Приложение В
| Продолжение табл, Б.2.2 | |||||
| Ю L | Ю 9 | ||||
| . 10 | |||||
| И | |||||
| И | И | ||||
| !2 | |||||
| П | |||||
| Средняя | 13,4 | 12,7 | Средняя | 14,06 | 17,9 |
| Стандарт- | Стандарт- | ||||
| ное от- | нос от- | ||||
| клонение | 2,29 | 2,09 | клонение | 2,28 | 2,97 |
| Девушки: Д1-Д14 | т Юноши: Ю1\Ю16 | ||||
Описательная статистика
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции.
Группировка данных
Для группировки необходимо прежде всего расположить данные каждой выборки в возрастающем порядке. Так, в нашем эксперименте для переменной «число пораженных мишеней» данные будут располагаться следующим образом:
| Опытная группа (дополнить цифрами} | |||||||||||||||||
| Фон:................... *...............•. - •...... | |||||||||||||||||
| Пост воздействия;.....,.,,,,*...,.;,,,........м........ *......... | |||||||||||||||||
| Контрольная группа | |||||||||||||||||
| Фон: | |||||||||||||||||
| После voatintCTBMif: |
Статистика и обработка Данных 283
Распределение частот (числа пораженных мишеней)
Уже при первом взгляде не получение ряды можно заметить, что многие данные принимают одни и те же значения, причем одни значения встречаются чаще, а другие-реже. Поэтому было бы интересно вначале графически представить распределение различных значений с учетом их частот. При этом получают следующие столбиковые диаграммы:
Контрольная группа
После воздействий (дополнить столбиками!
Опытная группа
| 1Э | £0 | |||||||||||||
| Фон |
После воздействии {дополнить столбиками)
Такое распределение данных по их значениям дает нам уже гораздо больше, чем представление в виде радов. Однако подобную группировку используют в основном лишь для качественных данных, четко разделяющихся на обособленные категории (см. дополнение Б. I),
Что касается количественных данных, то они всегда располагаются на непрерывной шкале и, как правило, весьма многочисленны. Поэтому такие данные предпочитают группировать по классам, чтобы яснее видна была основная тенденция распределениям
Такая группировка состоит в основном в том, что объединяют данные с одинаковыми или близкими значениями в классы и определяют частоту для каждого класса. Способ разбиения на классы зависит от того, что именно экспериментатор хочет выявить при разделении измерительной шкалы на равные интервалы. Например, в нашем случае можно сгруппировать данные по классам с интервалами в две или три единицы шкалы:
| X | • | X | ||||||||||||||||||||||||||||||||||||||||||||||||||
| X | X | X | X | |||||||||||||||||||||||||||||||||||||||||||||||||
| X | X | X | X | X | х | X | X | X | ||||||||||||||||||||||||||||||||||||||||||||
| £2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Фом | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| (У | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| л. | ||||||||||||||||||||||||||||||||||||||||||||||||||||
| Приложение | Б | |||||||||||||
| Контрольная групп* | ||||||||||||||
| X | ||||||||||||||
| X | X | |||||||||||||
| X | X | ж | ||||||||||||
| X | X | X | X | X | X | |||||||||
| X | X | х | X | X | X | X | ||||||||
| X X | X | X | * х | X | X | X X | ||||||||
| Клксы | 10-11 | 12-13 | 14 15 | ieir | 13-19 | 20-21 | гг-га | 9-1 | 12-14 | 15-17 | 16-го | 21-23 | ||
| Частоты | е | э | г | А | ||||||||||
| Фон | Фан | |||||||||||||
| (с интервалами в 2 ъд.\ | (с интервалами в, 3 вд,} |
(заполнить таким же образом)
_
Выбор того или иного типа группировки зависит от различных соображений. Так, в нашем случае группировка с интервалами между классами в две единицы хорошо выявляет распределение результатов вокруг центрального «пика». В то же время группировка с интервалами в три единицы обладает тем преимуществом, что дает более обобщенную и упрощенную картину распределения* особенно если учесть, что число элементов в каждом классе невелико1. Именно поэтому в дальней* шем мы будем оперировать классами в три единицы.
Опытная групп*
| Классы | в-10 | |||||
| Частоты | ||||||
| Фон | ||||||
| Классы | 5-7 | |||||
| Частоты |
После воздействий (с интервалами в 3 ед.)
