Что может биоинформатика
«ХИМИЯ И ЖИЗНЬ» №9, 2009 • БИОИНФОРМАТИКА
https://elementy.ru/nauchno-populyarnaya_biblioteka/izbrannoe/430895/Chto_mozhet_bioinformatika
М. С. Гельфанд,
доктор биологических наук, кандидат физико-математических наук,
Институт проблем передачи информации РАН
«Химия и жизнь» №9, 2009

Все знают, что биоинформатика — это как-то связано с компьютерами, ДНК и белками и что это передний край науки. Более подробными сведениями может похвастаться далеко не каждый даже среди биологов. О некоторых задачах, которые решает современная биоинформатика, рассказал «Химии и жизни» Михаил Сергеевич Гельфанд (интервью записала Елена Клещенко).
Информация в биологии
В последние десятилетия появилось много новых научных дисциплин с модными названиями: биоинформатика, геномика, протеомика, системная биология и другие. Но по сути, биоинформатика, также как и, скажем, протеомика, — не наука, а несколько удобных технологий и набор конкретных задач, которые решают с их помощью. Можно говорить, что каждый человек, который определяет концентрации белков методом масс-спектрометрии или изучает белок-белковые взаимодействия, работает в области протеомики. Но не исключено, что со временем это деление станет не таким важным: применяемая технология будет менее существенной, чем способ думать, ставить вопросы. И в этом смысле биоинформатика как самая древняя из этих наук — ей целых 25 лет — играет роль цементирующего начала, потому что независимо от того, каким способом получены данные, все равно они потом попадают в компьютер. Иначе быть не может: размер бактериального генома — миллионы нуклеотидов, высшего животного — сотни миллионов или миллиарды. Транскриптомика, изучающая активность генов, получает данные о концентрациях десятков тысяч матричных РНК, протеомика — о сотнях тысяч пептидов и белок-белковых взаимодействиях. С таким количеством информации нельзя работать вручную. Мы еще помним, как печатали на бумаге нуклеотидные последовательности, потом вырезали напечатанные строчки, подставляли друг под друга и таким кустарным способом делали выравнивание — искали сходные участки. Это было возможно, когда речь шла о десятках-сотнях нуклеотидов или аминокислот, но при современном объеме данных нужны специальные инструменты. Набор таких инструментов и предоставляет биоинформатика — в практическом плане это прикладная наука, обслуживающая интересы биологов.
Поскольку моя собственная работа связана в основном с анализом геномных данных, далее речь пойдет главным образом о геномике. Объемы данных еще до появления последнего поколения секвенаторов начали обгонять закон Мура: нуклеотидные последовательности геномов накапливались быстрее, чем росла мощность компьютеров. Не будет большим преувеличением сказать, что за последние годы биология начала превращаться в науку, «богатую данными». Условно говоря, в «классической» молекулярной биологии в одном эксперименте устанавливался один биологический факт: аминокислотная последовательность белка, его функция, то, как регулируется соответствующий ген. А теперь такого рода факты получаются индустриально. Молекулярная биология движется по пути, по которому уже прошли астрофизика и физика высоких энергий. Когда имеется постоянно работающий радиотелескоп или ускоритель, проблема добычи данных решена, и на первый план выступают проблемы их хранения и обработки.
С биологией происходит то же самое, причем очень быстро, и не всегда бывает легко перестроиться. Однако те, кому это удается, оказываются в выигрыше. На нашем семинаре один биолог рассказывал, как они с коллегами изучали некий белок традиционными методами экспериментальной биологии. Это сложная задача: зная, что в клетке выполняется определенная функция, найти белок, который за нее отвечает. Они нашли этот белок, занялись его изучением и убедились, что должен существовать другой белок с подобными свойствами, поскольку наличие первого объясняет не все наблюдаемые факты. Искать второй белок на фоне первого было еще более сложно, но они справились и с этим. А затем был опубликован геном человека — и, получив доступ к его последовательности, они нашли еще дюжину таких белков...
