compressed without loss by saying "200 red dots" instead of "red dot, red dot,...(197 more times)..., red dot".
The original contains a certain amount of information; there is a lower limit to the size of file that can carry all the information. As an intuitive example, most people know that a compressed ZIP file is smaller than the original file; but repeatedly compressing the file will not reduce the size to nothing.
In many cases files or data streams contain more information than is needed. For example, a picture may have more detail than the eye can distinguish when reproduced at the largest size intended; an audio file does not need a lot of fine detail during a very loud passage. Developing lossy compression techniques as closely matched to human perception as possible is a complex task. In some cases the ideal is a file which provides exactly the same perception as the original, with as much digital information as possible removed; in other cases perceptible loss of quality is considered a valid trade-off for the reduced data size.
JPEG compression
The compression method is usually lossy, meaning that some original image information is lost and cannot be restored (possibly affecting image quality.) There are variations on the standard baseline JPEG that are lossless; however, these are not widely supported.
There is also an interlaced "Progressive JPEG" format, in which data is compressed in multiple passes of progressively higher detail. This is ideal for large images that will be displayed while downloading over a slow connection, allowing a reasonable preview after receiving only a portion of the data. However, progressive JPEGs are not as widely supported, and even some software which does support them (such as some versions of Internet Explorer) only displays the image once it has been completely downloaded.
There are also many medical imaging systems that create and process 12-bit JPEG images. The 12-bit JPEG format has been part of the JPEG specification for some time, but again, this format is not as widely supported.
JPEG stands for Joint Photographic Experts Group, which is a standardization committee. It also stands for the compression algorithm that was invented by this committee.
There are two JPEG compression algorithms: the oldest one is simply referred to as ‘JPEG’ within this page. The newer JPEG 2000 algorithm is discussed on a separate page. Please note that you have to make a distinction between the JPEG compression algorithm, which is discussed on this page, and the corresponding JFIF file format, which many people refer to as JPEG files and which is discussed in the file format section.
JPEG is a lossy compression algorithm that has been conceived to reduce the file size of natural, photographic-like true-color images as much as possible without affecting the quality of the image as experienced by the human sensory engine. We perceive small changes in brightness more readily than we do small changes in color. It is this aspect of our perception that JPEG compression exploits in an effort to reduce the file size
How JPEG works
The JPEG algorithms performs its compression in four phases:
- First, the JPEG algorithms first cuts up an image in separate blocks of 8×8 pixels. The compression algorithm is calculated for each separate block, which explains why these blocks or groups of blocks become visible when too much compression is applied.
Humans are more sensitive to changes in hue (chrominance) than changes in brightness (luminance). The JPEG algorithm is based on this difference in perception. It does not analyse RGB or CMYK color values but instead the image data are first converted to a luminance/chrominance color space, such as YUV. This allows for separate compression of these two factors. Since luminance is more important than chrominance for our visual system, the algorithm retains more of the luminance in the compressed file. - The next step in the compression process is to apply a Discrete Cosine Transform (DCT) for the entire block. DCT is a complex process that is let loose on each individual pixel. It replaces actual color data for each pixel for values that are relative to the average of the entire matrix that is being analysed. This operation does not compress the file, it simply replaces 8×8 pixel values by an 8×8 matrix of DCT coefficients.
- Once this is done, the actual compression can start. First the compression software looks at the JPEG image quality the user requested (e.g. Photoshop settings like ‘low quality’, ‘medium quality’,…) and calculates two tables of quantization constants, one for luminance and one for chrominance. Once these tables have been constructed, the constants from the two tables are used to quantize the DCT coefficients. Each DCT coefficient is divided by its corresponding constant in the quantization table and rounded off to the nearest integer. The result of quantizing the DCT coefficients is that smaller, unimportant coefficients will be replaced by zeros and larger coefficients will lose precision. It is this rounding-off that causes a loss in image quality.
- The resulting data are a list of streamlined DCT coefficients. The last step in the process is to compress these coefficients using either a Huffman or arithmetic encoding scheme. Usually Huffman encoding is used. This is a second (lossless) compression that is applied.
Advantages
By putting 2 compression algorithms on top of each other, JPEG achieves remarkable compression ratios. Even for prepress use, you can easily compress a file to one fifth of its original size. For web publishing or e-mail exchange, even better ratios up to 20-to-1 can be achieved.
JPEG decompression is supported in PostScript level 2 and 3 RIPs. This means that smaller files can be sent across the network to the RIP which frees the sending station faster, minimizes overhead on the print server and speeds up the RIP.
