Программирование на языках высокого уровня
1. ОСНОВНЫЕ ПОНЯТИЯ
1.1. Алфавит и словарь языка
Программа формируется из предложений, состоящих из лексем и разделителей, которые в свою очередь формируются из конечного набора литер, образующих алфавит языка Pascal. Этот язык состоит из букв латинского алфавита (прописных – А, В, С, D... X, Y, Z, строчных – а, b, с... x, у, z), арабских цифр (0, 1, 2, 3,4, 5, 6, 7,8,9) и специальных символов.
Использование строчных букв эквивалентно построению соответствующих конструкций из прописных букв и применяется для стилистического оформления программы. Иными словами, регистр при написании программ роли не играет.
Разделителями являются:
· пробел,
· конец строки,
·; – точка с запятой (конец предложения)
· комментарий, представляющий собой текст, ограниченный слева и справа фигурными скобками.
Лексемы включают: зарезервированные слова, идентификаторы (стандартные и пользовательские), специальные символы (простые и составные), метки.
Зарезервированные слова представляют собой составную часть языка, имеют фиксированное начертание и определенный смысл (например, зарезервированное слово VAR открывает раздел описания переменных).
Стандартные идентификаторы служат для определения заранее зарезервированных идентификаторов предопределенных типов данных, констант, функций и процедур (например, стандартная функция ABS возвращает модуль своего аргумента).
Идентификаторы пользователя применяются для обозначения констант, переменных, процедур и функций. Пользователь должен выбирать имя идентификатора отличное от зарезервированных слов и стандартных идентификаторов.
Правила составления идентификаторов.
1. Идентификатор начинается с буквы, или знака подчеркивания.
2. Содержит только буквы, цифры или знак подчеркивания.
3. Между двумя идентификаторами должен стоять разделитель.
4. Максимальная длина 127 символов. Все символы значимы.
5. Идентификатор не может повторять зарезервированное слово.
6. Если идентификатор пользователя повторяет стандартный, то действие стандартного идентификатора – отменяется.
Примеры пользовательских идентификаторов: x, s, s23, asd_sd45.
Специальные символы:
Простые
«+ », «- », «* », «/ », «= », «> », «< », «_ », «. », «, », «: », «; », «{} », «[] », «() », «^ », «' », «$ ».
Составные
«:= », «<> », «.. », «<= », «>= ».
Метки используются для идентификации операторов в программе при переходе по оператору GOTO. Правила написания меток отличаются от правил составления идентификаторов, следующим – на первом месте может стоять цифра.
Примеры меток: В1ок_12, 67, М1, exit, 15GX.
1.2. Скалярные, стандартные типы данных
Данные скалярного типа имеют в качестве своего значения одну единственную величину. В этом разделе мы остановимся на четырех важнейших, стандартных типах данных - INTEGER, REAL, BOOLEAN и CHAR.
Константы и переменные
При решении любой задачи требуются данные, над которыми выполняются действия для получения результата. Любое данное является либо константой, либо переменной.
Константы - это данные, значения которых известны заранее и в процессе выполнения программы не изменяются.
Переменные - это данные, которые меняют свое значение по ходу выполнения программы.
Тип INTEGER (целый)
Этот тин представляет множество целых чисел диапазона от -32768 до 32767. В памяти ЭВМ под целое число отводится два байта (16 бит). Наибольшему значению целого числа 32767 соответствует стандартный идентификатор MAXINT, а наименьшему – выpaжeниe NOT (MAXINT) = - (MAXINT +1), или число -32768.
Операции, проводимые над целыми числами: «+» сложение, «-» вычитание, «*» умножение, DIV - целочисленное деление, MOD - остаток от целочисленного деления, AND - арифметическое 'И', OR - арифметическое 'ИЛИ', NOT – арифметическое отрицание, XOR - исключающая дизъюнкция. Примеры использования этих операций приведены в таблице1.
Таблица 1.
| Операция | Пример использования | Результат выполнения |
| + | 5 + 3 | |
| - | 5 - 3 | |
| * | 5 * 3 | |
| DIV | 14 div 4 | |
| MOD | 14 mod 4 | |
| AND | 11 and 5 | |
| OR | 11 or 4 | |
| NOT | not 8 | -9 |
| XOR | 11 xor 21 |
Любая из этих операций выполнима над двумя целыми числами, если абсолютная величина результата не превышает MAXINT (для умножения). В противном случае возникает прерывание программы, связанное с переполнением.
