Движущей силой экономической деятельности является спрос, отражающий поведение массового потребителя на изменение цен товара. Величина спроса определяется количеством товара, которое массовый потребитель добровольно покупает в течении некого периода, ценой данного товара и рядом других факторов. Для анализа экономической деятельности, прогнозирования и управления экономическими процессами принципиальное значение имеют выявление закономерностей спроса на товар от его цены. Следует заметить, что применение экономических методов в микроэкономическом анализе базируется на использовании предельных величин и, как правило, на детерминистическом подходе. Считается, что отказ от предельных показателей затрат, прибыли и других показателей означает невозможность использование математических методов в экономике.
Однако в условиях гибкого рынка цена товара, спрос на него меняется не только в течении месяца, но и в течении недели и даже дня. Поэтому выявление и постоянное уточнение основной закономерности, описывающей зависимость количества единиц товара, приобретаемое в течении некоторого периода, от его цены должно базироваться на прогнозных исследованиях.
Опыт проведения прогнозных исследований в различных областях общественной жизни, науки и техники позволил выявить ряд методов, которые могут эффективно применяться для прогнозирования микроэкономических показателей. Любая типовая методика прогнозирования включает такие необходимые элементы как выполнение предпрогнозной ориентации (определение предмета, целей, задач и периода упреждения); создание предпрогнозного фона (сбор и анализ данных в интервале ретроспекции); формирование исходной базовой модели и конструирование поисковой модели, ее верификация, а при необходимости уточнение, подготовка, обоснование и принятие необходимых решений.
Поскольку узловым этапом является построение модели прогноза, известные методы прогнозирования удобно классифицировать, разделив их на 3 основные группы:
· эвристические;
· прогнозные модели;
· статистические.
Эвристические методы включают построение интуитивных прогнозных моделей, которые формируются экспертами на основе целевой установки на выполнение прогноза, предоставляемой эксперту информацией, опыта, интуиции и знаний эксперта.
По типу циркулирующей в процессе экспертизы информации можно выделить три класса интуитивных моделей:
· индивидуальные оценки;
· коллективные оценки;
· комбинированные экспертные модели.
К индивидуальным относятся модели типа интервью, психоэвристической генерации идей, к коллективным - модели типа “мозговой атаки”, сессий выработки коллективного мнения, коллективной экспертной оценки; к комбинированным - модели итеративных опросов типа “Дельфи” и их модификации.
Аналитическими методами прогнозные модели получаются в тех случаях, когда известны общие закономерности развития процесса, его общая структура, важнейшие аналитически выраженные функциональные связи, имеется опытная (контрольная) выборка, позволяющая проверить работоспособность модели.
Аналитические модели, разделяются на модели, построенные по типу:
· структуризации целей развития;
· имитационного моделирования;
· морфологического анализа.
К статистическим относят методы, основу которых составляет формирование стохастических моделей прогнозирования. Предпосылкой применения таких методов является наличие необходимых статистических данных. Характеризующих период ретроспекции, и сведений, необходимых для определения модели прогноза. Широкое применение в прогнозировании статистических методов объясняется тем, что предметом статистики служит изучение методов выявления закономерностей массовых процессов.
Относительно приложений математической статистики обратим внимание на появляющуюся у ряда авторов тенденцию рассматривать соответствующие методы как средство снятия неопределенности на различных этапах принятия решений. Подобное отношение сужает область применения статистических методов, однако справедливо акцентирует внимание на наиболее сложных случаях их использования.
Области приложений отдельных методов при решении задач прогнозирования в микроэкономике показаны в табл. 3 (приложение С).
Развитый математический аппарат и накопленный опыт применения делают привлекательным обращение в решаемой проблеме к статистическим прогнозным методам и моделям.
Таким образом, большинство методов, ориентированных на прогнозирование микроэкономических параметров и процессов требует в той или иной степени учета фактора старения используемой информации. В связи с этим представляется целесообразным рассмотреть статистические закономерности старения информации.
2.2.Статистические закономерности старения прогнозной информации.
