Трактовка информации как меры уменьшения неопределенности некоторого случайного процесса дает возможность, используя математический аппарат теории вероятностей, ввести единицу измерения информации. Это весьма важно как с точки зрения развития ее как научной дисциплины, так и с точки зрения практического использования, для понимания процессов передачи и хранения информации [6,21]
Оказывается, вероятность конкретного исхода некоторого события непосредственно связана с количеством информации, содержащимся в сообщении об этом исходе.
СЛУЧАЙНЫЕ ВЕЛИЧИНЫИ СЛУЧАЙНЫЕ СОБЫТИЯ. Событие называется случайным, если неопределенным является исход данного события, т.е. исход его невозможно заранее предсказать. Так, если в качестве случайного события выступает такое природное явление как паводок, то его параметрами будут максимальный уровень поднятия воды, длительность и площадь затопления и т.д. Очевидно, что нельзя заранее абсолютно точно предсказать, каков будет исход данного события в будущем году, а именно, какие значения примут отдельные параметры паводка (например, когда будет пик паводка). В этом случае данные параметры являются величинами случайными. Таким образом, помимо случайных событий имеют место также и случайные величины.
Случайные величины могут быть дискретными и непрерывными. Случайная величина называется непрерывной, если она может принимать любое значение из заданного интервала (а, b) в соответствии со своей функцией распределения. Случайная величина называется дискретной, если она может принимать дискретное множество значений x1, x2,..., хn соответствии со своей таблицей распределения. Само случайное событие также можно рассматривать в качестве дискретной случайной величины x, принимающей два значения: x=1 – событие имеет место, x=0 – событие не имеет место в данный момент времени.
ВЕРОЯТНОСТЬ СЛУЧАЙНОГО СОБЫТИЯ. Рассмотрим событие, представляющее Вашу поездку на работу. Допустим, что возможны три исхода данного события:
1. поездка на общественном транспорте без пересадок,
2. поездка на общественном транспорте с пересадкой,
3. поездка на такси.
При поездке на общественном транспорте без пересадок Ваши денежные затраты составляют 6 рубля, при поездке на общественном транспорте с пересадкой – 12 рублей, при поездке на такси – 80 рублей. Очевидно, что Ваши денежные затраты на одну поездку можно рассматривать в качестве дискретной случайной величины x, принимающей три значения: x1=6, x2=12, x3=80.
Если допустить, что в течение достаточно большого периода наблюдения нормативные число единиц общественного транспорта в городе и интервалы движения между ними остаются неизменными, то с увеличением числа наблюдений частота v наступления конкретного исхода события будет мало меняться. Здесь под частотой v понимается отношение числа п возможных исходов данного события к общему числу наблюдений N, т.е. v=n/N.
Например, по результатам 1000 поездок на работу (N =1000) Вы 650 раз (n1 =650) добирались на работу без пересадок, 300 раз (n2 =300) Вы добирались на работу с пересадками и 50 раз (n3= 50) Вы воспользовались такси. Тогда частота первого исхода (поездка на общественном транспорте без пересадок) события равна v1 = 0,65; частота второго исхода (поездка на общественном с пересадкой) события равна v2 =0,3; частота третьего исхода (поездка на такси) равна v3 =0,05.
Если при увеличении числа N наблюдений частота v конкретного исхода события будет стремиться к некоторому постоянному значению р, то это означает, что событие обладает статистической устойчивостью, а само значение р называется вероятностью данного исхода события, т.е. p = v при N®¥.
Применительно к нашему примеру можно сказать, что вероятность p1 первого исхода события (и соответственно вероятность денежных затрат в размере x1=6) равна 0,65, вероятность p2 второго исхода (и соответственно вероятность денежных затрат в размере x2=12) равна 0,3, вероятность р3 третьего исхода (и соответственно вероятность денежных затрат в размере x3 =80) равна 0,05.
Совокупность пар (x1, p1), (x2, p2),(x3, p3),определяющих дискретную случайную величину x (представляющую собой Ваши денежные затраты на поездку) удобно, представить в виде таблицы (табл.2.3):
Таблица 2.3
| x | |||
| p | 0,65 | 0,3 | 0,05 |
Отметим, что поскольку возможен только один вариант исхода Вашей поездки на работу, то сумма вероятностей данных исходов всегда равна 1, т.е. p1 + p2 + p3 = 0,65+0,3+0,05=1.