Например: требуется вычислить выражение 1000 * 4000 div 2000. Поскольку операции умножения и деления имеют один приоритет и выполняются слева направо в порядке записи арифметического выражения, то при умножении произойдет прерывание, связанное с переполнением. Выход из этой ситуации возможен при изменении порядка выполнения операций умножения и деления, для чего используются круглые скобки ==> 1000 * (4000 div 2000).
Предусмотрено представление целых чисел в шестнадцатеричной системе счисления. Форма записи таких чисел $Х, где X - целая константа, а символ $ - признак. Примеры: $57, $1FF. Напомним, что в шестнадцатеричной системе счисления цифры 10, 11, 12, 13, 14 и 15 заменяются латинскими буквами А, В, С, D, Е и F соответственно.
Кроме типа INTEGER в языке Pascal предусмотрены и другие целые
типы данных BYTE, SHORTINT, WORD и LONGINT (таблица 2). Все эти типы определены на множестве целых чисел, характеризуются одним набором арифметических операций и отличаются диапазоном значений и объемом занимаемой памяти.
Таблица 2
| Название типа | Длина, байты | Диапазон значений числа |
| BYTE | 0.. 255 | |
| SHORTINT | -128.. 127 | |
| WORD | 0.. 65535 | |
| INTEGER | -32768.. 32767 | |
| LONGINT | -2147483648.. 2147483647 |
Тип REAL (вещественный)
Число типа REAL занимает три слова (шесть байтов). При работе с вещественными числами нужно помнить, что на любом отрезке вещественной оси существует бесчисленное множество чисел. Поскольку для кодирования вещественного числа отведено всего шесть байтов памяти, то расчеты выполняются всегда с конечной точностью, которая зависит от формата числа.
Вещественное число записывается и хранится в памяти компьютера в виде  , где m – мантисса, В – основание представления числа с плавающей точкой, n – порядок (целое число). Имеют место ограничения – M 1 < m < + М 2; - E 1< n < + Е 2. В этих выражениях B, Е и М — константы, характеризующие представление числа. В таблице 3 приведены значения этих констант для вещественных типов данных, используемых в Pascal.
, где m – мантисса, В – основание представления числа с плавающей точкой, n – порядок (целое число). Имеют место ограничения – M 1 < m < + М 2; - E 1< n < + Е 2. В этих выражениях B, Е и М — константы, характеризующие представление числа. В таблице 3 приведены значения этих констант для вещественных типов данных, используемых в Pascal.
Таблица 3.
| Название типа | Длина, байты | Мантисса, количество значащих цифр | Диапазон десятичного порядка |
| SINGLE | 7.. 8 | -45.. 38 | |
| REAL | 11.. 12 | -39.. 38 | |
| DOUBLE | 15.. 16 | -324.. 308 | |
| EXTENDED | 19.. 20 | -4951.. 4932 |
Так, для типа REAL основание В равно 10. Размер мантиссы 11—12 десятичных чисел. Диапазон десятичного порядка равен [-39, +38]. Таким образом, на отрезке оси вещественных чисел в заданном диапазоне можно закодировать только конечное число значений, а поскольку на оси таких чисел бессчетное множество, то выбирается интервал, «дискрет», на который этот диапазон (отрезок) делится. Число таких интервалов конечно. Каждый дискрет ставится в соответствие значению вещественного числа. Конечное множество определенных таким образом представителей вещественных чисел называется континуумом. Результаты вычислений округляются до чисел этого множества, поэтому необходимо говорить о точности вычислений. Округление результата происходит до ближайшего вещественного числа большего данного по модулю. Следует также отметить, что эти интервалы не являются равными. В соответствии с полулогарифмическим способом своего представления интервалы «растягиваются» с увеличением порядка. Наибольшая точность расчетов достигается в центральной части диапазона изменения вещественного числа X (например, в районе 1.0Е+00 погрешность вычислений 0,00000000001), и наименьшая — на его краях (например, в окрестностях числа 1.0Е+38 погрешность вычисления равна 1000000000000000000000000000).
Существует две формы отображения вещественных чисел (таблица 4): полулогарифмическая (с плавающей точкой) и естественная (с фиксированной точкой).
Таблица 4. Правильное представление вещественных чисел
| С плавающей точкой | С фиксированной точкой |
| 0.000000Е + 00 (нормальная форма) | 0.0 |
| 1.340000Е + 02 | 134.0 |
| -7611.Е - 02 | -76.11 |
| -98.3569Е - 05 | -0.000983569 |
Над вещественными числами определены операции сложения (+), вычитания (-), умножения (*) и деления (/). Операция возведения в степень не предусмотрена.
