ОТЧЁТ
Дисциплина: «Основы конструирования трансляторов и интерпретаторов»
Выполнил: магистрант группы № 821-ПРИ Коновской А.О.
Проверил: доц. каф. ИТЗИ, канд. техн. наук Родионов А.С.
Дата выполнения и защиты Оценка__________
«___» октября 2019 г.
Ростов-на-Дону
Лабораторная работа
«Построение лексического анализатора»
Цель работы:
Разработка лексического блока компилятора (лексического анализатора) для языка С# (входной язык), используя грамматику и таблицу лексем данного языка, выходной язык – Java.
Задачи:
Разработать таблицы лексем, для языков программирования C# и Java;
построить блок-схемы отражающую работу лексического анализатора;
Краткие теоретические сведения:
Первая фаза компиляции называется лексическим анализом или сканированием. Лексический анализатор читает поток символов, составляющих исходную программу, и группирует эти символы в значащие последовательности, называющиеся лексемами.
Лексема (логическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т.п.
На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора. Для каждой лексемы анализатор строит выходной токен (token) вида:
‹имя_токена, значение_атрибута›
Он передается последующей фазе, синтаксическому анализу. Первый компонент токена, имя_токена, представляет собой абстрактный символ, использующийся во время синтаксического анализа, а второй компонент, значение атрибута, указывает на запись в таблице символов, соответствующую данному токену. Информация из записи в таблице символов необходима для семантического анализа и генерации кода.
Предположим, например, что исходная программа содержит инструкцию присваивания:
position = initial + rate * 60
Символы в этом присваивании могут быть сгруппированы в следующие лексемы и отображены в следующие токены, передаваемые синтаксическому анализатору.
1. Position представляет собой лексему, которая может отображаться в токен (id 1) где id – абстрактный символ, обозначающий идентификатор, а 1 указывает запись в таблице символов для position. Запись таблицы символов для некоторого идентификатора хранит информацию о нем, такую как его имя и тип.
2. Символ присваивания = представляет собой лексему, которая отображается в токен (=). Поскольку этот токен не требует значения атрибута, второй компонент данного токена опущен. В качестве имени токена может быть использован любой абстрактный символ, например такой, как assign, но для удобства записи в качестве имени абстрактного символа можно использовать саму лексему.
3. Initial представляет собой лексему, которая отображается в токен (id 2) где 2 указывает на запись в таблице символов для initial.
4. + является лексемой, отображаемой в токен (+).
5. Rate – лексема, отображаемая в токен (id 3) где 3 указывает на запись в таблице символов для rate.
6. * – лексема, отображаемая в токен *.
7. 60 – лексема, отображаемая в токен (number 4) где 4 указывает на запись таблицы символов для внутреннего представления целого числа 60.
Пробелы, разделяющие лексемы, лексическим анализатором отбрасываются.
Представление инструкции присваивания после лексического анализа в виде последовательности токенов:
(id, 1) (=) (id, 2) (+) (id, 3) (*) (number, 4)
При этом представлении имена токенов =, + и * представляют собой абстрактные символы для операторов присваивания, сложения и умножения соответственно.
Шаблон (pattern) – это описание вида, который может принимать лексема токена. В случае ключевого слова шаблон представляет собой просто последовательность символов, образующих это ключевое слово.
В таблице 1 приведены некоторые типичные токены, неформальное описание их шаблонов и некоторые примеры лексем. Чтобы увидеть использование этих концепций на практике, в инструкции на языке программирования С:
printf("Total = %d\n", score);
“Printf” и “score” представляют собой лексемы, соответствующие токену id, a "Total = %d\n" является лексемой, соответствующей токену literal.
Таблица 1 – Примеры токенов.

С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического разбора. Однако существует несколько причин, исходя из которых в состав практически всех компиляторов включают лексический анализ:
· упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и выкидывает всю незначащую информацию;
· для выделения в тексте и разбора лексем возможно применять простую, эффективную и теоретически хорошо проработанную технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
· сканер отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходный программы, структура которого может варьироваться в зависимости от версии входного языка – при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой сканер.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка.
В большинстве компиляторов лексический и синтаксический анализаторы – это взаимосвязанные части. Лексический разбор исходного текста в таком варианте выполняется поэтапно так, что синтаксический анализатор, выполнив разбор очередной конструкции языка, обращается к сканеру за следующей лексемой. При этом он может сообщить информацию о том, какую лексему следует ожидать. В процессе разбора может даже происходить «откат назад», чтобы выполнить анализ текста на другой основе. В дальнейшем будем исходить из предположения, что все лексемы могут быть однозначно выделены сканером на этапе лексического разбора.
Работу синтаксического и лексического анализаторов можно изобразить в виде схемы, приведенной на рис.1.

