ЗВУК И СМЫСЛ
Книга для внеклассного чтения учащихся старших классов
Издание 2-е, исправленное и дополненное
МОСКВА «ПРОСВЕЩЕНИЕ» 1991
ББК 81.2Р Ж91
Рецензент —
доктор филологических наук, профессор Л. А. Новиков
Журавлев А. П.
Ж91 Звук и смысл: Кн. для внеклас. чтения учащихся ст. классов.— 2-е изд., испр. и доп.— М.: Просвещение, 1991.— 160 с: ил.— ISBN 5-09-003170-3.
В книге в доступной, занимательной форме рассказывается об основанной на экспериментальных данных лингвистической теории содержательности звуковой формы в языке.
w 4306020000—114 00 „, „„„
Ж 103(03)-91 23-9' ББК 8,2Р
Учебное издание
ЖУРАВЛЕВ Александр Павлович ЗВУК И СМЫСЛ
Зав. редакцией В. Л. Склярова Редактор И. И. Нестеренко Художники Б. С. Вехтер, Л. А. Мистратова Художественный редактор И. В. Короткова Технический редактор М. М. Широкова Корректор М. Ю. Сергеева
ИБ № 12121
Сдано в набор 23.03.90. Подписано в печать П. 12.90. Формат 60 х 90Vi6- Бумага офсетная. Гарнит. литер. Печать офсетная. Усл. печ. л. 10 + 0,25 форзац + 0,50 вкл. Усл. кр.-отт. 13,50. Уч.-изд.л. 10,60 + 0,42 форзац + 0,55 вкл. Цена Зр. 10 к.
Ордена Трудового Красного Знамени издателство «Просвещение» Министерства печати и массовой информации РСФСР. 129846, Москва, 3-й проезд Марьиной рощи, 41.
Отпечатано с диапозитивов Саратовского ордена Трудового Красного Знамени полиграфического комбината Министерства печати и массовой информации РСФСР. 410004, Саратов, ул. Чернышевского, 59.
Отпечатано при посредстве В/О «Внешторгиздат»
Изготовлено в типографии «Интердрук» ГмбХ г. Лейпциг, ФРГ
© Издательство «Просвещение», 1981 ISBN 5-09-003170-3 © Журавлев А. П., 1991, с изменениями
...ищу союза Волшебных звуков, чувств и дум...
А. С. Пушкин
О ЧЕМ ЭТА КНИЖКА
Вы никогда не задумывались над тем, почему лилию называют именно лилия, а не репей, например, или карагач? А действительно, почему? Случайно ли каждое слово звучит так, а не иначе? Есть ли какие-нибудь закономерности в том, что такое, а не иное значение, содержание слова связано с такой, а не иной звуковой, фонетической формой его?
У слова есть значение — это ясно. Но только ли слова заключают в себе определенный смысл, несут какую-то информацию? Есть ли какой-либо смысл в самих звуках слова, в его звуковом оформлении?
Что касается звукоподражательных слов, то тут все понятно. Конечно, звуковое оформление их не случайно, оно имеет определенный смысл. Слово гром и звуками своими «гремит», так же как шелест «шелестит», писк «пищит», а хрип «хрипит». Здесь сама звуковая форма слова подсказывает его содержание, хотя и в самых общих чертах.
Но если слово называет не звук и не звучащий предмет? 'Вот ряд слов: стрела, стремительно, стриж, стрекоза, ястреб, стрепет, встряхнуть, быстро, струя, струна. Все они имеют значения, связанные с быстрым движением. И все они содержат звукосочетание стр. Игра случая? Трудно сказать. Ведь можно найти слова, содержащие стр, но не обозначающие вообще никакого движения,— страна, астра, строго, остро.
Почему нежный цветок-недотрога назван словом с «нежными» звуками — мимоза, а злой старик — неблагозвучным словом хрыч? Тоже случай? Возможно. А может быть здесь проявляются какие-то неизвестные нам свойства звуков речи?
Вот об этом и книжка. О том, что не только слова, но и звуки речи несут в себе какую-то информацию, какой-то скрытый смысл. О том, как звучание и значение соединяются в слове и возникает язык. О том, какую роль в жизни слова играют силы, связывающие звук и смысл в языке.
Это рассказ о научном поиске, о догадках и сомнениях, о решениях и находках. Читая книгу, вы сами становитесь участниками поиска, можете проверить полученные выводы, привлечь для их доказательства или опровержения новые факты из неисчерпаемой сокровищницы языков.
Здесь рассказывается о том, как строилась новая филологическая область — теория содержательности звуковой формы в языке, или фоносемантика.