Disadvantages
The downside of JPEG compression is that the algorithm is only designed for continuous tone images (remember that the P in JPEG stands for Photographic). JPEG not does not lend itself for images with sharp changes in tone. There are some typical types of images where JPEG should be avoided:
- images that have had a mask and shadow effect added to them in applications like Photoshop.
- screendumps or diagrams.
- blends created in Photoshop.
- images containing 256 (or less) colors.
- images generated by CAD-CAM software or 3D applications like Maya or Bryce.
- images that lack one or more of the process colors. Sometimes images are created that use for instance only the magenta and black plate. If such an image is compressed using JPEG compression, you may see artefacts show up on the cyan and yellow plate.
Фрактальный алгоритм
Идея метода
Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме — с помощью коэффициентов системы итерируемых функций (Iterated Function System — далее по тексту как IFS). Прежде, чем рассматривать сам процесс архивации, разберем, как IFS строит изображение, т.е. процесс декомпрессии.
Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х_координата, у_координата, яркость).
Наиболее наглядно этот процесс продемонстрировал Барнсли в своей книге “Fractal Image Compression”. Там введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран:
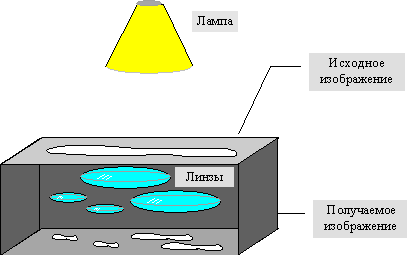 Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется “ неподвижной точкой ” или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого — самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: “треугольник Серпинского” и “папоротник Барнсли”. “Треугольник Серпинского” задается тремя, а “папоротник Барнсли” четырьмя аффинными преобразованиями (или, в нашей терминологии, “линзами”). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.
Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется “ неподвижной точкой ” или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого — самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: “треугольник Серпинского” и “папоротник Барнсли”. “Треугольник Серпинского” задается тремя, а “папоротник Барнсли” четырьмя аффинными преобразованиями (или, в нашей терминологии, “линзами”). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.
|
 =>
=> 
В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Причем, даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное количество раз, не дает заметного выигрыша во времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Далее приводятся основные определения и теоремы, на которых базируется фрактальная компрессия. Этот материал более детально и с доказательствами рассматривается в [3] и в [4].
Определение. Преобразование  , представимое в виде , представимое в виде
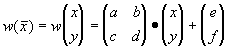 где a, b, c, d, e, f действительные числа и
где a, b, c, d, e, f действительные числа и  называется двумерным аффинным преобразованием.
Определение. Преобразование называется двумерным аффинным преобразованием.
Определение. Преобразование 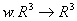 , представимое в виде , представимое в виде
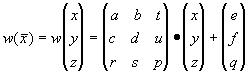 где a, b, c, d, e, f, p, q, r, s, t, u действительные числа и
где a, b, c, d, e, f, p, q, r, s, t, u действительные числа и  называется трехмерным аффинным преобразованием.
Определение. Пусть называется трехмерным аффинным преобразованием.
Определение. Пусть  — преобразование в пространстве Х. Точка — преобразование в пространстве Х. Точка 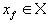 такая, что такая, что 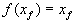 называется неподвижной точкой (аттрактором) преобразования.
Определение. Преобразование в метрическом пространстве (Х, d) называется сжимающим, если существует число s: называется неподвижной точкой (аттрактором) преобразования.
Определение. Преобразование в метрическом пространстве (Х, d) называется сжимающим, если существует число s: 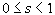 , такое, что , такое, что
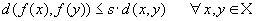 Замечание: Формально мы можем использовать любое сжимающее отображение при фрактальной компрессии, но реально используются лишь трехмерные аффинные преобразования с достаточно сильными ограничениями на коэффициенты.
Теорема. (О сжимающем преобразовании)
Пусть в полном метрическом пространстве (Х, d). Тогда существует в точности одна неподвижная точка
Замечание: Формально мы можем использовать любое сжимающее отображение при фрактальной компрессии, но реально используются лишь трехмерные аффинные преобразования с достаточно сильными ограничениями на коэффициенты.
Теорема. (О сжимающем преобразовании)
Пусть в полном метрическом пространстве (Х, d). Тогда существует в точности одна неподвижная точка 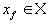 этого преобразования, и для любой точки этого преобразования, и для любой точки 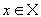 последовательность последовательность 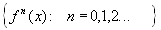 сходится к сходится к  .
Более общая формулировка этой теоремы гарантирует нам сходимость.