В общем случае любая дискретная случайная величина x, принимающая множество значений x1, x2,…, xn может быть задана в виде таблицы (табл.2.4):
Таблица 2.4
| x | x1 | x2 | … | xn |
| p | p1 | p2 | … | pn |
Здесь pi=P{ x= xi} –вероятность того, что случайная величина x, примет значение xi; при этом p1 + p2 +…+ pn=1.
МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ СЛУЧАЙНОЙ ВЕЛИЧИНЫ. Поскольку случайная величина может принимать множество значений, то для числовой их характеристики вводится понятие математического ожидания случайной величины или среднего ее значения. Математическое ожидание случайной величины представляет собой число, около которого группируются все ее возможные значения.
Пусть имеется некоторая дискретная случайная величина x, заданная таблицей 2.4. Тогда математическое ожидание M [x]случайной величины x, подсчитывается по формуле (2.2):
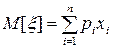
 (2.2)
(2.2)
Обратимся к приведенному выше примеру, касающемуся возможных исходов поездки на работу, и возьмем в качестве случайной величины x, – финансовые затраты на одну поездку. (Данная случайная величина задается таблицей 2.3.).
Для этого случая математическое ожидание M [x]=0,65(6)+0,3(12)+0,05(80)=11,5. Смысл математического ожидания для этого примера заключается в том, что в среднем Вы будете тратить на одну поездку 11 рублей 50 копеек. Эта сумма может служить основой для планирования Ваших годовых затрат на поездку на работу.
Вернемся вновь к связи количества информации, которое содержится в сообщении об исходе некоторого события, и вероятности исхода данного события. Считается, что чем более вероятен конкретный исход события, тем меньше информации несет сообщение об этом исходе. Математически это записывается так:
 (2.3)
(2.3)
где 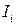 , – количество информации, содержащееся в сообщении об i -ом исходе события, q – основание логарифма.
, – количество информации, содержащееся в сообщении об i -ом исходе события, q – основание логарифма.
Это вполне согласуется с практическими соображениями. Так, возвращаясь к приведенному выше примеру, заметим, что сообщение о том, что Вы ехали на работу на общественном транспорте и без пересадок (вероятность данного исхода равна 0,65) несет гораздо меньше информации, чем сообщение о том, что Вы добирались на работу на такси (вероятность данного исхода равна 0,05). Поскольку 0,65 много больше, чем 0,05, то еще до начала Вашей поездки на работу можно было ожидать, что Вы скорее всего доедете на работу на общественном транспорте без пересадок, нежели Вы доберетесь на работу на такси.
Из формулы (2.3) видно, что чем больше будет вероятность  исхода конкретного события, тем меньше будет величина
исхода конкретного события, тем меньше будет величина  , и, следовательно, тем меньшее количество информации будет содержаться в информации об исходе данного события. Обычно, полагают q=2 или q=e, т.е. используют логарифмы с основанием 2 (
, и, следовательно, тем меньшее количество информации будет содержаться в информации об исходе данного события. Обычно, полагают q=2 или q=e, т.е. используют логарифмы с основанием 2 ( ) или натуральные логарифмы (
) или натуральные логарифмы ( ).
).
В информатике для подсчета количества информации используются только логарифмы по основанию 2, а число п возможных исходов события полагается равным 2k (т.е. является степенью числа 2). Связано это с особенностями аппаратной реализации современных компьютеров.
Можно ввести в рассмотрение случайную величину I, представляющую собой количество информации, содержащееся в сообщении о конкретном исходе того или иного события. В соответствии с формулой (2.3) данная случайная величина может быть задана следующей таблицей (табл.2.5):
Таблица 2.5
| I | 
| 
| … | 
|
| p | 
| 
| … | 
|
Поскольку случайная величина I может принимать множество значений в зависимости от того или иного исхода события, то для ее числовой характеристики (количества информации I в произвольном сообщении об исходе случайного события) принимается ее математическое ожидание или среднее значение. В соответствии с формулой (2.2) математического ожидания случайной величины количество информации I, содержащееся в сообщении об исходе случайного события, равно:
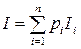 (2.4)
(2.4)
или с учетом формулы (2.3)
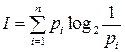 . (2-5)
. (2-5)
Формула (2.5) для определения количества информации в сообщении об исходе случайного события была предложена К. Шенноном.