Данные, разбитые на классы по непрерывной шкале, нельзя представить графически так, как это сделано выше. Поэтому предпочитают
1 При большом количестве данных число классов по возможности должно быть где-то в пределах от 10 ло 20, с интервалами до 10 и более.
| Классы | а-э | |||||||||||||
| Частоты | ||||||||||||||
| • | После воздействия {с интервалами в 2 ед.) | После воздействия (с интервалами в 3 ед-1 |
"_____________Статистика и обработка данных____________285
использовать так называемые гистограммы-способ графического
представления в виде примыкающих друг к другу прямоугольников:
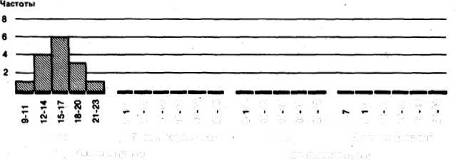
Фон Поел* воздействия Фон После воздействия
Опытная группа Контрольная групп*
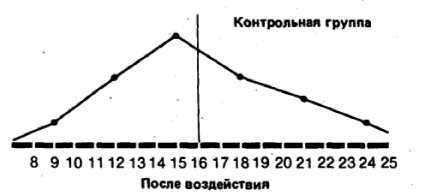
Наконец, для еще более наглядного представления общей конфигурации распределения можно строит полигоны распределения частот. Для этого отрезками прямых соединяют центры верхних сторон всех прямоугольников гистограммы, а затем с обеих сторон «замыкают» площадь под кривой, доводя концы полигонов до горизонтальной оси (частота = 0) в точках, соответствующих самым крайним значениям распределения. При этом получают следующую картину:
Частоты
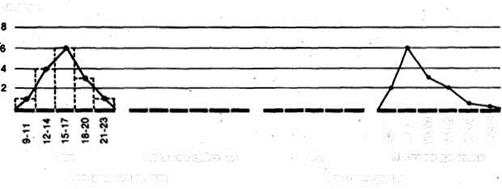
Контрольная группа Опытная группа
Если сравнить полигоны, например, для фоновых (исходных) значений контрольной группы и значений после воздействия для опытной группы, то можно будет увидеть, что в первом случае полигон почти симметричен (т. е, если сложить полигон вдвое по вертикали, проходящей через его середину, то обе половины наложатся друг на друга)* тогда как для экспериментальной группы он асимметричен и смещен влево (так что справа у него как бы вытянутый шлейф).
Полигон для фоновых данных контрольной группы сравнительно близок к идеальной кривой, которая могла бы получиться для бесконечно большой популяции. Такая кривая -кривая нормального распределения -имеет колоколообразную форму я строго симметрична. Если же количество данных ограничено (как в выборках, используемых для научных исследований), то в лучшем случае получают лишь некоторое приближение (аппроксимацию) к кривой нормального распределения.
Приложение f>
Если вы построите полигон для фоновых значений опытной группы и значений после воздействия для контрольной группы, то вы наверняка заметите, что так же будет обстоять дело и в этих случаях.
Оценка центральной тенденции
Если распределения для контрольной группы и для фоновых значений в опытной группе более или. менее симметричны, то значения, получаемые в опытной группе после воздействия, группируются, как уже говорилось, больше в левой части кривой. Это говорит о том, что после употребления марихуаны выявляется тенденция к ухудшению показателей у большого числа испытуемых.
Для того чтобы выразить подобные тенденции количественно, используют три вида показателей моду, медиану и среднюю.
1. Мода (Мо)-это самый простой из всех трех показателей. Она соответствует либо наиболее частому значению, либо среднему значению класса с наибольшей частотой. Так, в нашем примере для экспериментальной группы мода для фона будет равна 15 (этот результат встречается четыре раза и находится в середине класса 14-15-16), а после воздействия (середина класса 8-910),
Мода используется редко и главным образом для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды; тогда говорят о бимодальном распределении. Такая хартина указывает на то> что в данном совокупности имеются две относительно самостоятельные группы (см,, например, данные Триона, приведенные в документе 3.5).

Бимодальное распределение
*
2, Медиана (Me) соответствует центральному значению в последовательном ряду всех полученных значений. Так, для фона в экспериментальной группе, где мы имеем ряд
10 11 12 13 14 14 15 15 15 15 17 17 19 20 21,
медиана соответствует 8-му значению, т.е. 15. Для результатов воздействия в экспериментальной группе она равна 10.