Использование типа REAL у начинающего программиста часто вызывает ряд
ошибок, приводящих к искажению результата по следующим причинам:
ошибки ввода — недостаточная точность исходных данных при сборе, подготовке и их вводе в ЭВМ;
ошибки представления обуславливаются ограниченной точностью внутреннего представления данных в конкретной ЭВМ, используемой для расчетов;
ошибки вычислений возникают за счет несовершенства математических методов, выбранных для решения задачи. Необходимо оценивать погрешность и держать ее в заданных пределах.
Тип BOOLEAN (булевский, логический)
Логический тип в языке Паскаль задается как перечисляемый тип, содержащий всего два значения, которые имеют идентификаторы FALSE (ложь) и TRUE (истина). Элементам этого типа поставлены в соответствие номера: 0 — значению FALSE и 1 — TRUE. Поэтому FALSE < TRUE.
В памяти ЭВМ переменные этого типа занимают один байт. Над данными этого
типа определены операции: дизъюнкция (˅) OR, конъюнкция (˄) AND, исключающее ИЛИ (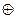 ), отрицание (
), отрицание ( ) NOT, а также отношения <, >, <=, >=, <>, =. Результаты выполнения логических операций над булевыми переменными P и Q приведены в таблице 5.
) NOT, а также отношения <, >, <=, >=, <>, =. Результаты выполнения логических операций над булевыми переменными P и Q приведены в таблице 5.
Таблица 5
| P | Q | P ˄ Q | P ˅ Q | P Q
| P
| Q
|
| False | False | False | False | False | True | True |
| True | False | False | True | True | False | True |
| False | True | False | True | True | True | False |
| True | True | True | True | False | False | False |
Следует отметить, что операции сравнения данных любых типов имеют результат типа BOOLEAN. Например, если даны переменные с именами Р, Q типа BOOLEAN и X, Y, Z типа REAL, причем X = 5.8, Y = 8, a Z = 10.3, то справедливы утверждения:
Q:= (X < Y) ˄ (Y <= Z) =>TRUE;
P:= X = Y =>FALSE.
Наиболее часто булевский тип данных используется для управления порядком выполнения операторов в программе.
В языке имеется функция ODD (X), где X - целое число. Если X четно, то ODD (X) принимает значение FALSE, если X нечетно, то ODD (X) – TRUE.
Основные соотношения алгебры логики:
1. Р ˅ Q = Q ˅ Р.
Р ˄ Q = Q ˄ Р.
2. (Р ˅ Q) ˅ R = Р ˅ (Q ˅ R).
(Р ˄ Q) ˄ R = Р ˄ (Q ˄ R).
3. (Р ˄ Q) ˅ R = (Р ˅ R) ˄ (Q ˅ R).
(Р ˅ Q) ˄ R = (Р ˄ R) ˅ (Q ˄ R).
4. (Р ˅ Q) = P ˄ Q.
(Р ˄ Q) = Р ˅ Q.
При решении практических задач могут возникнуть самые разнообразные условия, которые следует записать в виде логических выражений, использующих логические операции и отношения. В этом случае бывает полезно помнить о следующих булевых соотношениях и эквивалентных преобразованиях.
Эквивалентные преобразования
X ≠ Y (X = Y)
X £ Y (X > Y) ˅ (X = Y)
X ³ Y (X < Y)
X > Y (X < Y) ˄ (X = Y)
Тип CHAR (литерный, символьный)
Этот тип задает конечное упорядоченное множество символов (литер), допускаемое в конкретной реализации языка. В ЭВМ для внутреннего представления символов, хранения символьной информации на внешних носителях и кодирования знакогенераторов дисплеев и печатающих устройств используется восьмиразрядный код ASCII (American Standard Code for Information Interchange -стандартный американский код, используемый для обмена информацией). Емкость кода 256 единиц.
Общая часть кодовой таблицы для всех персональных компьютеров содержит
символы, имеющие коды от 32 до 127, сведенные в таблицу 6.