В ее построении автор был не одинок. Вместе с ним работало много увлеченных людей — филологи и математики, психологи и художники, поэты и кибернетики.
Чтобы построить теорию, нужно было искать и применять разные инструменты и материалы — старые и новые. Инструменты науки — это ее методы. Часто в пределах одной науки — лингвистики — методов не хватало и приходилось заимствовать их у психологии, математики, физики. А уж если и соседние науки выручить не могли — делать нечего — конструировали методы сами.
С материалом тоже было не просто. Языковой материал — звуки, слова, тексты — огромен, и «голыми руками» с ним не справиться. Пришлось технически оснащаться — применять «рычаги» электронно-вычислительной техники. Но иногда и богатств разных языков оказывалось мало — нужен был материал с заданными свойствами. И его приходилось создавать искусственно — синтезировать.
Так что не удивляйтесь, если в книге о языке вам встретятся графики, таблицы, формулы, описания работы компьютера, которые на первый взгляд могут показаться сложными, но они вполне по силам старшеклассникам.
В нашей работе участвовало много студентов и старших курсов, и младших — вчерашних школьников. Многие из них внесли серьезный вклад в построение теории. Теперь некоторые из студентов стали учеными и сами ищут новые пути исследования величайшего достояния человечества — языка.
С тех пор как вышло первое издание книги, прошло десять лет. За это время фоносемантика, о зарождении которой здесь рассказывается, стала важной самостоятельной отраслью лингвистики. О фоносемантике написаны книги, ее научные положения применяются на практике в различных областях. И особенно важно для молодой теории, что она нашла применение в очень нужной и бурно развивающейся области современной технологии — в кибернетике.
Во втором издании мы расскажем о той новой области, которую можно назвать киберлингвистикои. Подробнее изложены компьютерный анализ фоносемантики слов и применение данных фо-носемантики при автоматической переработке языковой информации, в частности фоносемантический анализ поэтических произведений, особенно такой «яркий» его аспект, как компьютерный анализ и синтез звукоцвета.
В первом издании важно было не только рассказать о новой теории, но и привести такие доказательства, которые мог бы проверить и сам читатель, поскольку изложенные идеи были действительно очень уж неожиданными. Поэтому в книге были обширные табличные материалы, позволявшие перепроверить любые числовые данные, приводившиеся в качестве аргументов.
Теперь положение изменилось. Фоносемантические идеи не только не вызывают реакции отторжения, но, напротив, ведутся разнообразные исследования, развивающие эти идеи дальше. Компьютерное оснащение позволяет поднять эти работы на новый уровень, при котором расчетная часть исследований приобретает совсем иной вид. Например, для старых ЭВМ подготовка и введение информации было длительным и трудоемким процессом, а любые изменения во введенной информации требовали серьезных усилий. При работе с персональным компьютером информационный обмен с ним приобретает текущий характер: по ходу работы вы можете менять вводимую информацию, экспериментировать с ней, как вам угодно.
Поэтому весь числовой материал, имевший в первом издании однозначный характер, теперь становится иллюстративно-относительным, поскольку при смене исходных параметров каждый раз будут получаться несколько иные результаты. Вопрос, конечно, в том, насколько серьезно эти результаты будут меняться. И в первом и в настоящем издании книги подчеркивается, что все фоносемантические измерения имеют не абсолютный, а вероятностный характер, но если ранее требовалось больше внимания уделить конкретным результатам статистических подсчетов, то теперь их следует рассматривать как один из вариантов возможной реализации тех или иных утверждений.
Но следует особо подчеркнуть, что возможные варианты как исходных, так и расчетных параметров остаются в рамках допустимых статистических колебаний, а поэтому и числа, приведенные в книге, и возможные варианты других расчетов в принципе дадут сходные результаты, что постулировано теорией и доказано многолетней практикой фоносемантических исследований.
Перенос внимания с расчетов на демонстрацию содержательных результатов фоносемантического анализа проявился и в том, что значительно богаче стал лексический материал, проанализированный на компьютере с этой точки зрения.
Критики теории фоносемантики были по-своему правы, когда говорили, что два-три десятка примеров еще не могут служить надежным доказательством в таком важном вопросе, как соответствие значения и звучания слов. Тем более что речь идет не о жестком законе, а лишь о тенденции, о стремлении формы и содержания слов к взаимному соответствию.
Теперь компьютер настолько облегчил работу, что появилась возможность привести большой лексический материал, гораздо нагляднее подтверждающий правоту фоносемантической теории.