В случае если число данных п, четное, медиана равна средней арифметической между значениями, находящимися в раду на л/2-м и я/2 + 1-м местах. Так, для- результатов воздействия для восьми юношей опытной группы медиана располагается между значениями, находящимися на 4-м (8/2 = 4) и 5-м местах в ряду. Если выписать весь
Статистика и обработка данных
2У7
ряд для этих данных;, а именно
7 8 9 II 12 13 14 16,
то окажется, что медиана соответствует (II + 12)/2 =11,5 (видно, что медиана не соответствует здесь ни одному из полученных значений),
3. Средняя арифметическая (1Й) (далее просто «средняя») - это наиболее часто используемый показатель центральной тенденции. Ее применяют, в частности, в расчетах, необходимых для описания распределения и для его дальнейшего анализа. Ее вычисляют t разделив сумму всех значений данных на число этих данных. Так, для нашей опытной группы она составит- 15,2(228/15) для фона и 11,3(169/15) для результатов воздействия.
Если теперь отметить все эти три параметра на каждой из кривых для экспериментальной группы, то будет видно, что при нормальном распределении они более или менее совпадают, а при асимметричном расп ред е л е ни и - нет.
Прежде чем идти дальше, полезно будет вычислить все эти показатели для обеих распределений контрольной группы-они пригодятся нам в дальнейшем:..
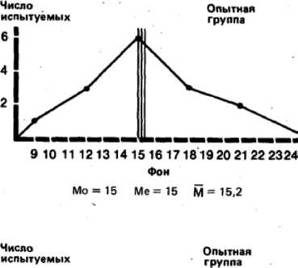
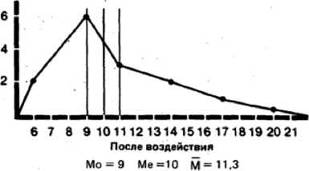
Приложение Б
Оценка разброса
Как мы уже отмечали, характер распределения результатов после воздействия изучаемого фактора в опытной группе дает существенную информацию о том, как испытуемые выполняли задание. Сказанное относится и к обоим распределениям в контрольной группе:
Контрольная группа Мода (Мо) Мели* не (Me) Средни а (м)
| Фон:................. |
| После воздействия: ч • - •:....... • •......• •,...••.«••-. |
Сразу бросается в глаза, что если средняя в обоих случаях почти одинакова, то во втором распределении результаты больше разбросаны, чем в первом, В таких случаях говорят, что у второго распределения больше диапазон, или размах вариаций, т.е, разница между максимальным и минимальным значениями.
Так, если взять контрольную группу, то диапазон распределения для фона составит 22 — 10 = 12, а после воздействия 25 — 8 — 17. Это позволяет предположить, что повторное выполнение задачи на глазодвигательную координацию оказало на испытуемых из контрольной группы определенное влияние; у одних показатели улучшились, у других ухудшились1. Однако для количественной оценки разброса результатов
1 Здесь мог проявиться эффект плацебо связанный с тем, что запах дыма травы вызвал у испытуемых уверенность в том, что они находятся под воздействием наркотика. Для проверки этого предположения следовало бы повторить эксперимент со второй контрольной группой, в которой испытуемым будут давать только обычную сигарету.

u /lOfHtonmKit thmiwx
относительно средней в том или ином распределении существуют более точные методы, чем измерение диапазона.
Чаще всего для оценки разброса определяют отклонение каждого из полученных значений от средней (М-М)> обозначаемое буквой d, а затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Напротив, если эта средняя невелика, то данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
Итак, первый показатель, используемый для оценки разброса,-это среднее отклонение. Его вычисляют следующим образом (пример, который мы здесь приведем, не имеет ничего общего с нашим гипотетическим экспериментом). Собрав все данные и расположив их в ряд
3 5 6 9 11 14,
находят среднкУю арифметическую для выборки:
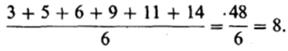
Затем вычисляют отклонения каждого значения от средней и суммируют их:
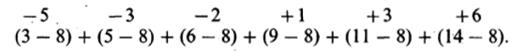
Однако при таком сложении отрицательные и положительные отклонения будут уничтожать друг друга, иногда даже полностью, так что результат (как в данном примере) может оказаться равным нулю. Из этого ясно, что нужно находить сумму абсолютных значений индивидуальных отклонений и уже эту сумму делить на их общее число. При этом получится следующий результат:
среднее отклонение равно
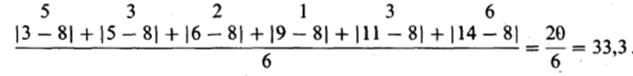
Общая формула:

где 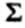 (сигма) означает сумму; \d\- абсолютное значение каждого индивидуального отклонения от средней; «-число данных.