Рисунок 1 – Взаимодействие лексического анализатора с синтаксическим.
В простейшем случае фазы лексического и синтаксического анализа могут выполняться компилятором последовательно. Но для многих языков программирования информации на этапе лексического анализа может быть недостаточно для однозначного определения типа и границ очередной лексемы.
Иллюстрацией такого случая может служить пример оператора присваивания из языка программирования Си++:
k = i+++++j;
Который имеет только одну верную интерпретацию (если операции разделить пробелами):
k = i++ + ++j;
Если невозможно определить границы лексем, то лексический анализ исходного текста должен выполняться поэтапно. Тогда лексический и синтаксический анализаторы должны функционировать параллельно, поочередно обращаясь друг к другу. Лексический анализатор, найдя очередную лексему, передает ее синтаксическому анализатору, тот пытается выполнить анализ считанной части исходной программы и может либо запросить у лексического анализатора следующую лексему, либо потребовать от него вернуться на несколько шагов назад и попробовать выделить лексемы с другими границами.
Очевидно, что параллельная работа лексического и синтаксического анализаторов более сложна в реализации, чем их последовательное выполнение. Кроме того, такая реализация требует больше вычислительных ресурсов и в общем случае большего времени на анализ исходной программы.
Чтобы избежать параллельной работы лексического и синтаксического анализаторов, разработчики компиляторов и языков программирования часто идут на разумные ограничения синтаксиса входного языка. Например, для языка Си++ принято соглашение, что при возникновении проблем с определением границ лексемы всегда выбирается лексема максимально возможной длины. Для рассмотренного выше оператора присваивания это приводит к тому, что при чтении четвертого знака + из двух вариантов лексем (+ – знак сложения, ++ – оператор инкремента) лексический анализатор выбирает самую длинную, т.е. ++, и в целом весь оператор будет разобран как k = i++ +++j;, что неверно. Любые неоднозначности при анализе данного оператора присваивания могут быть исключены только в случае правильной расстановки пробелов в исходной программе.
Вид представления информации после выполнения лексического анализа целиком зависит от конструкции компилятора. Но в общем виде ее можно представить как таблицу лексем, которая в каждой строчке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно такая таблица имеет два столбца: первый – строка лексемы, второй – указатель на информацию о лексеме, может быть включен и третий столбец – тип лексем. Не следует путать таблицу лексем и таблицу идентификаторов – это две принципиально разные таблицы! Таблица лексем содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, при этом, любая лексема может в ней встречаться любое число раз. Таблица идентификаторов содержит только следующие типы лексем: идентификаторы и константы. В нее не попадают ключевые слова входного языка, знаки операций и разделители. Каждая лексема в таблице идентификаторов может встречаться только один раз.
Вот пример фрагмента текста программы на языке Паскаль и соответствующей ему таблицы лексем:
...
begin
for i:=1 to N do
fg:= fg * 0.5
...
Таблица 2 – Таблица лексем программы.
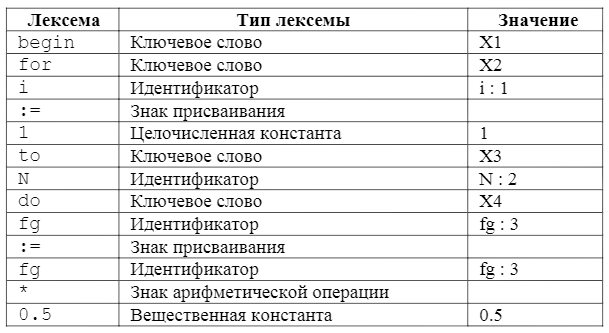
В этой таблице поле «значение» подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем. Значения, приведенные в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Связь между таблицей лексем и таблицей идентификаторов отражена в примере некоторым индексом, следующим после идентификатора за знаком «:». В реальном компиляторе эта связь определяется его реализацией.
Задание: спроектировать лексический анализатор языка программирования Java. Сам программный продукт должен быть выполнен на языке программирования C#. Должны проверяться следующие лексемы:
· Числовые константы.
· Типы данных:
1) Целочисленные.
2) Вещественные.
· Массивы и элементы массивов.
· Арифметические операторы.
· Операции сравнения.
· Описание данных.
· Операторы условного и безусловного перехода.
· Метки.
Составим классы лексем Java(таблица 3).
Таблица 3 – классы лексем
| Тип | Обозначение |
| Константы целочисленные | С |
| Константы с плавающей точкой | Z |
| Тип данных | T |
| Идентификаторы | I |
| Арифметические операторы | A |
| Операторы | S |
| Разделитель | R |
| Ключевые слова | K |
В языке программирования Java числовые константы представляются в виде:
Таблица 4 – числовые константы в языке программирования Java.
| Десятичные | Последовательность цифр (0 — 9), которая начинаются с цифры, отличной от нуля. Пример: 1, -29, 385. Исключение — число 0. | C1 |
Таблица 5 – числовые константы с плавающей точкой в языке Java
| Знак | Порядок | Мантисса | Сдвиг | |
| 32 bit Float | 1 бит [31] | 8 бит [30-23] | 23+1 бит [22-0] | -127 |
| 64 bit double | 1 бит [63] | 11 бит [62-52] | 52+1 бит [51-0] | -1023 |
Лексический анализатор должен определять все числовые константы. Он должен отличать константы от чисел в имени переменной.