Определение. Изображением называется функция S, определенная на единичном квадрате и принимающая значения от 0 до 1 или .
Более общая формулировка этой теоремы гарантирует нам сходимость.
Определение. Изображением называется функция S, определенная на единичном квадрате и принимающая значения от 0 до 1 или 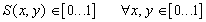 Пусть трехмерное аффинное преобразование
Пусть трехмерное аффинное преобразование 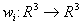 , записано в виде , записано в виде
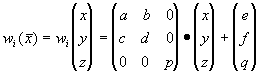 и определено на компактном подмножестве
и определено на компактном подмножестве 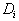 декартова квадрата [0..1]x[0..1]. Тогда оно переведет часть поверхности S в область декартова квадрата [0..1]x[0..1]. Тогда оно переведет часть поверхности S в область 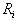 , расположенную со сдвигом (e,f) и поворотом, заданным матрицей , расположенную со сдвигом (e,f) и поворотом, заданным матрицей
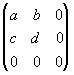 .
При этом, если интерпретировать значение S как яркость соответствующих точек, она уменьшится в p раз (преобразование обязано быть сжимающим) и изменится на сдвиг q.
Определение. Конечная совокупность W сжимающих трехмерных аффинных преобразований .
При этом, если интерпретировать значение S как яркость соответствующих точек, она уменьшится в p раз (преобразование обязано быть сжимающим) и изменится на сдвиг q.
Определение. Конечная совокупность W сжимающих трехмерных аффинных преобразований 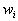 , определенных на областях , таких, что , определенных на областях , таких, что 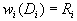 и и 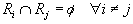 , называется системой итерируемых функций ( IFS).
Системе итерируемых функций однозначно сопоставляется неподвижная точка — изображение. Таким образом, процесс компрессии заключается в поиске коэффициентов системы, а процесс декомпрессии — в проведении итераций системы до стабилизации полученного изображения (неподвижной точки IFS). На практике бывает достаточно 7-16 итераций. Области в дальнейшем будут именоваться ранговыми, а области — доменными.
Построение алгоритма
Как уже стало очевидным из изложенного выше, основной задачей при компрессии фрактальным алгоритмом является нахождение соответствующих аффинных преобразований. В самом общем случае мы можем переводить любые по размеру и форме области изображения, однако в этом случае получается астрономическое число перебираемых вариантов разных фрагментов, которое невозможно обработать на текущий момент даже на суперкомпьютере.
В учебном варианте алгоритма, изложенном далее, сделаны следующие ограничения на области: , называется системой итерируемых функций ( IFS).
Системе итерируемых функций однозначно сопоставляется неподвижная точка — изображение. Таким образом, процесс компрессии заключается в поиске коэффициентов системы, а процесс декомпрессии — в проведении итераций системы до стабилизации полученного изображения (неподвижной точки IFS). На практике бывает достаточно 7-16 итераций. Области в дальнейшем будут именоваться ранговыми, а области — доменными.
Построение алгоритма
Как уже стало очевидным из изложенного выше, основной задачей при компрессии фрактальным алгоритмом является нахождение соответствующих аффинных преобразований. В самом общем случае мы можем переводить любые по размеру и форме области изображения, однако в этом случае получается астрономическое число перебираемых вариантов разных фрагментов, которое невозможно обработать на текущий момент даже на суперкомпьютере.
В учебном варианте алгоритма, изложенном далее, сделаны следующие ограничения на области:
 Эти ограничения позволяют:
Эти ограничения позволяют:
|
Рекурсивный (волновой) алгоритм
Английское название рекурсивного сжатия — wavelet. На русский язык оно переводится как волновое сжатие, и как сжатие с использованием всплесков. Этот вид архивации известен довольно давно и напрямую исходит из идеи использования когерентности областей. Ориентирован алгоритм на цветные и черно-белые изображения с плавными переходами. Идеален для картинок типа рентгеновских снимков. Коэффициент сжатия задается и варьируется в пределах 5-100. При попытке задать больший коэффициент на резких границах, особенно проходящих по диагонали, проявляется “лестничный эффект” — ступеньки разной яркости размером в несколько пикселов.
Идея алгоритма заключается в том, что мы сохраняем в файл разницу — число между средними значениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0.
Так два числа a 2 i и a 2 i+1 всегда можно представить в виде b1i =(a 2 i + a 2 i+1 )/2 и b2i =(a 2 i - a 2 i+1 )/2. Аналогично последовательность ai может быть попарно переведена в последовательность b1,2i.