На первое издание было много отзывов — критических, поддерживающих, заинтересованных. Автор очень благодарен всем, кто откликнулся на публикацию книги. Прошу прощения, если не сумел ответить на все письма, но высказанные мнения постарался, как мог, учесть в новом издании, в отзывах на которое также глубоко заинтересован.
ИЗМЕРЬ ТО — НЕ ЗНАЮ ЧТО
Надо измерять измеримое и сделать измеримым то, что еще не поддается измерению.
Г. Галилей
ПОИСКИ ПУТИ
Попросите своих знакомых сказать, какой звук им кажется больше — И или О? Ручаюсь, что в большинстве случаев вы получите ответ — О. Спросите, какой звук грубее — И или Р, наверняка скажут — Р. Какой лучше — Д или Ф? Ясно, что Д.
Вспомните, мы говорим «мягкие и твердые согласные». Но ведь звуки нельзя потрогать. Не могут они обладать и ростом, хотя мы привыкли к терминам «высокие» и «низкие» звуки. Видимо, что-то такое есть, что заставляет нас считать, что А приятнее, чем X, О светлее, чем Ы, Р быстрее, чем Ш, Л мягче, чем Б, и т. д. Однако все суждения такого рода очень неопределенны, неустойчивы. Среди ответов на ваши вопросы будет много и прямо противоположных. То есть кто-то скажет, что И грубее, чем Р, или Ысветлее, чем О. Многие вообще скажут, что у звуков нет и не может быть таких признаков и все звуки для нас одинаковы.
— А неужели это так важно? — спросите вы.— Ну, светлый звук или темный, какая разница?
Оказывается, именно в этих свойствах звуков скрыта одна из тайн рождения, жизни и смерти Слова.
Еще в Древней Греции возник знаменитый лингвистический спор о том, как рождаются слова, как даются имена вещам. Одни мыслители древности считали, что имена даются «по соглашению», полностью произвольно, по принципу «как хотим, так и назовем». Другие полагали, что имя каким-то образом выражает сущность предмета, т. е. как бы предопределено для этого предмета заранее, по принципу «каждому — по его свойствам».
Древнегреческий философ Платон выбрал «золотую середину». Да, считает он, мы (коллектив носителей языка) вольны в выборе имени предмета, но это не воля случая, не свобода анархии. Свобода выбора ограничена свойствами предмета и свойствами звуков речи. По мнению Платона, в речи есть звуки быстрые, тонкие, громадные, округлые и т. д. И есть предметы быстрые, тонкие, громадные, округлые и т. д. Так вот, «быстрые» предметы получают имена, включающие «быстрые» звуки; «тонким» предметам подойдут
имена с «тонким» • звучанием; в состав имен для «громадных» предметов должны входить «громадные» звуки и т. п. Например, при произношении звука Р язык быстро вибрирует, поэтому Р — «быстрый» звук, и слова, обозначающие быстрое или резкое движение, включают, как правило, этот звук: река, стремнина, трепет, дробить, крушить, рвать, вертеть и т. д. (Заметьте, что примеры Платона в переводе на русский язык подтверждают рассуждения древнегреческого философа — содержат звук Р.)
Но возражавшие приводили контраргументы. Ведь не всегда же, говорили они, слова, обозначающие быстрое или резкое движение, содержат звук Р: мчаться, нестись, скакать, лавина и др. К тому же значение слова может измениться вплоть до противоположного, а звучание останется прежним. Таких случаев в любом языке сколько угодно. Например, в древнем языке, общем для всех славян, слово уродливый обозначало «хорошо уродившийся», но теперь в русском языке урод имеет значение «человек с некрасивой, безобразной внешностью», а в польском языке uroda — «красота». Где же здесь связь звука и смысла?
Слова-омонимы звучат одинаково, но имеют разные значения: ключ — отмычка и ключ — родник; лук — оружие и лук — растение. Слова-синонимы, наоборот, звучат по-разному, но их значения близки: аэроплан, самолет, лайнер; маленький, крошечный, миниатюрный, мизерный.
А сходно звучащие слова в разных языках? Разве они будут обозначать одно и то же? Конечно, нет. Первые слова, которые начинает произносить русский ребенок, это чаще всего мама, папа, баба, деда. Представьте себе, что и грузинский ребенок начинает овладение речью с тех же слов. Но для русского и грузина эти слова при сходном звучании имеют совершенно различные значения. По-грузински мама означает «папа», деда значит «мама», а бабуа — это «дедушка», которого в некоторых грузинских говорах называют папа.
