В пакет Fuzzy Logic Toolbox входит еще одна программа, позволяющая работу в режиме графического интерфейса, — программа Clustering (Кластеризация) выявления центров кластеров, т.е. точек в многомерном пространстве данных, около которых группируются (скапливаются) экспериментальные данные. Выявление подобных центров, надо сказать, является значимым этапом при предварительной обработке данных, поскольку позволяет сопоставить с этими центрами функции принадлежности переменных при последующем проектировании системы нечеткого вывода.
Запуск программы Clustering осуществляется командой (функцией) findcluster. В появляющемся окне программы имеется (вверху) главное меню, содержащее достаточно стандартный набор пунктов (File, Edit, Window, Help) и набор управляющих кнопок и опций (справа). К этим кнопкам относятся:
• кнопка загрузки фала данных Load Data,
• кнопка выбора алгоритма кластеризации — Method,
• четыре расположенные ниже кнопки опций алгоритма (их названия меняются в зависимости от выбранного алгоритма),
• кнопка начала итеративного процесса нахождения центров кластеров (кластеризации) — Start,
• кнопка сохранения результатов кластеризации (SaveCenter),
• кнопка очистки (стирания) графиков (Clear Plot),
• кнопка справочной информации (Info),
• кнопка завершения работы с программой (Close).
В программе используются два алгоритма выявления центров кластеров: Fuzzy c-means (который можно перевести как «Алгоритм нечетких центров») и Subtractive clustering («Вычитающаякластеризация»).

Рис. 7. Результат работы программы Clustering (центры кластеров окрашены в черный цвет)
Если не вдаваться в их детальное теоретическое изложение, а ограничиться выявлением различий на уровне пользователя, то можно отметить, что алгоритм Fuzzy c-means, являясь, пожалуй, более точным (если понятие точности вообще здесь применимо), для своей работы требует задания таких опций, как число кластеров (кнопка Cluster num.) и число итераций (кнопка Max Iteration^). Ну, если число итераций еще можно задать как-то наугад, то ошибка в задании числа кластеров может привести к неприятным последствиям. Алгоритм Subtrac-tive clustering менее точен, но и менее требователен к априорной информации; при работе с ним можно сохранить опции, заданные в программе по умолчанию. На рис. 7 приведен пример использования программы для фала данных clusterdemo.dat из директории Matlab/toolbox/fuzzy/fuzdemos/ при использовании алгоритма Subtractive clustering. Заметим, что выводится только двумерное поле рассеяния, но изменяя переменные в соответствующих полях (X-axis и Y-axis), можно «просмотреть» все многомерное пространство переменных.
Индивидуальные задания
Аппроксимировать при помощи гибридной сети уравнения вида y=f(x) по десяти точкам.
Таблица
| № | f(x) |

| |

| |

| |

| |

| |

| |

| |

| |

| |

| |

| |
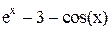
|
Отчёт по лабораторной работе включает в себя:
· титульный лист;
· листы выполнения работы (цель работы, практическая часть, вывод, список литературы).
Практическая часть сопровождается таблицами, графиками с кратким пояснением хода выполнения лабораторной работы. Обязательно приводится описание параметров модели, можно распечатать экранные формы с пояснениями.
Контрольные вопросы
Литература
1. Осовский С., Нейронные сети для обработки информации / Пер. с польского И.Д.Рудинского. – М.: Финансы и статистика, 2002.
2. Джонс М.Т. Программирование искусственного интеллекта в приложениях. - М. ДМК Пресс, 2004.