ВерлинА. А., e-mail: alexandrverlin@mail.com
АвцыновА. О., e-mail: artem.avtsynov@mail.ru
Воронежский государственный университет
Ежедневно, в мире появляются сотни гигабайт различных данных которые отражают различные сферы человеческой деятельности. Например, использование сотовой связи или других видов коммуникации (мессенджеры, интернет),но данные могут генерироваться самопроизвольно когда человек совершает такие действия как покупка товара в интернет-магазине или заказ пиццы. Люди заказывают, покупают, проводят различные манипуляции с товарами или услугами в интернете, все это генерирует огромные объемы полезной информации. Когда человек делает заказ, формируются блоки информации, эти блоки содержит данные о товарах/услугах, персональные данные заказчика (с его разрешения), данные исполнителя или подрядчика, а также детальная информация о типе заказа.
Данные, в сыром виде, попадают в хранилища и без специализированной обработки похожи на свалку, но, если эти данные агрегировать правильным образом, далее проанализировать, то можно получить ценную информацию для бизнеса, по конкретному клиенту/пользователю. На основании анализа можно составить персональную корзину, для покупателя, формировать персональный список акционного товара или услуг, конкретно для каждого клиента/пользователя, тем самым повышая лояльность пользователя/клиента, а следовательно и прибыльность бизнеса.
Но для создания такой системы важно правильно спроектировать уровень агрегации данных и приведение их к нужному формату для последующего анализа и формирования отчетов по конкретному клиенту/пользователю.
В общем виде структура системы следующая, уровень сбора информации, уровень агрегации(обработка “сырых” данных поступающих в хранилища), уровень анализа данных (datascience), уровень визуального представления(графики, удобный и красивый интерфейс).
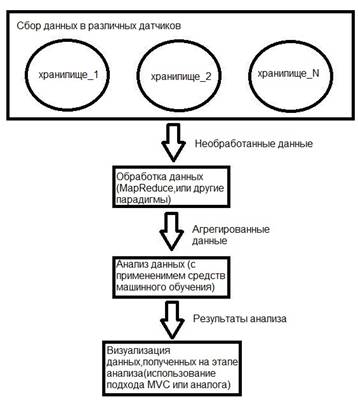
Рис.1.Базовая схема проекта.
Такая система является частично рекомендательной и способна в автономном режиме агрегировать, анализировать и предоставлять информацию по конкретному клиенту/пользователю.
Прежде чем начинать разработку такой системы, необходимо провести глубокий, детальный анализ: целевой аудитории (для кого и с какой целью будет разрабатываться данная система), анализ доступных данных(выделить необходимые источники и сформировать список параметров, которые будут использоваться для анализа в моделях),подобрать подходящую парадигму построения системы обработки сырых данных, основываясь на объеме входных данныхи их времени обработки (традиционная парадигма MapReduce или более быстрые, но ресурсо-затратные аналоги Spark и другие),а также ряд вопросов по части железа-это физический кластер. После проведения качественного анализа, написания технического задания и учета рисков в реализации системы, можно преступить к разработке.
Рассмотрим уровень агрегации (обработка “сырых” данных) и поэтапно разберем основные нюансы работы системы на этом уровне.
Данные поступают в сыром виде, это одна из проблем начала обработки больших данных, так как для получения какой-либо полезной информации необходимо заранее знать, в каком месте, в строке, находится интересующий нас показатель, только зная формат строки, можно корректно и эффективно сделать ее обработку, посчитать сумму или среднее значение, в зависимости от цели, для чего делается анализ. Как правило, на этом этапе отсекаются “битые” некачественные строки.
Кажется, что проблемы тут нет, но в реальных системах, данные могут попадать в программу-обработчик в непредсказуемом виде: неполная заполняемость всех полей, случайная деформация или потеря строк (сбой датчиков, электропитания и другие факторы), намеренное или случайное искажение показателей (неполное указание персональных данных, а так же частичное или неверное указание характеризующей человека информации (хобби,увлечения и т.д.)). Для решения этой проблемы можно выделить две рекомендации:
1. Выделите основные(необходимые) показатели которые пользователь должен заполнить в обязательном порядке;
2. Минимизируйте количество различных показателей, для получения максимально полезной информации. То есть выбирать источники с наиболее влиятельным набором показателей.