Таблица 6
| 32 – пр. | 48 – 0 | 64 – @ | 80 – Р | 96 – ‘ | 112 – p |
| 33 –! | 49 – l | 65 – А | 81 – Q | 97 – а | 113 – q |
| 34 – " | 50 – 2 | 66 – В | 82 – R | 98 – b | 114 – r |
| 35 – # | 51 – 3 | 67 – С | 83 – S | 99 – с | 115 – s |
| 36 – $ | 52 – 4 | 68 – D | 84 – Т | 100 – d | 116 – t |
| 37 – % | 53 – 5 | 69 – Е | 85 – U | 101 – е | 117 – u |
| 38 – & | 54 – 6 | 70 – F | 86 – V | 102 – f | 118 – v |
| 39 – ’ | 55 – 7 | 71 – G | 87 – W | 103 – g | 119 – w |
| 40 – ( | 56 – 8 | 72 – Н | 88 – X | 104 – h | 120 – x |
| 41 –) | 57 – 9 | 73 – I | 89 – Y | 105 – i | 121 – у |
| 42 – * | 58 –: | 74 – J | 90 – Z | 106 – j | 122 – z |
| 43 – + | 59 –; | 75 – К | 91 – [ | 107 – k | 123 – { |
| 44 –, | 60 – < | 76 – L | 92 – \ | 108 – l | 124 – | |
| 45 – - | 61 – = | 77 – М | 93 – ] | 109 – m | 125 – } |
| 46 –. | 62 – > | 78 – N | 94 – ^ | 110 – n | 126 – ~ |
| 47 – / | 63 –? | 79 – О | 95 – _ | 111 – o | 127 – |
Первые позиции 0 – 31 заняты под коды управления устройствами (монитор, принтер и др.) и могут иметь разное воздействие на разные устройства. Например, код 7 вызывает звуковой сигнал при выводе информации на дисплей - WRITELN ('Проверьте принтер!', CHR(7)); коды 13 и 10 для дисплея или принтера осуществляют перевод курсора в начало текущей строки и переход на следующую строку. Эти коды можно использовать для вывода информационного сообщения, составляющего несколько строк, с помощью одного оператора вывода:
WRITELN('Bнимание!'' + CHR(13) + CHR(10) + 'Следите за экраном.').
Переменная часть кодовой таблицы содержит национальный алфавит, символы псевдографики и специальные нестандартные символы. Коды 128 — 255, приведенные в таблице 7, отражают модифицированную кодировку ГОСТа для подключения кириллицы.
Таблица 7
| 128 – А | 144 – Р | 160 – а | 176 – ░ | 192 – └ | 208 – ╨ | 224 – р | 240 – Ё |
| 129 – Б | 145 – С | 161 – б | 177 – ▒ | 193 – ┴ | 209 – ╤ | 225 – с | 241 – ё |
| 130 – В | 146 – Т | 162 – в | 178 – ▓ | 194 – ┬ | 210 – ╥ | 226 – т | 242 – Є |
| 131 – Г | 147 – У | 163 – г | 179 – │ | 195 – ├ | 211 – ╙ | 227 – у | 243 – є |
| 132 – Д | 148 – Ф | 164 – д | 180 – ┤ | 196 – ─ | 212 – ╘ | 228 – ф | 244 – Ї |
| 133 – Е | 149 – X | 165 – е | 181 – ╡ | 197 – ┼ | 213 – ╒ | 229 – х | 245 – ї |
| 134 – Ж | 150 – Ц | 166 – ж | 182 – ╢ | 198 – ╞ | 214 – ╓ | 230 – ц | 246 – Ў |
| 135 – 3 | 151 – Ч | 167 – з | 183 – ╖ | 199 – ╟ | 215 – ╫ | 231 – ч | 247 – ў |
| 136 – И | 152 – Ш | 168 – и | 184 – ╕ | 200 – ╚ | 216 – ╪ | 232 – ш | 248 – º |
| 137– Й | 153 – Щ | 169 – й | 185 – ╣ | 201 – ╔ | 217 – ┘ | 233 – щ | 249 – • |
| 138 – К | 154 – Ъ | 170 – к | 186 – ║ | 202 – ╩ | 218 – ┌ | 234 – ъ | 250 – · |
| 139 – Л | 155 – Ы | 171 – л | 187 – ╗ | 203 – ╦ | 219 – █ | 235 – ы | 251 – √ |
| 140 – М | 156 – Ь | 172 – м | 188 – ╝ | 204 – ╠ | 220 – ▄ | 236 – ь | 252 – № |
| 141 – Н | 157 – Э | 173 – н | 189 – ╜ | 205 – ═ | 221 – ▌ | 237 – э | 253 – |
| 142 – О | 158 – Ю | 174 – о | 190 – ╛ | 206 – ╬ | 222 – ▐ | 238 – ю | 254 – ■ |
| 143 – П | 159 – Я | 175 – п | 191 – ┐ | 207 – ╧ | 223 – ▀ | 239 – я | 255 – зб. |
Примечание: в таблицах 6 и 7 сокращения (пр.) и (зб.) означают пробел и забой соответственно.