Казалось бы, аргументы, убийственные для идеи о соответствии значений и звучаний слов. Не так ли? Но еще Платон предостерегал от того, чтобы с такими аргументами поспешно соглашаться. Он приводит такой пример. Оружие для сходных целей может у разных народов выглядеть по-разному, иметь разную форму, изготавливаться из разных материалов, но это не значит, что назначение и форма всех этих изделий не будут находиться в соответствии. Напротив. Сравним русский двуручный меч, турецкий ятаган и шпагу д'Артаньяна. Какие разные формы! Но все эти формы прекрасно соответствуют назначению (содержанию) предметов. Да и в формах, если присмотреться, много общего: все это — вытянутые, продолговатые, заостренные предметы с рукоятью. Совершенно невозможно представить себе меч, скажем, в форме шара или куба. И материалы, из которых изготовлены эти виды оружия, тоже должны быть сходными — прочными, упругими, твердыми. Нельзя же сделать шпагу из шерсти или боевой меч из стекла.
Так что, может быть, у звучаний разных слов, называющих одно и то же, обнаружатся какие-то сходные свойства?
Этот, пожалуй, самый длинный языковедческий спор, то затихая, то вспыхивая с новой силой, продолжался до нашего времени и шел с переменным успехом.
М. В. Ломоносов был уверен, что звуки речи обладают некоторой содержательностью, и даже рекомендовал использовать эти свойства звуков для придания художественным произведениям большей выразительности. Он писал в «Кратком руководстве к красноречию»: «В российском языке, как кажется, частое повторение письмени А способствовать может к изображению великолепия, великого пространства, глубины и вышины... учащение письмен Е, И, ѣ, Ю — к изображению нежности, ласкательства... или малых вещей...»
Но вы заметили это осторожное «как кажется»? Наука не верит тому, что кажется, наука требует доказательств. А их не было. И потому наш рациональный век, век научно-технической революции, вынес суровый и, казалось бы, окончательный приговор идее содержательности звуков речи. Эта идея стала считаться беспочвенной фантазией и совсем уж было попала на склад научных курьезов в компанию с вечным двигателем. Однако ее сторонники не сдавались и настойчиво искали убедительные доказательства своей правоты.
Одна из попыток выглядела так. Из самых разных языков было отобрано огромное количество слов, обозначавших, например, что-то маленькое и что-то большое. Оказалось, что в первом случае в словах чаще встречаются звуки И и Е, а во втором — А, О, У. Как будто бы объективный подход. Но не спешите с выводами. Лексический запас развитых языков огромен — до полумиллиона слов. И среди них найдется множество слов, обозначающих что-то маленькое и что-то большое. Все слова такого рода в нескольких десятках языков перебрать не удастся — их окажется слитком много. А какие выбрать? Маленький или мизерный? Карлик или лилипут? Жеребенок или щенок? А ведь от этого зависят выводы. Не получится ли так, что увлеченный своей гипотезой исследователь вольно или невольно подберет такие слова, которые подтвердят именно его гипотезу? Если делать выводы на основании анализа звуков в словах мизерный, миниатюрный, лилипут, дитя, то «маленьким» звуком окажется И, если же это будут слова малыш, карлик, пацан, то «маленьким» придется признать звук А. Можно «подогнать» список слов и под звук У: бутуз, карапуз — или О: кроха, подросток. Такая картина будет наблюдаться, конечно, и в других языках. Так что объективный подход на деле может обернуться полным произволом.
Лобовой штурм проблемы не удался. Сложна и многообразна живая стихия языка. Разнообразны силы, влияющие на жизнь слова, и трудно выделить какую-то одну из этих сил для исследования. Так не создать ли искусственно упрощенные лабораторные условия, чтобы выделить в слове только одну сторону — звуковую?
Несколько лет назад веселый человек И. Н. Горелов, один из первых исследователей этой проблемы, придумал вот что. Он нарисовал несколько картинок, на которых были изображены разные фантастические существа. Одно добродушное, кругленькое, толстенькое; другое — угловатое, колючее, злое и т. д. Потом придумал разные названия этих существ: «мамлына», «жаваруга» и др. Эти картинки были напечатаны в газете «Неделя» с просьбой угадать, где «мамлы-на», где «жаваруга» и т. д. Ответов было множество. И люди, приславшие письма из разных уголков страны, не сговариваясь, почти единодушно решили, что добродушная, толстенькая — это, конечно, мамлына, а колючая и злая, ясное дело,— жаваруга. Почему так? Видимо, сами звуки М, Л, Н вызывают у нас представление о чем-то округлом, мягком, приятном, а звуки Ж, Р, Г — наоборот, ассоциируются с чем-то угловатым, страшным.