Всякой информации присуще свойство старения. С течением времени происходит частичная или полная потеря ценности для ее потребителя. Ценность информации - понятие достаточно широкое и требует конкретизации и уточнения применительно к рассматриваемой проблеме. С появлением новой информации возникает необходимость уточнить и по-новому интерпретировать изменившийся прогнозный фон для прогнозных исследований с целью выработки управляющих воздействий.
Анализируя процесс кумуляции информации, по глубине ретроспекции можно выявить период старения информации.
Для описания этого процесса введем следующие переменные:
п(Т) - глубина ретроспекции, выраженная в "квантах информации" и использованная в прогнозной модели, на момент времени Т;
N(Т) - нижняя граница сферы распространения полезной информации, выраженная в тех же единицах.
Под “ квантом информации ” будем понимать некоторый элемент, который может восприниматься и использоваться самостоятельно. В рассматриваемой области это экспериментальные данные (показатели рыночного спроса, зафиксированные в определенный момент времени, цена товара и др.).
Процесс кумуляции ретроспективной информации состоит в том, что объем полезной информации по мере увеличения ретроспекции все время увеличивается, достигая в некоторый момент T=Tk значения N(Tk):

 при
при 

 при
при 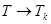
Задача изучения процесса состоит в анализе кумулятивной функции n(Т) во времени, вытекающего из качественного и количественного статистического исследования реальных процессов.
Естественно, что значение функции n(Т) в начальный момент времени T=0 позволяет считать, что n(0)=0. Можно также считать, что N(0) заметно больше нуля.
Интегральные функции n(T) и N(T), выраженные в абсолютных единицах измерения (квантах информации), можно выразить в относительных единицах, что позволит устранить искажающее воздействие динамики границы ретроспекции. С этой целью введем новую переменную m(T), которая обозначает долю полезной информации в общем ее объеме при формировании прогнозного фона, достигнутую к моменту времени Т. По определению
 (2.1)
(2.1)
При  динамические характеристики m(T) совпадают с аналогичными характеристиками n(T).
динамические характеристики m(T) совпадают с аналогичными характеристиками n(T).
Функция m(T) – монотонно возрастающая функция ретроспекции, изменяющаяся в интервале (0,1).
Когда n(Т) приближается к N(T), то m(Т) стремится к единице асимптотически при  . Это обстоятельство позволяет получить более простые аналитические зависимости для кумулятивной функции, не искажая значительно реальной картины.
. Это обстоятельство позволяет получить более простые аналитические зависимости для кумулятивной функции, не искажая значительно реальной картины.
Для дальнейшей спецификации кумулятивной функции необходимо кроме интегральной функции рассмотреть и дифференциальную, определив ее следующим образом
 (2.2)
(2.2)
Тогда дифференциальная относительная кумулятивная функция будет иметь вид:
 (2.3)
(2.3)
Требования к виду функций  и
и  вытекают из качественного описания процесса. Эти функции всюду положительные, к концу периода ретроспекции их значение монотонно убывает и стремится к нулю.
вытекают из качественного описания процесса. Эти функции всюду положительные, к концу периода ретроспекции их значение монотонно убывает и стремится к нулю.
Поскольку процесс кумуляции ценной информации имеет верхний придел, то необходимо ввести в исследование переменную, характеризующую скорость приближения процесса к концу. Эта переменная будет определять темп старения информации. Она выражается в виде той части еще не учтенной полезной информации, которая может быть использована в прогнозной модели:
 или
или  (2.4)
(2.4)
Интенсивность старения информации H(T) и h(T) определяет конкретную конфигурацию кривой h(T) или m(T).
Отсюда следует, что дифференциальное уравнение кумуляции информации (далее рассматриваются относительные функции) имеет вид:
 (2.5)
(2.5)
Проинтегрировав это уравнение при естественных ранее введенных допущениях, получим уравнение для определения интегральной функции
 (2.6)
(2.6)
Здесь предполагается, что m(0)-0, а
 при
при  т.к.
т.к. 
Интенсивность старения информации в общем случае будет зависеть от самых различных факторов. Поэтому функция h(t) можно записать в следующем общем виде
h(T)=h(T,m(T),xi)
где xi – множество экзогенных факторов, определяющих конкретный процесс старения информации.