Разберем конкретный пример: пусть мы сжимаем строку из 8 значений яркости пикселов (ai): (220, 211, 212, 218, 217, 214, 210, 202). Мы получим следующие последовательности b1i, и b2i: (215.5, 215, 215.5, 206) и (4.5, -3, 1.5, 4). Заметим, что значения b2i достаточно близки к 0. Повторим операцию, рассматривая b1i как ai. Данное действие выполняется как бы рекурсивно, откуда и название алгоритма. Мы получим из (215.5, 215, 215.5, 206): (215.25, 210.75) (0.25, 4.75). Полученные коэффициенты, округлив до целых и сжав, например, с помощью алгоритма Хаффмана с фиксированными таблицами, мы можем поместить в файл.
Заметим, что мы применяли наше преобразование к цепочке только два раза. Реально мы можем позволить себе применение wavelet- преобразования 4-6 раз. Более того, дополнительное сжатие можно получить, используя таблицы алгоритма Хаффмана с неравномерным шагом (т.е. нам придется сохранять код Хаффмана для ближайшего в таблице значения). Эти приемы позволяют достичь заметных коэффициентов сжатия.
Упражнение: Мы восстановили из файла цепочку (215, 211) (0, 5) (5, -3, 2, 4) (см. пример). Постройте строку из восьми значений яркости пикселов, которую воссоздаст алгоритм волнового сжатия.
Алгоритм для двумерных данных реализуется аналогично. Если у нас есть квадрат из 4 точек с яркостями a2i,2j, a2i+1, 2j, a2i, 2j+1, и a2i+1, 2j+1, то

Используя эти формулы, мы для изображения 512х512 пикселов получим после первого преобразования 4 матрицы размером 256х256 элементов: |
 --
-- 
В первой, как легко догадаться, будет храниться уменьшенная копия изображения. Во второй — усредненные разности пар значений пикселов по горизонтали. В третьей — усредненные разности пар значений пикселов по вертикали. В четвертой — усредненные разности значений пикселов по диагонали. По аналогии с двумерным случаем мы можем повторить наше преобразование и получить вместо первой матрицы 4 матрицы размером 128х128. Повторив наше преобразование в третий раз, мы получим в итоге: 4 матрицы 64х64, 3 матрицы 128х128 и 3 матрицы 256х256. На практике при записи в файл, значениями, получаемыми в последней строке (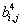 ), обычно пренебрегают (сразу получая выигрыш примерно на треть размера файла — 1- 1/4 - 1/16 - 1/64...).
К достоинствам этого алгоритма можно отнести то, что он очень легко позволяет реализовать возможность постепенного “прояв–ления” изображения при передаче изображения по сети. Кроме того, поскольку в начале изображения мы фактически храним его уменьшенную копию, упрощается показ “огрубленного” изображения по заголовку.
В отличие от JPEG и фрактального алгоритма данный метод не оперирует блоками, например, 8х8 пикселов. Точнее, мы оперируем блоками 2х2, 4х4, 8х8 и т.д. Однако за счет того, что коэффициенты для этих блоков мы сохраняем независимо, мы можем достаточно легко избежать дробления изображения на “мозаичные” квадраты.
Характеристики волнового алгоритма:
Коэффициенты компрессии: 2-200 (Задается пользователем).
Класс изображений:Как у фрактального и JPEG.
Симметричность: ~1.5
Характерные особенности: Кроме того, при высокой степени сжатия изображение распадается на отдельные блоки. ), обычно пренебрегают (сразу получая выигрыш примерно на треть размера файла — 1- 1/4 - 1/16 - 1/64...).
К достоинствам этого алгоритма можно отнести то, что он очень легко позволяет реализовать возможность постепенного “прояв–ления” изображения при передаче изображения по сети. Кроме того, поскольку в начале изображения мы фактически храним его уменьшенную копию, упрощается показ “огрубленного” изображения по заголовку.
В отличие от JPEG и фрактального алгоритма данный метод не оперирует блоками, например, 8х8 пикселов. Точнее, мы оперируем блоками 2х2, 4х4, 8х8 и т.д. Однако за счет того, что коэффициенты для этих блоков мы сохраняем независимо, мы можем достаточно легко избежать дробления изображения на “мозаичные” квадраты.
Характеристики волнового алгоритма:
Коэффициенты компрессии: 2-200 (Задается пользователем).
Класс изображений:Как у фрактального и JPEG.
Симметричность: ~1.5
Характерные особенности: Кроме того, при высокой степени сжатия изображение распадается на отдельные блоки.
|