Более строг такой эксперимент. Конструируют звукосочетания, внешне похожие на слова, и составляют из них пары так, чтобы «слова» различались лишь одним звуком, скажем бид и бад, вег и вог и т. п. Затем эти «слова» предлагают участникам эксперимента. Это любые носители какого-либо (например, русского) языка. Они дают экспериментатору нужную информацию, и потому их называют информантами. Экспериментатор говорит, что предложенные звукосочетания — это слова из неизвестного информантам языка (например, вьетнамского), причем в каждой паре одно слово обозначает что-то большое (например, «большая гора»), другое — что-то маленькое («маленький холмик»). Требуется угадать, какое из слов имеет значение «большая гора» и какое — «маленький холмик». Опрашивается много информантов, не менее 50 человек. А затем подсчитываются ответы. Оказывается, что в подавляющем большинстве ответов слова бид и вег связываются с чем-то маленьким, а бад и вог — с чем-то большим. Потом меняют в словах звук за звуком, и снова составляют пары (бод — буд, быд — бед, выг — виг, мид — мад и т. д.), и каждый раз опрашивают новых информантов. Затем меняют признаки. Парный признак «большой — маленький» заменяют признаками «хороший — плохой», «нежный — грубый» и др. И вновь опрос информантов.
Работа, как видите, нелегкая. Но это бы еще не беда. Трудность, во-первых, в том, что в звукосочетаниях действуют особые законы, которые могут приводить к резкому изменению звуков. Так, на конце слов звонкие согласные будут оглушаться, и вместо бад и бид получится [бат] и [бит]. Поэтому звонкие согласные можно получить только в начальной позиции. А здесь — другая сложность: перед А, О, У, Ысогласные будут твердыми, а перед И, Е — мягкими. Значит, «слова» бат и бит различаются не только гласными А— И, но и согласными Б — Б. На что же реагирует информант — на различие гласных или согласных? Или на то и другое вместе?
Во-вторых, для того чтобы так оценить все звуки, нужно построить большое количество звукосочетаний, и тогда среди них начинают появляться обычные слова. А в этом случае, понятно, информанты
реагируют не на звуки, а на смысл слов. Скажем, если вы спросите информантов, что больше — кит или кот, то получите единодушный ответ — кит и в результате сделаете неверный вывод, что И больше, чем О.
А не попытаться ли как-то оценивать отдельные звуки? Попробовали. Маленьким детям показывают две матрешки — во всем одинаковые, только одна совсем маленькая, другая — большая. Говорят: «Вот две сестрички. Одну зовут А, другую — И. Отгадай, которую зовут И?» И представьте себе — большинство детей показывает на маленькую матрешку.
Одну девочку спросили:
— А почему ты думаешь, что эту матрешку зовут И? Та отвечает:
— А потому что она маленькая.
Вот как прочно связан у нее звук с определенным представлением.
Но все же дети есть дети. Один отвлекся, другой указывает матрешку, не вникая в смысл вопроса, третий закапризничал. А ведь нужно перебрать и предъявить маленьким информантам все (!) возможные в данном языке пары звуков. Да нужно еще придумать, как задать детям и другие признаки, кроме признаков «большой — маленький». Представляете, что это за работа! Она, во-первых, невероятно трудоемка, а во-вторых, дает все же результаты, искаженные разного рода посторонними «шумами».
РЕШЕНИЕ
Однажды теплым летним днем мы гуляли по берегу очаровательной речки Хопёр с психологом Ю. М. Орловым и беседовали о нашумевшей тогда книге американского психолингвиста Ч. Осгуда «Измерение значения», где предлагалось «измерять» значение слова с помощью так называемых признаковых шкал.
— Вообще-то, конечно,— рассуждал Юрий Михайлович,— мы постоянно взвешиваем на весах признаков все, что угодно. Одно нам кажется очень приятным, другое приятным, но не очень, третье — так себе, а что-то представляется просто отвратительным. Одно мы считаем нежным, другое грубым. Что-то мы оцениваем как стремительное, а что-то как медлительное.
Он нагнулся и взял горсть речных камешков.
— Вот хотя бы эти камешки — один округлый, совсем как шарик, другой менее округлый, а вот этот острый, угловатый. Можно их расположить и по признакам светлый — темный, большой — маленький или красивый — некрасивый... Слушай! — Он вдруг остановился.— А звуки? Звуки речи! Пусть информанты располагают на признаковых шкалах все звуки речи.