Для эффективности и удобства манипулированием строк можно прибегнуть к созданию специального класса,назовем этот класс-RowScheme. Идея написания этого класса состоит в том, что вам не придется заботится о разбивании строки на части, вычленением необходимых показателей и сохранением их в созданные, заранее, переменные. При реализации такого подхода, вы будете оперировать строкой в рамках объекта, где переменные обозначают каждое поле, а для удобной работыдоступны методы get/set. При чтении строки с источника создается объект, ему передается входная строка, строка проходит этап разбиения на показатели по разделителю и полученные значения присваиваются конкретной переменной в объекте. Далее, используя методы get/set можно обращаться к любой переменной по имени/индексу и производить дальнейшие манипуляции с ней.
Например, при реализации программы-обработчика в парадигме MapReduceнаписание такого класса, какRowScheme будет эффективней обычного разбиения строки.
public class RowSheme {
private static final String DELIMITER = "\t";
private static final int LENGTH = 4;
private final DateTimeFormatter DT_FORMATTER = DateTimeFormat.forPattern("yyyyMMddHHmmss");
privatestatic final int INDEX_NAME = 0;
private static final int INDEX_SURNAME = 1;
private static final int INDEX_DATE_TIME= 2;
private static final int INDEX_NUMBER = 3;
public final String NAME;
public final String SURNAME;
public final DateTime DATE_TIME;
public final String NUMBER;
publicRowSheme(String row) throws Exception {
String[] columns = row.split(DELIMITER);
if (columns.length == LENGTH) {
this.NAME = columns[INDEX_NAME];
this.SURNAME = columns[INDEX_SURNAME];
this.DATE_TIME= DateTime.parse(columns[INDEX_DATE_TIME], DT_FORMATTER);
this.NUMBER = columns[INDEX_NUMBER];
} else {
this.NAME = null;
this.SURNAME = null;
this.DATE_TIME = null;
this.NUMBER = null;
}
}
}
После того, как получилось успешно считывать строки реализуется обработка этих строк согласно техническому заданию, группировка, накапливание за периоды, подсчет среднего и другие манипуляции. В результате получается строка в которой находятся агрегированные показатели, в необходимом формате для дальнейшего анализа с помощью модели.
Следующий этап в разработке – это создание модели с помощью инструментов Python или Spark или же систем анализа данных.
Модель строится на различных алгоритмах машинного обучения с целью анализа и извлечения полезной информации из данных. Этот этап может разрабатываться независимо от этапа обработки данных, но стоит учитывать формат выходных данных этого этапа.
Последний этап разработки включает в себя проектирование веб-интерфейса или интерфейса приложения и взаимодействия с результатами анализа. На этом этапе пользователю доступны различные графики, шкалы и другие индикаторы, а также цифровые показатели, которые будут визуально восприниматься.
На этом этапе важно, чтобы интерфейс был дружелюбный, графики и шкалы читаемые и самое важное-предоставляли информацию в простой, понятной форме.
Эти этапы являются важнейшими в построении системы по обработке больших данных, каждый этап является отдельным проектом, но в совокупности эти проекты образуют систему, которая предоставляет ценные данные на основе действий, которые пользователь совершает ежедневно.
Литература
1. White T. Hadoop: The Definitive Guide. – U.S.A.: O’Reilly Media, 2015. – 768 с.
2. Лем Ч. Hadoop в действии. − М.: ДМК Пресс, 2012. – 424 с.
3. Исламов А.Ш., Артемов М.А., Барановский Е.С., Киргинцев М.В. Обработка больших объемов данных на основе MapReduce // Информатика: проблемы, методология, технологии. Материалы XV международной научно-методической конференции: в 3-х томах. Министерство образования и науки РФ; Воронежский государственный университет, Факультет компьютерных наук; Торгово-промышленная палата Воронежской области; Департамент образования, науки и молодежной политики Воронежской области; Департамент связи и массовых коммуникаций по Воронежской области. 2015. С. 78-80.