Для определения количества информации, содержащегося в сообщении об исходе случайного события в случае, когда все исходы равновероятны, т.е.  , формула (2.5) принимает вид (Р. Хартли – 1928 г.):
, формула (2.5) принимает вид (Р. Хартли – 1928 г.):
 . (2.6)
. (2.6)
В качестве единицы количества информации, подсчитываемой по формуле (2.6), принят 1 бит. Смысл его как элементарной единицы уменьшения неопределенности заключается в том, что данное минимально возможное количество информации содержится в сообщении об исходе случайного события с двумя равновероятными исходами. Так, полагая в формуле (2.6) п=2 и  получим:
получим:
 (бит).
(бит).
Проиллюстрируем это на следующих примерах. Пусть нам нужно передать информацию об исходе следующих событий.
1. Бросание одной монеты. До момента бросания монеты имеется неопределенность исхода данного события, смысл которой заключается в том, что потенциально возможны два варианта исходов бросания, т.е. п=2 (табл. 2.6):
Таблица 2.6
| Вариант | Исход бросания | Код сообщения |
| «орел» | ||
| «решка» |
В этом случае закодированное информационное сообщение представляет собой последовательность из одного двоичного символа (табл. 2.6). В этом случае любое из этих двух сообщений (0 или 1) уменьшает неопределенность ровно в два раза. Применяя для данного примера формулу (2.6), получим:
(бит).
Таким образом, сообщение об исходе бросания одной монеты несет в себе количество информации, равное 1 биту. Иными словами, 1 бит есть та минимальная порция информации, которая уменьшает исходную неопределенность в два раза в линейном масштабе.
2. Бросание одновременно трех монет. До момента бросания монет имеется неопределенность исхода данного события, смысл которой заключается в том, что потенциально возможны восемь вариантов исходов бросания, т.е. n =8 (табл. 2.7):
Таблица 2.7
| Вариант | 1-я монета | 2-я монета | 3-я монета | Код Сообщения |
| «орел» | «орел» | «орел» | ||
| «решка» | «решка» | «решка» | ||
| «орел» | «решка» | «решка» | ||
| «орел» | «орел» | «решка» | ||
| «орел» | «решка» | «орел» | ||
| «решка» | «орел» | «орел» | ||
| «решка» | «решка» | «орел» | ||
| «решка» | «орел» | «решка» |
В этом случае закодированное информационное сообщение представляет собой последовательность из трех двоичных символов (табл. 2.1). Применяя для рассматриваемого примера формулу (2.6), получим:
 (бит).
(бит).
Таким образом, любое сообщение об исходе бросания трех монет несет в себе количество информации, равное трем битам, т.е. уменьшает неопределенность об исходе данного события ровно в восемь раз (в линейном масштабе).
Интересно, что согласно классической теории информации, сообщение об исходе бросания одновременно трех монет несет в себе в три раза больше информации (в логарифмическом масштабе), чем сообщение об исходе бросания одной монеты (3 бита и 1 бит).
Следует отметить, что в компьютерной технике при передаче сообщений по линиям связи в качестве случайных событий выступают передаваемые последовательности нулей и единиц, представляющие собой закодированные (т.е. представленные в цифровой форме текстовые, числовые, графические, звуковые и другие сообщения Данные последовательности имеют различную (случайную) длину и различный (случайный) характер чередования нулей и единиц.
Практически все передаваемые сообщения обладают большей или меньшей степенью информационной избыточности. Именно на этом свойстве передаваемой информации основана возможность ее сжатия, которая в настоящее время используется повсеместно [32].
Это означает, что возможные различные виды данных последовательностей (отличающиеся длиной и характером чередования нулей и единиц) не являются равновероятными. Так, особенностью текстовых сообщений на русском языке является гораздо большая частота наличия буквы о, чем, например, буквы ф, наименьшую частоту в русских текстовых сообщениях имеет буква ъ, то есть на практике значения случайных последовательностей, передаваемых по линиям, имеют закон распределения, отличный от равномерного.