Так возникла идея оценивать с помощью разных признаков отдельно взятые звуки речи, и оказалось, что это именно тот путь, который позволил не только обнаружить у звуков речи какую-то
содержательность, но и буквально измерить эти тонкие, почти не осознаваемые нами свойства звуков.
Давайте вместе с вами пройдем шаг за шагом всю процедуру анализа фонетической значимости, и, если вам будет интересно, вы сможете сами провести такие измерения со своими друзьями.
Инструментом для измерения служит шкала, образованная из двух антонимичных прилагательных типа хороший — плохой, большой — маленький и т. п. Для каждого из прилагательных с помощью слова очень образуются две степени сравнения: очень хороший, хороший; очень плохой, плохой.
Затем строятся шкалы, похожие на шкалу школьных оценок:
очень хороший — 1 очень большой — 1 очень нежный — 1
хороший — 2 большой —2 нежный — 2
никакой — 3 никакой — 3 никакой — 3
плохой — 4 маленький — 4 грубый — 4
очень плохой — 5 очень маленький — 5 очень грубый — 5
И так для многих слов, обозначающих признак предмета: сильный — слабый, светлый — темный, быстрый — медленный, округлый — угловатый, гладкий — шероховатый, легкий — тяжелый и др.
Теперь нужно еще построить список звуков, с которыми предстоит проводить эксперименты. И здесь нас поджидает вот какая трудность. Необходимо отобрать лишь те звуки, которые представляют для нас психологическую реальность, осознаются нами как звуки.
Если спросить любого говорящего по-русски, какие звуки произносятся после С в словах садовод и сыровар, всякий скажет, что в первом слове — А, во втором — Ы. Но на самом деле в первом слове произносится очень слабый, нечеткий (редуцированный) звук, нечто среднее между А, О, Ы. Значит, физически и в том, и в другом случае звучит сходный звук, а психологически осознаются, воспринимаются сознанием два совершенно разных звука (А и Ы). Почему?
Во-первых, мы знаем, что в сильной, ударной позиции в первом случае появится А (сад), а во втором — Ы(сыр), и это знание как бы подсказывает нам выбор звука в неясной, слабой позиции.
Во-вторых, потому, что в словах садовод и сыровар для обозначения сходных звуков пишутся разные буквы. Графический, буквенный образ не может не оказывать влияния на восприятие звука. Когда вы видите букву, у вас в сознании сейчас же звучит соответствующий звук, и наоборот. Буква как бы стабилизирует восприятие звука, помогает выработать в сознании типический образ звука и закрепляет его с помощью графического изображения. Даже если мы не читаем, а слушаем или произносим слова садовод и сыровар, буквы оказывают давление на наше восприятие, заставляя воспринимать разумом не совсем то, что воспринимается слухом.
Это хорошо заметно на таком примере. Буквы Е, Е, Ю, Я изображают в отдельном произношении звукосочетания [йэ], [йо], [йу], [йа]. Но мы привыкли к обозначению каждого такого звукосочетания одной буквой и, хотя слышим два звука, разумом восприни-
маем единый звукобуквенный образ. Физически звучит [йу], а психологически мы воспринимаем единый образ — Ю, сформированный в нашем сознании буквой.
Но с другой стороны, буква не отражает всех психологически важных особенностей звуков речи. Например, русскими четко осознаются различия между твердыми и мягкими согласными, поскольку эти различия играют важную смыслоразличительную роль. Мы не спутаем на слух слова угол и уголь, мел и мель, хотя различия в их звучании невелики. А в алфавите это важное свойство звуков — мягкость и твердость — не отражено: и для [л] и для [л'] есть только одна буква — Л.
И тем не менее нашему восприятию эти расхождения между звуком и буквой не помеха. Потому что мы не осознаем отдельно звука или отдельно буквы, а воспринимаем единый звукобуквенный образ.
Это очень хорошо чувствуют поэты. У А. Вознесенского в стихотворении «Мелодия Кирилла и Мефодия» есть такая строчка:
И фырчет «Ф», похожее на филина.
Что здесь «Ф» — звук или буква? Что это за средний род — «похожее»? В стихотворении речь идет о славянской азбуке, созданной Кириллом и Мефодием. Значит, буква? Но тогда нужно было бы написать: «Ф» — похожая на филина». В чем же поэт видит сходство? Очевидно, и в звучании (филин фыркает и пыхтит, будто произносит этот звук), и в зрительном образе («лицо» птицы с двумя светлыми овалами вокруг глаз действительно похоже на эту букву). Получается, что «звукообраз» филина сравнивается со «звукообразом» Ф, т. е. с чем-то средним между звуком [ф'] и буквой Ф. Поэт, надо полагать, был далек от такого рода рассуждений. Просто он почувствовал, что дело здесь не только в букве и не только в звуке — при восприятии важен звукобуквенный психический образ. (Дальше мы увидим, что поэты в стихах, как правило, ориентируются именно на такие звукобуквы.)