Здесь предполагается, что значения этих факторов явно не зависят от m(T), T.
Дальнейший анализ динамики процесса старения информации состоит в спецификации вида функции h, который необходимо проводить исходя из эмпирических соображений.
Для выявления тенденций использования информации в исследованиях получило распространение аналитическое выравнивание эмпирических рядов распределения с помощью различных функций, которые описывают полиномы и комуляты распределения квантов информации, получаемые при наблюдении. Традиционными моделями, описывающими старение научной информации, являются кривые Бартона-Кеблера
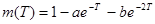 (2.7)
(2.7)
или их модификации (Аврамеску, Коула)
 , (2.8)
, (2.8)
 , и др. (2.9)
, и др. (2.9)
Анализ механизма старения информации по кривым Бартона-Кеблера позволяет умозрительно сделать вывод о том, что эти кривые соответствуют двум потокам научной информации, быстро стареющей и медленно стареющей, затухающей в два раза медленнее (по всей видимости второй поток относится к классическим и фундаментальным результатам). Применительно к исследуемой области это обстоятельство позволяет сделать вывод, что эти модели могут быть использованы в основном при применении системного анализа результатов фундаментальных исследований (см. табл. 3, приложение С).
Длительность существования полезной информации при прогнозировании в микроэкономике является величиной случайной и зависит от ряда факторов и может быть описана кривыми Гомперца или распределениями Гомперца-Макегама, в основе которых лежит идеализированная модель (экспоненциальное распределение)
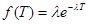 , (2.10)
, (2.10)
где 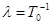 - величина, обратная средней длительности жизненного цикла полезной информации.
- величина, обратная средней длительности жизненного цикла полезной информации.
Соотношению (2.10) соответствует пуассоновский поток событий, однако предположение о постоянстве параметра  неприемлемо для широкого класса задач прогноза микроэкономических показателей, что обусловливает необходимость постулирования некоторых дополнительных предположений о вариации этого параметра. Модификация экспоненциальной зависимости (2.10) может осуществляться в двух направлениях, в одном из них можно принять параметр
неприемлемо для широкого класса задач прогноза микроэкономических показателей, что обусловливает необходимость постулирования некоторых дополнительных предположений о вариации этого параметра. Модификация экспоненциальной зависимости (2.10) может осуществляться в двух направлениях, в одном из них можно принять параметр  случайной величиной, в другом использовать предположение о том, что параметр имеет детерминированную тенденцию изменения во времени. На последнем постулате построены модели Гомперца и Гомперца-Макегама.
случайной величиной, в другом использовать предположение о том, что параметр имеет детерминированную тенденцию изменения во времени. На последнем постулате построены модели Гомперца и Гомперца-Макегама.
Если предположить, что параметр экспоненциального распределения имеет тенденцию изменяться во времени, которая может быть описана уравнениями тренда (например, уравнением экспоненты), то в этом случае интенсивность старения информации будет определяться двумя составляющими: константой а, не зависящей от длительности жизненного цикла полезной информации, и слагаемым, экспоненциального растущим со временем
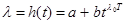 (2.11)
(2.11)
Эта функция, постоянные которой а, b и определяются статистическим путем на основе известных алгоритмов (методом трех сумм, методом трех точек и др.) имеет горизонтальную асимптоту, равную а. Ее график стремится к асимптоте при 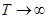 , но никогда ее не пересекает. Параметр b равен разности между ординатой кривой (при
, но никогда ее не пересекает. Параметр b равен разности между ординатой кривой (при  ) и асимптотой. Тогда, подставляя выражение (2.11) в зависимость (2.6) после очевидных преобразований, можно получить
) и асимптотой. Тогда, подставляя выражение (2.11) в зависимость (2.6) после очевидных преобразований, можно получить
 . (2.12)
. (2.12)
Это дифференциальный закон распределения Гомперца-Макегама. Его частным случаем при  (т.е. в случае представления уравнения тренда интенсивности простой экспонентой) является распределение Гомперца. Последнее для прогнозирования длительности жизненного цикла полезной информации может представлять особый интерес, так как является стохастическим аналогом весьма известной кривой Гомперца, которая применяется при аппроксимации статистических данных процессов развития благодаря своей асимметричности. Нетрудно заметить, что распределение Гомперца-Макегама, как и кривые Бартона-Кеблера, отражают процесс старения двух различных по интенсивности старения потоков информации, а кривая Гомперца описывает процесс быстрой потери ценности информации, поэтому эта модель предпочтительна для решения динамических задач краткосрочного прогнозирования (см. табл. 3, приложение С).