(сигма) означает сумму; \d\- абсолютное значение каждого индивидуального отклонения от средней; «-число данных.
Однако абсолютными значениями довольно трудно оперировать в алгебраических формулах* используемых в более сложном статистическом анализе. Поэтому статистики решили пойти по «обходному пути», позволяющему отказаться от значений с отрицательным знаком, а именно возводить все значения в квадрат, а затем делить сумму квадратов на
19-443
flfHLtlKXCVIttlC Л
число данных. В нашем примере это выглядит следующим образом:
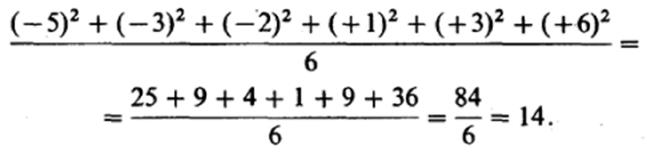
В результате такого расчета получают так называемую варианеу1* Формула для вычисления вариансы, таким образом, следующая:
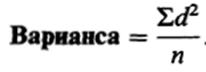
Наконец, чтобы получить показатель, сопоставимый по величине со средним отклонением, статистики решили извлекать из вариансы квадратный корень. При этом получается так называемое стандартное отклонение:

В нашем примере стандартное отклонение равно 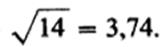
Следует еще добавить* что для того, чтобы более точно оценить стандартное отклонение для малых выборок (с числом элементов менее 30), в знаменателе выражения под корнем надо использовать не /г, а п — 1:
-

Вернемся теперь к нашему эксперименту и посмотрим, насколько полезен оказывается этот показатель для описания выборок.
На первом этапе, разумеется, необходимо вычислить стандартное
Г
1 Варнанса представляет собой один из показателей разброса, используемых в некоторых статистических методиках (например, при вычислении критерия F; см, следующий раздел). Следует отметить, что в отечественной литературе варианту часто называют дисперсией.-Прим. rtepee.
* Стандартное отклонение для популяции обозначается маленькой греческой буквой сигма 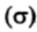 , а для выборки - буквой s. Это касается и вариансы, т.е. квадрата стандартного отклонения: для популяции она обозначается
, а для выборки - буквой s. Это касается и вариансы, т.е. квадрата стандартного отклонения: для популяции она обозначается 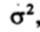 , а для выборки -
, а для выборки - 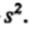
tt vtipafwniKct
отклонение для всех четырех распределений. Сделаем это сначала для фона опытной группы:
Расчет стандартного отклонения1 для фона контрольной группы
Испытуемые Число пора* Средняя женных мише-ней в серии
Отклоне- Квадрат от-
кие от клонздия от
средней (*/) средней (dl)
| 2 3 | 10 12 • | 15,8 15,8 15,8 | -ЗД + 5,8 + 3,8 | 10,24 33,64 14,44 |
| - | - | - 15,8 | -6,2 | г 38,44 |
Сумма
Стандартное отклонение
1 Формула для расчетов н сами расчеты приведены здесь лишь в качестве иллюстрации. В наше время гораздо проще при об* рести такой карманный микрокалькулятор, в котором подобные расчеты уже заранее запрограммированы, и для расчета стандартного отклонения достаточно лишь ввести данные, а затем нажать клавишу s.
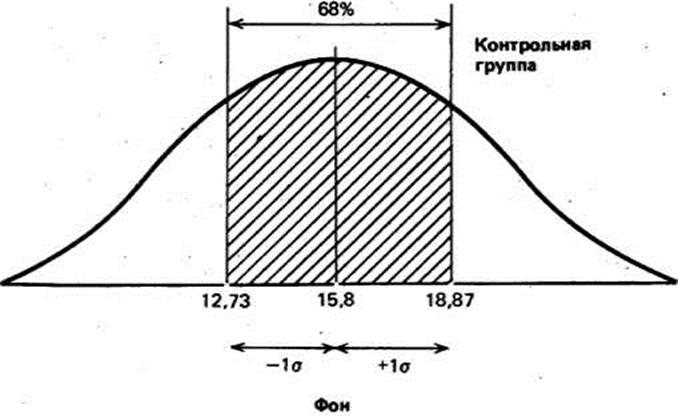
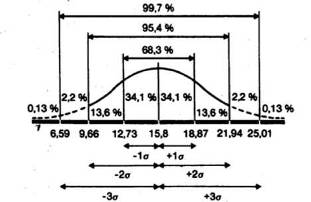
О чем же свидетельствует стандартное отклонение, равное 3,07? Оказывается, оно позволяет сказать, что большая часть результатов (выраженных здесь числом пораженных мишеней) располагается в пределах 3,07 от средней, т.е. между 12,73 (15,8 - 3,07) и 18,87 (15,8 4- 3,07),
Для того чтобы лучше понять, что подразумевается под «большей частью результатов», нужно сначала рассмотреть те свойства стандартного отклонения, которые проявляются при изучении популяции с нормальным распределением.