Значения констант и переменных типа CHAR есть один символ из допустимого набора, например: 'Z', 'j', '2', '*', 'Ц', 'д', 'г'. Второй способ записи символа в программе состоит в использовании префикса # перед номером литеры. Примеры символов: #90, #106, #50, #42, #150, #164.
Описываются переменные этого типа как – VAR CHI, CH2:CHAR;
Использование переменных типа CHAR в арифметических выражениях запрещено. К данным этого типа могут применяться только операции сравнения, при этом результат зависит от порядковых номеров литер в кодовой таблице символов.
Например: 'В' > 'А' => FALSE, '1' <= '9' => TRUE.
Множество цифр и букв не только упорядочено в соответствии с кодом литер от 32 до 255, но и связно, код последующей литеры больше кода предшествующей на 1.
Таким образом, '0' < '1' < '2' <... < '9'; 'А' < 'В' < 'С < 'D' <... < 'Z'; 'а' < 'б' < 'в' < 'г' <... < 'я'.
Для работы с литерами часто используются функции CHR, ORD, PRED, SUCC,
описание которых приведено в таблице 10.
Пример 1. Вывести на экран монитора литеры, коды которых начинаются с 32
и заканчиваются — 255.
PROGRAM PR1;
VAR I: INTEGER;
BEGIN
FOR I:=32 TO 255 DO WRITELN('код =', I:-3,'===>', CHR(I))
END.
Встроенные функции
Наиболее часто встречающиеся операции над скалярными типами данных реализованы в языке Паскаль с помощью встроенных (иногда говорят — стандартных) функций и процедур. Наиболее известные функции над переменными целого, вещественного, логического и литерного типов приведены в таблицах 8 – 11.
Таблица 8. Встроенные арифметические функции
| Функция | Содержание |
| ABS(X) | Модуль (абсолютная величина) X, |Х| |
| ARCTAN(X) | Главное значение арктангенса X, ArctgX |
| COS(X) | Косинус от X, заданного в радианах, Cos(X) |
| ЕХР(Х) | Показательная функция от X, ех |
| FRAC(X) | Дробная часть от X, {X} |
| INT(X) | Целая часть числа X в вещественной форме, ]Х[ |
| LN(X) | Натуральный логарифм от X, Ln(X) |
| SIN(X) | Синус от X, заданного в радианах, Sin(X) |
| SQR(X) | Квадрат (вторая степень) числа X, т.е. X2 |
| SQRT(X) | Корень квадратный из X, 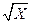
|
| RANDOM(N) | Равномерно распределенное псевдослучайное целое число от 0 до N |
| RANDOM | Равномерно распределенное псевдослучайное вещественное число от 0 до 1 |
| ROUND(X) | Возвращает значение X, округленное до ближайшего целого числа |
| TRUNC(X) | Возвращает ближайшее целое число, меньшее или равное X, если X > 0, и большее или равное X, если X < 0 |
В таблице 9 приведены примеры вычислений по функциям INT, ROUND, TRUNC пояснения особенностей их использования.