Целочисленные типы данных в Java (таблица 4):
Таблица 5 – целочисленные типы данных в Java.
| Имя | Токен |
| Byte | |
| Short | |
| Int | |
| Long |
Типы данных с плавающей точкой в Java (таблица 5).
Таблица 6 – типы данных с плавающей точкой.
| Имя | Токен |
| Double | |
| Float |
Таблица 7 – ссылочный тип данных
| Имя | Токен |
| Scanner |
Имеют вид:
1)Имя Список переменных;
2)Имя переменная = числовая константа;
В языке программирования Java массивы представлены в виде:
Тип_данных переменная [размер массива] = [константа] ….
Тип_данных переменная [размер массива] [размер массива] = [константа][константа] [константа][константа] [константа][константа]….
Лексический анализатор должен определять типы переменных и типы массивов. Определять является ли переменная массивом и считывает каждый элемент массива.
Арифметические операторы в Java (таблица 6):
Таблица 8 – арифметические операции в Java.
| Cимвол | Токен | Неформальное описание |
| + | Сложение | |
| - | Вычитание | |
| * | Умножение | |
| / | Деление | |
| % | Деление с остатком |
В Java Операторы условного и безусловного перехода представлены в таблице
Таблица 9 - Операторы условного и безусловного перехода в Java.
Имеют вид:
break
for(int i = 0; i < 100; i++) {
if(i == 5) break; // выходим из цикла, если i равно 5
mInfoTextView.append("i: " + i + "\n");
}
mInfoTextView.append("Цикл завершён");
Continue
for (int i = 0; i < 10; i++) {
mInfoTextView.append(i + " ");
if (i % 2 == 0)
continue;
mInfoTextView.append("\n");
}
return
Оператор return используют для выполнения явного выхода из метода. Оператор можно использовать в любом месте метода для возврата управления тому объекту, который вызвал данный метод. Таким образом, return прекращает выполнение метода, в котором он находится.
Таблица 10 –Операторы
| Имя | Токен | Неформальное описание |
| > | Больше чем | |
| < | Меньше чем | |
| <= | Меньше или равно | |
| >= | Больше или равно | |
| == | Равно | |
| = | Присвоить | |
| println | Ввод | |
| out | Ввывод | |
| break | Безусловные | |
| Continue | ||
| return | ||
| Goto | ||
| if | Условные | |
| else |
Таблица 11 – Разделители
| Разделитель | Код |
| пробел | |
| , | |
| ; | |
| ( | |
| ) | |
| . | |
| { | |
| } | |
| “ | |
| ” | |
| конец строки |
Таблица 12 – Ключевые(служебные) слова
| Имя | Токен |
| public | |
| main | |
| class | |
| new | |
| System | |
| nextDouble | |
| String | |
| import | |
| java | |
| util |
При лексическом разборе входной цепочки пробелы не кодируются как разделители и в выходную цепочку не попадают. Это связано с тем, что в исходном тексте программы пробелы служат только для структурирования текста программы и не несут дополнительной смысловой нагрузки.
Рассмотрим работу сканера на примере исходной программы, представленной ниже:
import java.util.Scanner;
public class main {
public static void main(String[] args) {
int a = 10;
Scanner in = new Scanner(System.in);
double b = in.nextDouble();
String text = "Больше";
String text1 = "Меньше";
if (a > b) {
System.out.println(text);
}
if(a < b) {
System.out.println(text1);
}
if (a == b){
System.out.println("=");
} } }
Спроектируем лексический анализатор. Для этого построим блок-схемы будущего приложения (блок-схемы 1-3). В таблицах приведены токены, которые будет видеть выдавать лексический анализатор.
Каждая обработанная лексема преобразуется к виду:
<буква><код>
где: <буква> – это признак класса лексемы
<код> – номер лексемы в соответствующей таблице.
на выходе сканера будет сформирована следующая последовательность
кодов лексем:
Для данной исходной программы лексический анализатор сформирует следующую выходную последовательность лексем (таблица 13):
Таблица 13 - выходную последовательность лексем
| Входная последовательность текста исходной программы | Выходная последовательность лексем во внутреннем представлении |
| //программа сравнения чисел | |
| import java.util.Scanner; | K8 K9 R6 K10 R6 T7 R3 |
| public class main { | K1 K2 K3 R7 |
| int a = 10; | T3 I S0 W1 R3 |
| Scanner in = new Scanner(System.in); | T7 I S0 K4 T7 K5 R6 I R3 |
| double b = in.nextDouble(); | T5 I S0 I R6 K6 R4 R5 R3 |
| String text = "Больше"; | K7 I S0 R9 I R10 R3 |
| String text1 = "Меньше"; | K7 I S0 R9 I R10 R3 |
| if (a > b) { | S12 R4 I S1 I R5 R7 |
| System.out.println(text); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if(a < b) { | S12 R4 I S2 I R5 R7 |
| System.out.println(text1); | K5 R6 K8 R6 S6 R4 I R5 R3 |
| } | R8 |
| if (a == b){ | S12 R4 I S5 I R5 R7 |
| System.out.println("="); | K5 R6 S7 R6 S6 R4 R9 I R10 R5 R3 |
| } } } | R8 R8 R8 |
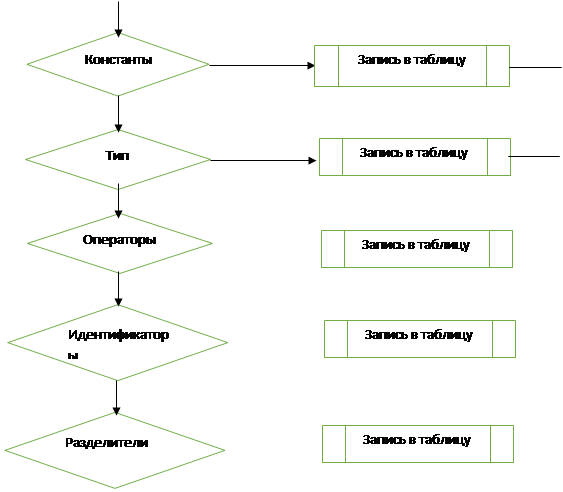
Разработаем блок-схемы для лексического анализатора (блок-схема 1,2,3). После составления всех таблиц с лексемами вы видим, что в нашем лексическом анализаторе буду отдельно проверяться типы данных, операции, Константы, операторы. На основе этих данных мы должны разобрать как же будут у нас заполняться таблицы. Блок-схемы выглядят следующим образом
Блок-схема 1 - Схема работы лексического анализатора
 | |||
 |