Из этого примера вовсе не следует, что практическая молекулярная биология себя исчерпала. Скорее она научилась пользоваться новыми инструментами: интерпретировать не только полоски в геле после электрофореза, концентрации мРНК и белков или, скажем, скорость роста бактерий, но и колоссальные массивы данных, хранящиеся в компьютере. Заметим, что элемент интерпретации неизбежно присутствует и в классической биологии. Когда исследователь утверждает, что белок А запускает транскрипцию гена В, он не наблюдает напрямую, как белок взаимодействует с регуляторной областью гена, а делает такой вывод из расположения полосок на геле и других экспериментальных данных. В биоинформатике, по сути, та же ситуация, только возведенная в абсолют: готовые данные лежат в компьютере, и среди них нужно отыскать пазлы, из которых получится собрать картинку.
К области технической биоинформатики относится первичная обработка данных. Секвенатор не сам «читает» молекулы ДНК, а дает на выходе кривые флуоресценции, пики на которых еще нужно превратить в нуклеотидную последовательность. Эта задача решается каждый раз по-новому для нового устройства секвенирования, и решает ее биоинформатика. Кроме того, как уже говорилось, полученные данные надо где-то хранить, обеспечивать к ним удобный доступ и т. д. Все это чисто технические проблемы, но они очень важны.
Более сложное и интересное занятие биоинформатиков — получать на основе данных о геноме конкретные утверждения: белок А обладает такой-то функцией, ген В включается в таких-то условиях, гены С, D и Е экспрессируются в одно и то же время, а продукты их образуют комплекс. Именно этим занимаемся мы, и в этом состоит практическое применение нашей науки. Для нас пользователи — другие биологи, которым мы сообщаем интересные для них факты.
Расположение и регуляция
Как можно из последовательности нуклеотидов делать выводы о функции белков и генов? Первое соображение кажется банальным: если белок похож на какой-нибудь другой, уже изученный, то с большой вероятностью он делает примерно то же самое. На самом деле оно не так уж банально: первым серьезным успехом в этом направлении биоинформатики было утверждение, что вирусные онкогены — это «испорченные» гены самого организма.
Выполнить подобное сравнение сейчас уже несложно. Существуют банки данных по нуклеотидным и белковым последовательностям (подробнее о них рассказывалось в «Химии и жизни», 2001, №2). Общее представление о том, как это должно быть устроено, появилось в конце 80-х годов, и в этом смысле биоинформатика была готова к потоку геномных данных. Сегодня это стандартный интернет-сервис: вы загружаете свою последовательность в окошко, нажимаете кнопку, и через несколько секунд вам сообщают, на какие последовательности из этой базы она похожа.
Дальше начинаются более тонкие соображения. Известно, например, что у бактерий гены часто бывают организованы в опероны, то есть транскрибируются в виде одной матричной РНК. Есть разные эволюционные теории, которые объясняют, почему так получилось, что функционально связанные гены образуют оперон. Первая теория состоит в том, что это удобно и полезно, потому и поддерживается эволюцией. Если белки имеют общую функцию, например, отвечают за разные этапы переработки одного вещества, логично, чтобы они появлялись в клетке одновременно, по одному и тому же сигналу (естественно, что при общей мРНК и регуляция одна на всех) и в равном количестве. Второе утверждение менее тривиально и более красиво. Генам, продукты которых имеют связанные функции, выгодно находиться рядом из-за горизонтального переноса. Это очень существенный механизм эволюции бактерий: участки генома одной бактерии попадают в другую, которая благодаря этому может приобрести новые полезные признаки. Понятно, что, если в новый геном переместится лишь один ген метаболического пути, то соответствующий белок будет бесполезен: субстрата для катализируемой им реакции нет, а ее продукт, в свою очередь, некому перерабатывать. Дополнительным подтверждением этой теории служит то, что у бактерий бывают геномные локусы, в которых гены из одного метаболического пути лежат на разных цепях ДНК и потому транскрибируются в разных направлениях. Здесь точно играет главную роль повышенная вероятность совместного переноса.
Тот факт, что два гена находятся рядом в каком-то одном геноме, не очень много говорит про их функциональную связь, это может быть и случайность. Однако мы умеем отождествлять гены в разных организмах. Последовательности у них, конечно, не совпадают до нуклеотида, а могут различаться довольно значительно. Но есть некие правила, которые позволяют утверждать, что это один и тот же ген, скажем, у кишечной и у сенной палочки. Итак, если пара генов находится рядом не в одном геноме, а в пятидесяти, причем у представителей разных таксономических групп (то есть это расположение не просто унаследовано от общего предка), — это означает, что они действительно тяготеют друг к другу. Если бы эволюция не поддерживала их близкого расположения, оно не сохранилось бы. И значит, можно предположить, что они функционально связаны.