Таблица 9
| Функция | X | INT(X) | ROUND(X) | TRUNC(X) |
| Тип | REAL | REAL | INTEGER | INTEGER |
| Номер примера: | ||||
| 123.44 | 123.0 | |||
| 34.50 | 34.0 | |||
| 1.70 | 1.0 | |||
| -25.14 | -25.0 | -25 | -25 | |
| -10.70 | -10.0 | -11 | -10 | |
| -0.41 | 0.0 | |||
| -0.50 | 0.0 | -1 |
Таблица 10. Встроенные логические (булевские) функции
| Функция | Содержание |
| ODD(N) | N — целочисленная переменная; результат TRUE, если N — нечетное число, и FALSE, если N — четное число |
| EOF(F) | Возвращает значение TRUE, если достигнут конец файла F, в противном случае FALSE |
| EOLN(F) | Принимает значение TRUE, если при чтении текстового файла F достигнут конец текущей строки, FALSE — в противном случае |
Таблица 11. Встроенные функции над перечислимыми типами данных
| SUCC(s) | SUCC('O') | 'П' | Возвращает значение следующего за S данного перечисляемого типа | совпадает с типом аргумента S |
| SUCC(-90) | -89 | |||
| SUCC('a') | 'b' | |||
| PRED(s) | PRED('П') | 'О' | Возвращает значение предшествующего S в порядке возрастания в списке | совпадает с типом аргумента S |
| PRED(-90) | -91 | |||
| PRED('b') | 'a' | |||
| ORD(s) | ORD('Щ') | Возвращает порядковый номер идентификатора S в списке | INTEGER | |
| ORD('4') | ||||
| ORD(FALSE) | ||||
| CHR(s) | CHR(87) | 'W' | Возвращает литеру с кодом S, если она существует | CHAR |
| CHR(20l) | 'r' | |||
| CHR(53) | '5' |
1.4. Структура программы
Программист вводит текст программы, произвольно располагая строки на экране. Отступ слева выбирает сам программист, чтобы программа была более читабельной. В одной строке допускается писать несколько операторов. Длинные операторы можно переносить на следующую строку. Перенос допускается в любом месте, где можно сделать пробел. Максимальная длина строки не должна превышать 127 символов. Из соображений наглядности, удобства просмотра и отладки программы рекомендуется длину строки ограничивать 80 символами. Программы имеют жесткую структуру, описанную в таблице 12.
Таблица 12. Структура программы
| Фрагмент программы | Содержание | Примечание |
| Заголовок | Program <имя программы> | Необязательный |
| Раздел 0 | USES, описание модулей, библиотек | Разделы описаний программного блока |
| Раздел I | LABEL, описание меток | |
| Раздел 2 | CONST, описание констант | |
| Раздел 3 | TYPE, описание типов данных | |
| Раздел 4 | VAR, описание переменных | |
| Раздел 5 | PROCEDURE, FUNCTION - описание процедур и функций, используемых в программе | |
| Раздел 6 | BEGIN... END. - тело программы | Раздел исполняемых операторов |
Синтаксические правила построения предложений языка можно описывать следующими способами:
• схемой (форматом предложения или раздела). В учебном процессе выбран именно этот способ, поскольку он наиболее понятен начинающему программисту;
• синтаксической диаграммой. Этот способ детально формализует синтаксис предложения и используется разработчиками трансляторов с языка Паскаль;
• порождающими правилами РАСШИРЕННЫХ БЭКУСА-НАУРА ФОРМ (РБНФ). Это весьма компактный и в то же самое время наглядный способ записи языковых конструкций. Этот способ используется в статьях и научных разработках. В данном курсе используются только пять элементов РБНФ (таблица 13).
Таблица 13
| Соглашение | Толкование |
| Угловые скобки < > | Угловые скобки заключают в себе элемент синтаксиса, который Вы должны задать. Текст внутри угловых скобок характеризует элемент, однако, не описывает синтаксис этого элемента |
| Квадратные скобки [ ] | Квадратные скобки в синтаксических конструкциях заключают в себе один или несколько необязательных элементов |
| Вертикальная черта | | Разделяет два альтернативных элемента синтаксической конструкции, один из которых нужно выбрать |
| Фигурные скобки { } | Фигурные скобки заключают в себе несколько элементов, разделенных '|'. Из них нужно выбрать один |
| Многоточие … | Многоточие показывает, что можно повторить некоторый элемент один и более раз |
Раздел описания модулей USES
Раздел имеет структуру:
USES
Модуль 1, Модуль 2,... Модуль N,
где за ключевым словом USES указывается список, в котором перечисляются все имена библиотек (модулей) стандартных и пользовательских, к процедурам и функциям которых есть обращение в программе. Если таких обращений нет, то раздел USES не нужен.
Пример:
USES CRT, GRAPH, HELP, MYLIB;
В этом примере две стандартные библиотеки — CRT, GRAPH и две пользовательские библиотеки — HELP, MYLIB.
Раздел описания меток LABEL
Раздел имеет структуру:
LABEL Метка 1, Метка 2,Метка N,
где за ключевым словом LABEL указывается список, в котором перечисляются все имена меток, встречающихся в программе.
Пример:
LABEL Ml, 12_BL, 9999;
Метки позволяют менять естественный ход выполнения программы. Ссылка на метку осуществляется оператором GOTO <метка>. Если в программе меток нет, то раздел LABEL отсутствует. В теле программы (в разделе операторов) метка ставится перед требуемым оператором и отделяется от него двоеточием.
Пример:
М27: X:= А * В - С/2;
Областью действия метки является блок, где она описана. Ниже приведена схема использования меток в тексте программы.