Таким образом, придется в наших экспериментах учесть как особенности звучания, так и особенности графического изображения. С одной стороны, придется включить в список для эксперимента твердые и мягкие согласные (Р и Р\ Д и Д', Г и Г' и т. п.), хотя они изображаются одной буквой. С другой стороны — буквы Е, Е, Ю, Я, хотя они изображают по два звука.
Но в дальнейшем, чтобы не усложнять изложение введением нового термина, будем эти звукобуквы именовать звуками, за исключением тех случаев, когда могут возникнуть недоразумения. Тогда уж придется уточнять, что имеется в виду: «чистый» звук, «чистая» буква или звукобуква.
Отобранные для эксперимента звуки нужно расположить в случайной последовательности, чтобы алфавитный порядок не «подсказывал» очередного элемента и не мешал оценкам. Так был получен ряд из 46 звукобукв, фрагмент которого приведен в таблице 1 «Приложения» (см. с. 153).
Можно начинать эксперимент. В нем участвуют экспериментатор и информанты — люди, для которых русский язык является родным. Экспериментатор дает информантам одну из шкал и поочередно предъявляет звуки. Информанты записывают очередной звук и ставят ему оценку по шкале, руководствуясь следующей инструкцией (пример для шкалы «светлый — темный»): «На ваших листах записана шкала, с помощью которой вы будете оценивать звуки и буквы, которые я буду произносить и показывать. Если вам почему-либо кажется, что данный звук «очень светлый», то вы приписываете ему оценку 1, если кажется, что звук «очень темный», приписываете оценку 5. Соответственно ставьте и другие оценки шкалы. Если звук не кажется вам ни «светлым», ни «темным», ставьте оценку 3. Старайтесь не раздумывать, а ставить первые пришедшие в голову оценки».
Звуки предъявляются довольно быстро, иначе информанты начнут искать логическое обоснование своих решений, например вспоминать слова с тем звуком, который оценивается. И тогда будет оцениваться значение слова, а не впечатление от звука.
Для того чтобы в сознании информанта возник четкий звуко-буквенный образ, экспериментатор произносит звук, затем показывает соответствующую букву и еще раз произносит звук. Понятно, что эксперимент проходит в полной тишине и все работают строго самостоятельно. Чтобы участники эксперимента работали совершенно свободно, ответы должны быть безымянными.
Почти всегда информанты спрашивают:
— А что значит «светлый» или «темный»?
— Не знаю,— отвечает экспериментатор.
— А как же ставить оценки?
— Ставьте как хотите.
— Ну хорошо, будем ставить наугад. Экспериментатор соглашается: „Что ж, ставьте наугад". Информанты ставят «отметки» всем звукам, которые предъявляет экспериментатор, и на этом эксперимент заканчивается.
Дальше следует обработка результатов. И вот оказывается, что «наугад» (как им кажется) участники эксперимента ставят звуку О, например, почти только 1 и 2, а звуку Ш — почти только 4 и 5!
Теперь посмотрите, как удобно, что восприятие звуков выражено числом. Это дает нам возможность буквально вычислить, насколько «светел» О и насколько «темен» Ш по коллективному мнению всех, кто участвовал в эксперименте. Информанты, сами того не ведая, «измеряют» то, чего не знают!
Действительно, представьте себе, что мы просто задали участникам эксперимента вопрос: «Какие впечатления вызывает у вас звук Д?» Ясно, что ответы будут самыми разными и уловить что-то общее в этом множестве ответов будет очень трудно. А с помощью измерительной шкалы легко можно определить «усредненное мнение» информантов хотя бы путем вычисления среднего арифметического всех поставленных ими оценок.
Чтобы такое среднее арифметическое было надежным, необходимо вычислять его по ответам большого числа информантов, ни в коем случае не менее 50. Причем лучше всего, чтобы это число 50 было составлено из ответов двух групп по 25 человек. Тогда можно даже вычислить коэффициент надежности результатов. Этот коэффициент укажет, насколько сходными оказались ответы в двух группах. Ведь если средние оценки, вычисленные по ответам одной группы, резко отличаются от средних, полученных по ответам другой, значит, эти средние случайны, ненадежны, и в разных сериях экспериментов будут получаться разные средние. Если же две разные группы дали сходные ответы, сходные средние оценки, то можно считать, что и в любом другом эксперименте получатся примерно те же результаты.