Второе соображение похоже на первое. Не все бактерии имеют одинаковый набор генов: к примеру, если ген кодирует фермент, нужный для переработки какого-то углевода, то его не будет у бактерии, которая этим углеводом не питается. Зато у бактерии, которая питается именно этим углеводом, будет весь необходимый набор: и ферменты, и белок-транспортер, переносящий углевод внутрь клетки. Функционально связанные гены присутствуют в геноме по принципу «все или ничего»: как уже говорилось, бессмысленно иметь лишь фрагмент метаболического пути, а бактерии — существа экономные, то, что не приносит пользы, из их генома быстро исчезает. Поэтому если сделать таблицу, где по строкам расположить различные гены, а по столбцам — разные геномы, и отметить плюсами и минусами гены, присутствующие или отсутствующие в данном геноме, мы увидим группы генов, обслуживающих одну и ту же функцию. И неизвестный ген с тем же набором плюсов и минусов, что у некой группы, скорее всего, можно приписать к ней же.
Третье соображение связано с регуляцией активности генов. Рядом с геном обычно присутствуют участки, с которыми взаимодействуют определенные белки — они могут запускать транскрипцию, блокировать ее, управлять ее интенсивностью, иначе говоря, от них зависит активность гена в каждый момент времени. Некоторые регуляторные участки очень хорошо опознаются по характерным последовательностям «букв», но это бывает редко. Например, участки связывания факторов транскрипции мы распознаем в геномах с невысокой точностью и вместе с правильными сайтами нагребаем кучу «мусора» — похожие коротенькие участки, которые на самом деле не имеют отношения к регуляции генов. Но поскольку совместно регулируются те гены, которые совместно работают, настоящие сайты связывания находятся перед одними и теми же генами в десятке геномов, а случайные — раскиданы там и сям, и никакой закономерности в их расположении не прослеживается. Получается мощный фильтр, позволяющий отсеять «мусор». И если перед геном с неизвестной функцией устойчиво обнаруживается знакомый сайт, будет ясно, что этот ген регулируется в составе функциональной подсистемы, которая регулируется тем же регулятором и обеспечивает ту же функцию.
Мне интереснее всего изучать эволюцию регуляторных систем, но побочным продуктом при этом бывает множество функциональных предсказаний. Исследование развивается как детектив: каждое соображение по отдельности очень мелкое, но если «улик» много и они все попадают в одну точку, то можно делать уверенные утверждения. Был случай, когда мы подробно описали регуляторную систему — фактор транскрипции, сайты его связывания, то, что это будет репрессор, а не активатор, то, что связывание будет требовать кооперативного взаимодействия двух димеров, — просто глядя на буковки генома. Впоследствии все это вплоть до деталей оказалось правильным.
Рибосома как депо цинка
В одной из таких работ центральную роль сыграла Екатерина Панина, на тот момент студентка мехмата МГУ (потом она поступила в аспирантуру Калифорнийского университета Лос-Анджелеса и стала настоящим биологом-экспериментатором). Она пришла к нам на третьем курсе и сказала, что хочет заниматься такой биологией. К окончанию мехмата у нее было опубликовано несколько статьей в серьезных журналах.
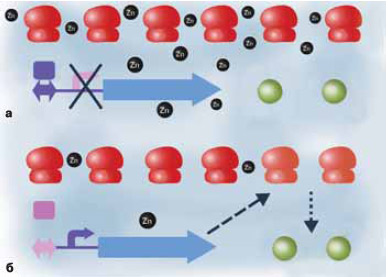
Рис. 1. При избытке цинка (а) бактериальные рибосомы его запасают, а при недостатке (б) — отдают белкам. Если ионов цинка много, то его хватает и рибосомным белкам, и цинк-зависимым ферментам; в этом случае выключен синтез рибосомного белка, не содержащего цинка (прямоугольник — цинковый репрессор, голубая стрелка — ген белка). Когда цинка мало, белок синтезируется, замещает в рибосомах цинксодержащие белки, и они отдают цинк ферментам. Изображение: «Химия и жизнь»
Бактериальной клетке нужны ионы цинка: они, например, входят в состав некоторых ферментов как кофакторы. Соответственно есть и молекулярная машинерия, которая обслуживает все процессы, связанные с цинком. Мы изучали цинковый репрессор (в больших количествах цинк ядовит для клетки, поэтому выключать его транспорт при достаточных концентрациях не менее важно, чем уметь добывать его из окружающей среды), используя идеологию, о которой рассказывалось в предыдущей главке. Если перед геном имеется потенциальный сайт цинкового репрессора, то этот ген, возможно, относится к метаболизму цинка. Именно таким образом мы в свое время «вычислили» цинковый транспортер — трансмембранный белок, который обеспечивает проникновение цинка внутрь клетки.