(т.е. в случае представления уравнения тренда интенсивности простой экспонентой) является распределение Гомперца. Последнее для прогнозирования длительности жизненного цикла полезной информации может представлять особый интерес, так как является стохастическим аналогом весьма известной кривой Гомперца, которая применяется при аппроксимации статистических данных процессов развития благодаря своей асимметричности. Нетрудно заметить, что распределение Гомперца-Макегама, как и кривые Бартона-Кеблера, отражают процесс старения двух различных по интенсивности старения потоков информации, а кривая Гомперца описывает процесс быстрой потери ценности информации, поэтому эта модель предпочтительна для решения динамических задач краткосрочного прогнозирования (см. табл. 3, приложение С).
4.3. Вероятностные модели механизма старения информации
Общий способ построения широкого класса вероятностных моделей старения информации при рандомизации параметра и использовании аппарата характеристических функций рассмотрим на следующем примере, имеющем прикладное значение. Так, например, если маргинальное (частное) распределение параметра Т0 в свою очередь имеет плотность
 (2.13)
(2.13)
(случайный характер параметра Т0 может быть обусловлен нарушением стационарности процесса, неоднородностью ретроспективного ряда значений Т0, ограниченным объемом информации и др.), то характеристическая функция безусловного распределения случайной величины Т0 будет иметь вид
 , (2.14)
, (2.14)
где  - характеристическая функция экспоненциального распределения.
- характеристическая функция экспоненциального распределения.
С помощью формулы обращения, плотность распределения случайной величины Г определяется следующим образом
 , (2,15)
, (2,15)
где  - модифицированная функция Бесселя третьего порядка.
- модифицированная функция Бесселя третьего порядка.
На продолжительность существования полезной для прогноза информации оказывает влияние колебание (изменение) цен на товары и услуги, динамика бюджета потребителя, изменение объема спроса на товар и других в общем случае ограниченного числа факторов.
В связи с этим представляется целесообразным при формировании математической модели старения информации использовать теоретико-вероятностную схему формирования законов распределения микроэкономических показателей как сумм небольшого случайного числа случайных величин.
К первым работам о суммах случайного числа случайных слагаемых относятся работы А.Н. Колмогорова и Ю.В. Прохорова, Вальда, Вольфовица и др. В основном в этих работах представлены результаты, касающиеся моментов для рассматриваемых сумм (теоремы вальдовского типа) и вопросы теории предельных распределений. В ряде работ (В.М. Круглов, Д. Саас и др.) для сумм случайного числа случайных слагаемых доказан ряд теорем, в которых предполагается существование предельных распределений случайного числа случайных слагаемых и при соответствующих дополнительных условиях утверждается существование предельного (в некоторых случаях нормального) распределения для сумм случайного числа случайных слагаемых. Такого рода теоремы в теории предельных распределений для сумм случайного числа случайных величин называются теоремами переноса. Полученные результаты (теоремы вальдовского типа и теоремы переноса) хотя важны для разнообразных применений, но в основном для рассматриваемого вопроса имеют ограниченный интерес.
Решение практических задач анализа и прогнозирования времени существования полезной информации в микроэкономике требует применения методов построения непредельных распределений сумм случайного числа случайных величин, нахождения их квантильных функций и оценки с их помощью предпрогнозного фона.