Если под исходом случайного события понимать конкретный вид последовательности нулей и единиц в передаваемом сообщении, то данные исходы не являются равновероятными и, следовательно, для определения количества содержащейся в них информации нельзя использовать формулу Хартли. Как следствие, в этом случае нельзя использовать в качестве единицы информации 1 бит.
Таким образом, единица измерения 1 бит малопригодна на практике для определения количества информации, содержащейся в сообщении в классическом понимании этого термина (мера уменьшения неопределенности). Гораздо чаще, если не всегда, в компьютерной технике бит выступает в качестве элементарной единицы количества или объема хранимой (или передаваемой) информации безотносительно к ее содержательному смыслу.
Память компьютера состоит из элементарных ячеек (триггеров), в каждой из которых может быть записан либо логический ноль, либо логическая единица. Если число таких триггеров равно п, то количество всевозможных комбинаций нулей и единиц в п ячейках (их в данном случае формально можно рассматривать в качестве равновероятных исходов событий) равно  . Применяя в данном случае формулу Хартли (2.6), получим, что в п ячейках памяти можно хранить п бит информации. Очевидно, что количество информации, которое можно хранить в одной ячейке памяти (n =1), равняется 1 биту. Количество информации в 1 бит является слишком малой величиной, поэтому наряду с единицей измерения информации 1 бит, используется более крупная единица 1 байт, 1байт=23 бит=8 бит.
. Применяя в данном случае формулу Хартли (2.6), получим, что в п ячейках памяти можно хранить п бит информации. Очевидно, что количество информации, которое можно хранить в одной ячейке памяти (n =1), равняется 1 биту. Количество информации в 1 бит является слишком малой величиной, поэтому наряду с единицей измерения информации 1 бит, используется более крупная единица 1 байт, 1байт=23 бит=8 бит.
В настоящее время в компьютерной технике при хранении и передаче информации используются в качестве единиц объема хранимой (или передаваемой) информации более крупные единицы:
1 килобайт (1 Кбайт) = 210 байт = 1024 байт,
1 мегабайт (1 Мбайт) = 210 Кбайт = 1024 Кбайт,
1 гигабайт (1 Гбайт) = 210 Мбайт= 1024 Мбайт,
1 терабайт (1 Тбайт) = 210 Гбайт= 1024 Гбайт,
1 петабайт (1 Пбайт) = 210 Тбайт= 1024 Тбайт.
В компьютерной и телекоммуникационной технике в битах, байтах, килобайтах, мегабайтах и т.д. измеряется также потенциальная информационная ёмкость оперативной памяти и запоминающих устройств, предназначенных для хранения данных (жесткие диски, дискеты, CD-ROM и т.д.).
Для хранения и обработки информации в компьютере используется совокупность определенного количества разрядов, которая называется разрядной сеткой. При этом число элементарных разрядов п, с которыми компьютер оперирует как с одним целым (считывает из памяти, производит вычисления), характеризует разрядность его элементов (например, всевозможных регистров процессора, запоминающих устройств).
Как известно, группа из восьми соседних элементарных ячеек (регистров) называется байтом. Часто в компьютерной технике бит и байт используется в качестве информационного эквивалента его разрядности, так, 8-разрядный регистр называют байтом. Байт является минимальной адресуемой единицей оперативной памяти, поэтому число разрядов оперативной памяти кратно 8. С помощью одного байта можно закодировать 28=256 различных букв, цифр или положительных чисел в диапазоне от 0 до 255.
Возможности байта для кодирования данных ограничены из-за слишком малой разрядности. Поэтому компьютеры устроены так, что они могут оперировать не только с одним байтом, но также и с группами из двух, четырех, восьми и т.д. соседних байт.
Таблица 2.8
| Байт | Байт | Байт 2 | Байт | Байт | Байт 5 | Байт 6 | Байт |
| Полуслово | Полуслово | Полуслово | Полуслово | ||||
| СЛОВО | СЛОВО | ||||||
| ДВОЙНОЕ СЛОВО |
Подобные группы байт принято называть (в зависимости от архитектуры компьютера) словом, полусловом, двойным словом. В большинстве случаев словом называют группу из четырех соседних байт, группу из двух соседних байт – полусловом, группу из восьми соседних байт – двойным словом (см. таблицу 2.8). Такие единицы используются в основном для представления числовой информации.