Конечно, в работе с информантами много тонкостей, не все сразу предусмотришь. Вы заметили, что нумерация делений шкал у нас прямо противоположна шкале школьных оценок: в школе 5 — очень хорошо, а 1 — очень плохо; у нас наоборот — 1 — очень хорошо, а 5 — очень плохо. И это не случайно. Оказывается, если цифры расположить как в школьной шкале, то все средние оценки звуков несколько сдвинутся в «хорошую» сторону. В чем дело? Видимо, оказывают свое влияние школьные пристрастия: информантам приятно ставить пятерки и четверки, а двойки и единицы — рука не поднимается.
Разгадывание таких психологических тонкостей требует проведения все новых и новых серий экспериментов. Так что иногда приходится повторять каждый эксперимент не два, а четыре-пять раз, чтобы получить устойчивые и действительно средние оценки.
А всего нам пришлось обработать более 100 тысяч ответов самых разных людей — учеников и учителей, студентов и профессоров, рабочих, колхозников и т. д.
Так сформировалась таблица, содержащая средние оценки всех русских звукобукв по признаковым шкалам. Всего звукобукв оказалось 346, шкал было взято 25, следовательно, таблица содержит 1150 оценок. Для наглядности в «Приложении» приведен ее фрагмент (см. таблицу 1 на с. 153).
Конечно, измерение можно вести не только по этим шкалам. В принципе чем больше шкал, тем лучше: полнее характеристика содержательности звуков. Но, во-первых, такая погоня за материалом бесконечна, а где-то все же нужно остановиться. Во-вторых, мы старались построить шкалы из слов, обозначающих наиболее важные, наиболее существенные признаки. И ниже будет показано, что в общем-то так оно и получилось.
В верхней строке таблицы указаны некоторые русские звуко-буквы. А цифры таблицы — это средние оценки каждой звукобуквы по каждой шкале.
Что означают эти средние оценки? Допустим, что в ответах пятидесяти человек по шкале «сильный — слабый» для звука Д встретилось 9 единиц, 34 двойки, 5 троек, 2 четверки и ни одной пятерки.
И
Среднее арифметическое составит:
9X1+34X2 + 5X3 + 2X4 =20 50
Это значит, что в общем «среднеарифметический, коллективный» носитель русского языка воспринимает этот звук как «сильный». Несмотря на то, что некоторые посчитали его «никаким», а двое даже «слабым».
Понятно, что если большинство информантов поставит какому-либо звуку тройки, то и средняя будет расположена возле этой оценки, т. е. звук окажется «никаким». Тот же результат получится, если выбор каждой оценки окажется действительно случайным: тогда каждая из оценок будет приписана звуку примерно одинаковое число раз, а это в среднем даст оценку, близкую к тройке («никакой»).
Случись так для всех звуков по всем шкалам, и мы должны были бы констатировать, что звуки не вызывают у нас никаких впечатлений, по любому признаку они «никакие». Но таблица 1 показывает, что средние для большинства звуков и по большинству шкал явно отклоняются от 3,0.
Конечно, здесь нужно решить вопрос о том, какое отклонение считать существенным, значимым. Для решения этой задачи существуют специальные математические приемы, но сущность операции можно пояснить следующим образом. Пока отклонение не достигло половины деления шкалы, средняя еще тяготеет к тройке, а затем уже приближается к значимой оценке. Например, оценки 2,6 или 3,4 ближе к 3,0, чем к 2,0 или 4,0; но 2,4 или 3,6 уже приближаются, соответственно, к 2,0 или 4,0. Значит, границами существенных отклонений логично выбрать 2,5 и 3,5. Эти пояснения наглядно изображает график:
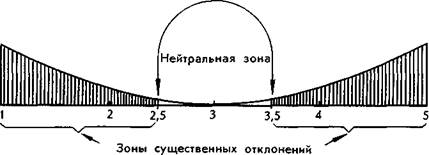
Средняя оценка только тогда является значимой, т. е. свидетельствует о том, что по данному признаку звук вызывает какое-то впечатление, когда эта оценка попадает в одну из зон значимых отклонений. Например, звук А по шкале «хороший — плохой» получил среднюю оценку 1,5. Эта средняя меньше 2,5, следовательно,
попадает в зону значимых отклонений, и потому мы можем считать, что звук А большинством говорящих на русском языке оценивается как «хороший». Звук X