 | |||
 |



 Запись в отдельную таблицу
Запись в отдельную таблицу
 | |||
 |

 |
 | |||
 | |||
 Если на выходе нет ошибок
Если на выходе нет ошибок
 |
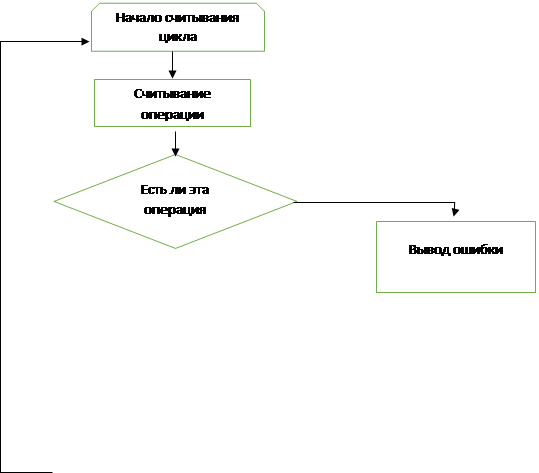
Блок-схема 2 - Сканирование документа операции.
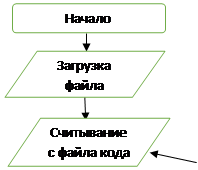 |
 Задаем цикл для считывания каждой операции
Задаем цикл для считывания каждой операции
 |

 нет
нет
 | |||
 | |||
На выходе мы получаем уведомление что нету
такой операции
 |
 нет
нет
 |


 |
Блок-схема 3 Сканирование документа операторы
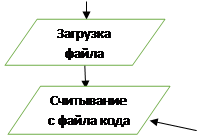 |

Задаем цикл для считывания каждой операторы
 |
 нет
нет
 | |||
| |||
На выходе мы получаем уведомление что нету
такого оператора
 |
нет
|
|