LABEL метка 1, метка 2;
BEGIN
метка 1: <Оператор 1>;
…
метка 2: <Оператор 2>;
…
END.
Раздел описания констант CONST
Раздел существует, если в алгоритме используется по крайней мере одна константа, то есть величина, не изменяющая своего значения в процессе выполнения программы. Попытка изменить значение константы в теле программы будет обнаружена на этапе трансляции.
В стандарте на Паскаль константы определяются следующим способом:
CONST
<Идентификатор 1> = <3начение 1>;
<Идентификатор 2> = <3начение 2>;
<Идентификатор N> = < Значение N>;
Примеры констант:
CONST
А = 15.7;
BXZ = 'Серия N123/5';
MIN_IND = $15D;
С_10 = -0.57Е-6;
L125 = 695;
FLAG = TRUE;
Константа может иметь только предопределенный (стандартный) тип данных. Тип присваивается константе по внешнему виду значения и в соответствии с этим типом отводится память для хранения значения константы.
В качестве расширения стандартного Паскаля разрешено использовать выражения, составленные из ранее определенных констант и некоторых стандартных функций (Abs, Chr, Hi, Length, Lo, Odd, Ord, Pred, Prt, Round, SizeOf, Succ, Swap, Trunc). Примеры использования константных выражений:
CONST
Min = 0;
Max = 250;
Centr = (Max-Min) div 2;
Beta = Chr(225);
NumChars = Ord('2') - Ord('A')+l;
Message = 'не хватает памяти';
ErrStr = 'Ошибка:' + Message + '.';
Ln10 - 2.302585092994045884;
Ln10R = 1/Ln10;
Константные выражения вычисляются компилятором без выполнения программы на этапе ее создания.
Раздел описания типов TYPE
Стандартные типы данных (REAL, INTEGER, BOOLEAN, CHAR) не требуют описаний в этом разделе. Описания требуют только типы, образованные пользователем.
Концепция типов — одно из основных понятий в языке. С каждым данным связывается один и только один определенный тип.
Тип — это множество значений + множество операций, которые можно выполнять над этими значениями, то есть правила манипулирования данными. Использование типов позволяет выявлять многочисленные ошибки, связанные с некорректным использованием значений или операций еще на этапе трансляции без выполнения программ.
О Паскале говорят, что он строго типизирован, то есть программист должен описать все объекты, указывая их типы, и использовать в соответствии с объявленными типами. Программы становятся более надежными и качественными. При компиляции информация используется для уточнения вида операции. Так знаком + для данных типа REAL и INTEGER обозначается операция сложения, а для множеств (тип SET) — объединение. Структура раздела описания типов имеет вид:
TYPE
<имя типа 1> = <значение типа 1>;
<имя типа 2> = <значение типа 2>;
…
<имя типа L> = <значение типа L>;
Имя типа представляет собой идентификатор, который может употребляться в других типах, описанных вслед за данным типом. Раздел TYPE не является обязательным, так как тип можно описать и в разделе переменных VAR. Примеры описания пользовательских типов:
TYPE
DAY = 1..31; Year = 1900.. 2000; {Интервальный тип}
LatBukv = ('А', 'С, 'D', 'G, 'Н'); {Перечисляемый тип}
Matr = array[-1..12, 'А'.. 'F'] of real; {Регулярный тип}
Раздел описания переменных VAR
Это обязательный раздел. Любая встречающаяся в программе переменная должна быть описана. В языке нет переменных, объявляемых по умолчанию. Основная цель этого раздела определить количество переменных в программе, какие у них имена (идентификаторы) и данные каких типов хранятся в этих переменных. Таким образом, переменная это черный ящик, а тип показывает, что мы в него можем положить.
Структура раздела имеет вид:
VAR
<список 1 идентификаторов переменных>:<тип 1>;
<список 2 идентификаторов переменных>:<тип 2>;
…
<список N идентификаторов переменных>:<тип N>;
Тип переменных представляет собой имя (идентификатор), описанный в разделе TYPE при явном описании типа, или собственно описание типа в случае его неявного задания. Примеры описания переменных:
TYPE
DAY= 1..31; Matr = ARRAY[1..5,1..8] OF INTEGER;
VAR
A, B: DAY; X, Y: Matr; {явное описание типов }
YEAR: 1900.. 2000; LES: (LPT, PRN); {неявное описание типов }
А, В, CD, FER51: REAL; {описание переменных стан-}
EQUAL: BOOLEAN; SH: CHAR; {дартных типов производится }
I, J, К: INTEGER; {только в разделе VAR}
Раздел описания процедур и функций
Стандартные процедуры и функции, имена которых включены в список зарезервированных слов, в этом разделе не описываются. Описанию подлежат только процедуры и функции, определяемые пользователем.