Основываясь на свойствах характеристической функции
 (2.16)
(2.16)
и используя ее основные свойства, приведем некоторые результаты, касающиеся законов распределения для сумм
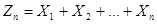
n первых случайных величин из бесконечной последовательности
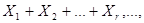
где само число слагаемых n есть случайная величина. В дальнейшем r будем обозначать случайную величину, способную принимать неотрицательные значения в зависимости от схематизации стохастического эксперимента

Вероятность события заключающуюся в том, что 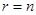 , обозначим
, обозначим

Кроме того будем предполагать, что случайные величины  независимы, одинаково распределены и независимы от случайной величины п. Будем также предполагать существование математических ожиданий
независимы, одинаково распределены и независимы от случайной величины п. Будем также предполагать существование математических ожиданий
 и
и  (2.17)
(2.17)
Функция распределения  суммы случайного числа n случайных величин Хi, на основании мультипликативного свойства характеристической функции определяется характеристической функцией
суммы случайного числа n случайных величин Хi, на основании мультипликативного свойства характеристической функции определяется характеристической функцией
 , (2.18)
, (2.18)
где 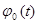 характеристическая функция случайной величины Х.
характеристическая функция случайной величины Х.
С помощью формулы обращения запишем формулу для плотности распределения 
 (2.19)
(2.19)
Конечность выражения

гарантирует замену порядка суммирования и интегрирования, следовательно
 (2.20)
(2.20)
В силу мультипликативности свойства функции (2.16) и теоремы единственности
 (2.21)
(2.21)
где  - плотность распределения сумм n случайных величин Xi/
- плотность распределения сумм n случайных величин Xi/
Таким образом, плотность непредельного распределения случайного числа случайных величин представляет собой смесь распределений с плотностью fn(x) вероятность появления которых в случайной выборке (удельный вес наблюдений в общей генеральной совокупности) равна Рn. Следует заметить, что такого рода комбинации распределений удобны в методологическом плане и могут найти применение в прикладной статистике при анализе генеральных совокупностей, объединяющих в себе несколько подсовокупностей, каждая из которых, в определенном смысле, однородна и описывается основным модельным распределением, например, нормальным, экспоненциальным и т.д. В рассматриваемой проблеме подсовокупности могут описывать статистику промежутков между квантами информации.
В качестве примера рассмотрим распределение суммы пуассоновского числа стандартных нормальных величин.
Характеристическая функция стандартного нормального распределения
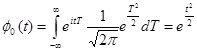 (2.22)
(2.22)
Отсюда характеристическая функция распределения суммы пуассоновского числа стандартных нормальных величин имеет вид
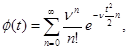 (2.23)
(2.23)
 (2.24)
(2.24)
В результате интегрирования получим
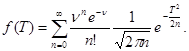 (2.25)
(2.25)
Полученная плотность распределения претерпевает значительную деформацию по сравнению с предельным нормальным распределением. Сумма случайного числа случайных величин, как видно из формулы (2.25), распределена по закону, отличного от нормального, и это отличие тем существенней, чем больше удельный вес имеют вероятности получения малых значений случайных чисел п. Это обстоятельство имеет весьма важное значение для решения вопроса отбраковки устаревшей информации.
К аналогичному выводу можно прийти, рассматривая сумму пуассоновского числа экспоненциально распределенных случайных величин. В этом случае плотность распределения имеет вид
 (2.26)
(2.26)
где m – величина, обратная среднему значению случайной величины Т.
Таким образом, применение предложенного подхода позволит более объективно выявить статистическую закономерность формирования времени существования полезной информации и решить ряд задач отбраковки устаревших данных при прогнозировании микроэкономических показателей.
4.4. Определение глубины предпрогнозной ретроспекции с учетом старения информации
Наиболее общая постановка задачи сравнения результатов прогнозных расчетов, полученных с использованием различной глубины ретроспекции, заключается в следующем. С целью выявления периода старения информации определяется k значений глубины ретроспекции (Т2, Т3, …, Тk+1). Значение Т1=0 целесообразно принять за контрольную точку, так как вполне очевидно, что в этой точке информация еще не устарела и ее можно считать наиболее ценной и достоверной. В ходе прогнозных исследований определяется … значений точечных оценок прогноза Xj(Tj). Если ввести в рассмотрение разность точечных оценок
Z1=X2(T2)-X1(T1), Z2=X3(T3)-X3(T2),…,Zj=
=Xj+1(Tj+1)-Xj(Tj),…Zk=Xk+1(Tk+1)-Xk(Tk), (2.27)
то значения Zj(j=1, …, k) можно считать независимыми случайными величинами, поведение которых описывается некоторым неизвестным законом распределения F(Z).