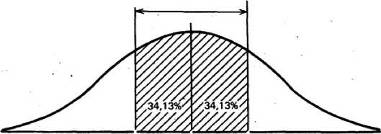
Статистики показали, что при нормальном распределении «большая часть» результатов, располагающаяся в пределах одного стандартного отклонения по обе стороны от средней, в процентном отношении всегда одна и та же и не зависит от величины стандартного отклонения: она соответствует 68% популяции (т, е. 34% ее элементов располагается слева и 34%-справа от средней):


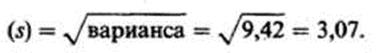
При.южеши* Б
6ЭГ27%
М-0 М М+о
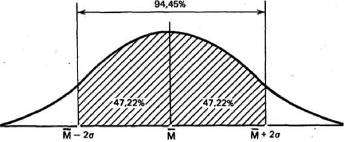
Точно гак же рассчитали, что 94,45% элементов популяции при нормальном распределении не выходит за пределы двух стандартных отклонений от средней:
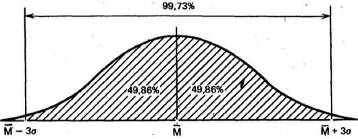
и что в пределах трех стандартных отклонений умещается почти вся популяция-99,73%.
Учитывая, что распределение частот фона контрольной группы довольно близко к нормальному, можно полагать, что 68% членов всец популяции, из которой взята выборка, тоже будет получать сходные результаты, т,е, попадать примерно в 13-19 мишеней из 25, Распределение результатов остальных членов популяции должно выглядеть следующим образом;
Статистики tt обработка данных
Гипотетическая популяция,
из которой взята контрольная группа (фон)
Что касается результатов той же группы после воздействия изучаемого фактора, то стандартное отклонение для них оказалось равным 4,25 (пораженных мишеней). Значит, можно предположить, что 68% результатов будут располагаться именно в этом диапазоне отклонений от средней, составляющей 16 мишеней, т. е. в пределах от 11,75 (16 — 4,25) до 20,25 (16 + 4,25), или, округляя, 12 — 20 мишеней из 25. Видно, что здесь разброс результатов больше, чем в фоне. Эту разницу в разбросе между двумя выборками для контрольной группы можно графически представить следующим образом:
Приложение И
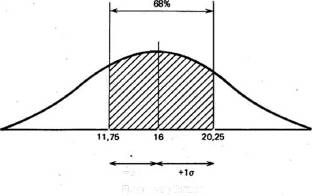
-t<7
После воздействия
Поскольку стандартное отклонение всегда соответствует одному и тому же проценту результатов, укладывающихся в его пределах вокруг средней, можно утверждать, что при любой форме кривой нормального распределения та доля ее площади, которая ограничена (с обеих сторон) стандартным отклонением, всегда одинакова и соответствует одной и той же доле всей популяции. Это можно проверить на тех наших выборках, для которых распределение близко к нормальному,-на данных о фоне для контрольной и опытной групп.
Итак, ознакомившись с описательной статистикой, мы узнали» как можно представить графически и оценить количественно степень разброса данных в том или ином распределении. Тем самым мы смогли понять, чем различаются в нашем опыте распределения для контрольной группы до и после воздействия. Однако можно ли о чем-то судить по этой разнице-отражает ли она действительность или же это просто артефакт, связанный со слишком малым объемом выборки? Тот же вопрос (только еще острее) встает и в отношении экспериментальной группы, подвергнутой воздействию независимой переменной. В этой группе стандартное отклонение для фона и после воздействия тоже различается примерно на 1 (3,14 и 4,04 соответственно). Однако здесь особенно велика разница между средними-15,2 и 11,3* На основании чего можно было бы утверждать, что эта разность средних действительно достоверна, т,е\ достаточно велика, чтобы можно было с уверенностью объяснить ее влиянием независимой переменной, а не простой случайностью? В какой степени можно опираться на эти результаты и распространять их на всю популяцию, из которой взята выборка, т, е. утверждать, что потребление марихуаны и в самом деле обычно ведет к нарушению глазодвигательной координации? -