Так вот, в 2002 году Катя обратила внимание, что потенциальные сайты цинкового репрессора почему-то часто попадаются перед генами рибосомных белков. Она поделилась этим наблюдением с научным руководителем, и я сказал, что, поскольку в геноме больше сотни генов рибосомных белков, а сайты встречались перед разными генами, это случайность. Но Катя в случайность не поверила и нашла статью Евгения Кунина (о его модели происхождения клетки см. в статье М. А. Шкроб в августовском номере), которая была опубликована незадолго до этого. Там было показано, что некоторые рибосомные белки содержат мотив связывания цинка — так называемую цинковую ленту, три или четыре цистеина на правильном расстоянии друг относительно друга и в правильном контексте. Важное наблюдение Кунина с коллегами состояло в том, что один и тот же белок в некоторых организмах имеет эти цинковые мотивы, в других — не имеет, но, судя по всему, нормально функционирует и без цинка. А у некоторых бактерий один и тот же белок имеется в двух вариантах, с цинковой лентой и без нее.
И вот Катя заметила, что в последнем случае, когда есть два варианта белка в одном геноме, тот, который без цинковой ленты, репрессируется цинковым репрессором. Иначе говоря, в присутствии цинка экспрессируется вариант белка, которому цинк нужен, а в отсутствие цинка — тот, которому он не нужен.
Основа существования любой клетки — тяжелая промышленность, производство средств производства, точно так, как нас учили на лекциях по политэкономии социализма. Около 70% белка клетки — это белки рибосом, то есть органелл, которые нужны, чтобы делать другие белки. С другой стороны, цинк — кофактор ферментов, жизненно важных для клетки, таких, например, как ДНК-полимераза. Если цинка становится мало, его полностью забирают себе рибосомные белки, ферментам ничего не остается, и клетка погибает. Но у клетки есть резервная копия рибосомного белка, которому цинк не нужен. Мы предположили, что клетка включает синтез таких белков в условиях дефицита цинка и они встраиваются в часть рибосом на место цинксодержащих белков. При этом какое-то количество цинка высвобождается. Может быть, рибосомы после этого работают чуть менее эффективно, может быть, и вообще не работают — но ради того, чтобы цинка хватило жизненно важным ферментам, которые представлены существенно меньшим числом копий, стоит пожертвовать небольшой долей рибосом.
Мы написали статью, но в течение года ни один уважаемый журнал не принял к публикации безумную теорию о рибосомах как депо цинка. Однако мне Катина находка казалась очень красивой, и я единственный раз в жизни воспользовался тем, что мой дед, как член Академии наук США, имеет право представлять статьи для публикации в «Proceedings of the National Academy of Sciences of the USA ». Он послал статью на рецензию Кунину, который дал положительный отзыв (и, кажется, кому-то еще). Статья вышла в PNAS, и, как вскоре выяснилось, очень вовремя: через полгода появилась статья японских биологов, которые экспериментально показали то же самое. Можно догадаться, что они над этим работали давно, и, вероятно, им было немного обидно, что компьютерное предсказание предвосхитило их результаты.
Заметим, что вся эта история построена на очень мелких частных наблюдениях (есть в белке цистеины — нет цистеинов, есть потенциальный сайт репрессора — нет сайта...). Но в совокупности эти мелочи позволили сделать нетривиальное заключение, оказавшееся абсолютно верным. Вообще, когда мы публикуем статьи, то стараемся как можно более четко сказать, какое из наших предсказаний считаем надежным, а какое может оказаться неправильным. Так вот, среди тех, в которых мы были уверены, неправильных пока не оказалось ни одного (проверены уже десятки), а вот среди слабых проколы действительно были, хотя тоже не часто.