Ограниченный объем используемой информации не позволяет достаточно надежно его определить методами математической статистики. Поэтому требуется разработка специальных методов решения задачи сравнения результатов прогнозов по ограниченному набору ретроспекций.
Следует заметить, что выборочные моменты (математическое ожидание, дисперсия и др.) могут быть определены по выборке Zj(j=1, …, k).
Определение закона распределения случайной величины Z и его анализ позволяют дать статистическую и смысловую интерпретацию результатов сравнения прогнозных исследований, определить коэффициент доверия (или построить доверительную область), проверить статистическую гипотезу о непротиворечивости данных прогноза и контрольного значения динамического ряда.
Традиционно для описания подобного рода случайных величин обращаются прежде всего к нормальному (гауссовскому) распределению, которое играет фундаментальную роль в вероятностно-статистических исследованиях.
Традиционная универсальность нормального закона, как было отмечено выше, объясняется, прежде всего, полнотой теоретических исследований, относящихся к нему. При самых широких предположениях суммы случайных величин ведут себя асимптотически нормально (соответствующие условия и составляют содержание так называемой предельной теоремы). Во многих случайных величинах можно видеть суммарный аддитивный эффект большого числа независимых причин и т.д. В силу изложенных обстоятельств этот закон распределения широко используется в качестве модели для различных статистических совокупностей. В тех случаях, когда гипотеза о принадлежности статистической совокупности генеральной нормальной совокупности не подтверждается опытными данными или когда теоретико-вероятностная схематизация вероятностного эксперимента порождает другую модель, представляется целесообразным в силу универсальности нормального закона обратиться к теории суммирования случайного числа нормальных случайных величин.
Теоретической основой процедуры уточнения математической модели формирования закона распределения случайной величины Z является аппарат характеристических функций.
В этом случае функция распределения F(Z) суммы случайного числа n случайных величин Z, на основании мультипликативного свойства характеристических функций определяется характеристической функцией
 (2.28)
(2.28)
где  характеристическая функция нормальной случайной величины с параметрами m и a.
характеристическая функция нормальной случайной величины с параметрами m и a.
В качестве примера, имеющего прикладное значение в рассматриваемой области, рассмотрим распределение суммы пуассоновского числа нормально распределенных случайных величин. С этой целью составим уравнение
 (2.29)
(2.29)
правая часть которого равна эмпирической характеристической функции. Параметры нормального закона распределения m и a и закона Пуассона v могут быть определены в результате минимизации невязки или с помощью моментов. Метод моментов применительно к рассматриваемому уравнению заключается в приравнивании некоторого количества выборочных моментов, оцениваемых по правой части уравнения (2.29), к соответствующим теоретическим, определяемым по характеристической функции левой части уравнения в соответствии с зависимостью
 (2.30)
(2.30)
Естественно, что число получаемых в этом случае уравнений должно быть равным числу оцениваемых параметров (в данном случае трем).
Последовательно дифференцируя характеристические функции по t и приравнивая в полученных производных значения t нулю, можно составить следующую систему уравнений
 (2.31)
(2.31)
где Sk -асимметрия закона распределения, равная центральному моменту третьего порядка.
После некоторых алгебраических преобразований из системы уравнений (2.31) можно определить среднее число суммируемых случайных величин (параметр закона Пуассона).
 (2.32)
(2.32)
математическое ожидание и среднеквадратическое отклонение суммируемой нормальной случайной величины
 и
и  (2.33)
(2.33)
В формулах (2.32) и (2.33) коэффициент вариации Vz определяется по первым двум моментам 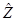 и
и 
Используя формулу обращения

можно получить плотность распределения пуассоновского числа нормальных случайных величин
 (2.34)
(2.34)
Очевидно, что плотность распределения (2.34), а точнее параметры v, m и s, зависят от объема выборок случайных величин {Zj}, j=1,…,k; j=1, k=1, k-1 и т.д. Последовательно от этапа к этапу анализируя ретроспективную информацию, можно построить семейство плотностей распределения fj(z) (j=k, k-1, …). Задачу отбраковки устаревшей информации в этом случае сводится к решению последовательного ряда задач проверки статистических гипотез о принадлежности контрольного значения параметра Z0 генеральной совокупности, описываемой законом распределения с плотностью (2.34). При этом следует учесть, что в силу проведенной схематизации процесса Z0=0. Тогда, задаваясь уровнем значимости a и учитывая симметричный характер закона распределения (2.34), можно найти такое значение индекса j, при котором выполнилось бы одно из следующих неравенств
 (2.35)
(2.35)
где 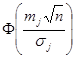 – функция Лапласа.
– функция Лапласа.
Справедливость соотношений (2.35) вытекает из очевидной процедуры вычисления функции распределения через плотность (2.34)
 (2.36)
(2.36)
Таким образом, задача определения глубины предпрогнозной ретроспекции с учетом старения информации может быть достаточно надежно решена традиционными методами математической статистики с помощью математической модели (распределения сумм пуассоновского числа нормально распределенных случайных величин).
ЗАКЛЮЧЕНИЕ
В данной курсовой работе рассмотрены основные методы прогнозирования экономической среды с учетом фактора старения информации на примере рыночного механизма спрос-предложение.
Проанализировав полученную информацию, можно сделать выводы о том, что для различных наук, отраслей, экономических сфер старение информации понятие растяжимое. Для одних информация, полученная десять лет назад, все еще представляется важной, а для других, неважной является информация, полученная в течении последних суток.
Также для различных отраслей применяют различные методы учета фактора старения информации. С помощью таких методов можно из имеющейся в наличии информации для прогнозирования выжать максимум полезной информации.
Список литературы
1. Б.П Ивченко, Л.А. Мартыщенко, И.Б. Иванцов. «Информационная микроэкономика». Часть 1. Методы анализа и прогнозирования, СПб.: «Нордмед-Издат», 1997. – 160 с.
2. Романенко И.В. Социальное и экономическое прогнозирование: Конспект лекций. – СПб.: Издательство Михайлова В.А., 2000 г. – 64 с.
3. Прогнозирование и финансирование экономики в условиях рыночных отношений. – М.: Мысль, 1970. – 448 с.
4. Рябушкин Б.Т. Применение статистических методов в экономическом анализе и прогнозировании. – М.: Финансы и статистика, 1987. – 75 c.
5. Статистическое моделирование и прогнозирование: под ред. А.Г. Гранберга. – М.: Финансы и статистика, 1990. – 382 с.
6. Грисеев Ю.П. Долгосрочное прогнозирование экономических процессов: – Киев: Наукова думка, 1987 – 131 с.
7. Шибалкин О.Ю. Проблемы и методы построения сценариев социально-экономического развития. – М.: Наука, 1992 – 176 с.
8. Суворов А.В. Методы построения макроэкономических сценариев социально-экономического развития// Проблемы прогнозирования. – 1993. – №4 – сс. 27-39
9. Калинина А.В. Современный экономический анализ и прогнозирование (микро- и макроуровень): Учебное пособие // А.В. Калинина и др., Межрегиональная Академия управления персоналом, 2-е изд. –Л.: МАУП, 1998.
10. Глущенко В.В. Прогнозирование –2-е изд., Испр. и доп. –СПб: СПГУВК, 1999. –245 с.
Приложение А:
Таблица 1
| Этапы | Стадии |
| Общая постановка задачи | 1. Общее знакомство с проблемой, указание цели; 2. Определение используемых понятий; 3. Сбор и анализ данных, оценка их точности; 4. Анализ различных возможных общих постановок задач с точки зрения существования и единственности их решения и его использования; уточнение цели. |
| Построение конструкций для решения задачи | 1. Формулировка априорных предположений и построение знаковой модели для математической постановки задачи; 2. Математическая постановка задачи. |
| Решение задачи | 1. Построение алгоритма решения математической задачи; 2. Получение решения математической задачи (обработка данных). |
| Интерпретация решений | 1. Проверка полученного решения в соответствии с известными принципами и законами и экспериментальными данными; 2. Определение области применимости и точности полученного решения. Перспектива использования в практических и теоретических целях. |
Приложение В:
Таблица 2