PROCEDURE <имя процедуры> (<параметры>); {заголовок процедуры}
<разделы описаний> {тело процедуры }
BEGIN
<раздел операторов >
END;
FUNCTION <имя функции>(<параметры>): <тип результата>; { заголовок }
<разделы описаний > {тело функции}
BEGIN
<раздел операторов >
END;
Структура процедур и функций та же самая, что и у основной программы. Отличие описаний состоит в том, что идентификаторы констант, переменных, процедур и функций, описанных в соответствующих разделах описаний пользовательских процедур и функций, распространяются только на блоки, где они описаны и на блоки внутренние по отношению к ним. На внешние блоки, в том числе на тело основной программы, они не распространяются.
Раздел операторов
Это основной раздел, именно в нем в соответствии с предварительным описанием переменных, констант, функций и процедур выполняются действия, позволяющие получать результаты, ради которых программа и писалась.
Синтаксис раздела операторов основной программы:
BEGIN
<Оператор 1;> { Операторы выполняются}
<Оператор 2;> { строго последовательно}
… {друг за другом.}
<Оператор N>
END.
Комментарий
Это пояснительный текст, который можно записать в любом месте программы, где разрешен пробел. Текст комментария ограничен: слева - '{', справа - '}', и может содержать любые символы. Комментарий игнорируется транслятором, и на программу влияния не оказывает.
Пример использования комментария:
PROGRAM PR;
<Разделы описаний >
BEGIN
<Оператор 1; >
<Оператор 2; >
{< Оператор 3; >
…
<Оператор N > }
END.
Средства комментария часто используются для отладки. Так в приведенном выше примере, операторы — 3,... N, заключенные в фигурные скобки, временно не выполняются.
Правила пунктуации
Основным средством пунктуации является символ точка с запятой – '; '.
1. Точка с запятой не ставится после слов LABEL, TYPE, CONST, VAR, а ставится
после каждого описания этих разделов.
2. Точка с запятой не ставится после BEGIN и перед END, так как эти слова – операторные скобки.
3. Точка с запятой разделяет операторы, и ее отсутствие вызовет:
А:= 333 {ошибка — нет ';'}
В:= А/10;;;;; {четыре пустых оператора}
4. Возможна ситуация:
END; следует писать END
END; ------------------ > END
END; END;
5. Допускается запись метки на пустом операторе — <Метка> :;
6. Точка с запятой не ставится после операторов WHILE, REPEAT, DO и перед UNTIL.
7. В условных операторах ';' не ставится после THEN и перед ELSE.
2. ПРОГРАММИРОВАНИЕ ВЫЧИСЛИТЕЛЬНЫХ ПРОЦЕССОВ
Решение задачи на ЭВМ — это сложный процесс, в ходе которого пользователю приходится выполнять целый ряд действий, прежде чем он получит интересующий его результат.
Идеальная модель процесса решения задач на компьютере показана в таблице 14.
Детальное рассмотрение этапов решения задачи на ЭВМ выходит за рамки данного курса. Напомним лишь некоторые существенные определения и понятия, которые будем использовать далее.
Алгоритмизация — это процесс проектирования алгоритма, то есть выделение совокупности действий, используемых в математическом методе, и сведения их к совокупности действий, которые будет выполнять ЭВМ.
Таблица 14
| Этапы решения задачи | Исходные данные, результаты | |
| Начало решения | Формулировка цели. Концептуальная, содержательная постановка задачи | |
| Постановка задачи Построение модели | ||
| Формальная математическая постановка задачи для ЭВМ | ||
| Алгоритмизация | ||
| Алгоритм | ||
| Запись алгоритма на языке программирования | ||
| Исходный текст программы на алгоритмическом языке. Программа в кодах ЭВМ | ||
| Выполнение программы | ||
| Результаты выполнения программы — числа, диаграммы, графики | ||
| Анализ и использование результатов работы программы | ||
| Выводы по результатам решения исходной задачи | ||
| Конец решения |
Алгоритм — совокупность точно описанных действий, приводящих от исходных данных к желаемому результату и удовлетворяющих следующим свойствам:
• определенности — алгоритм должен однозначно, точно и понятно задавать выполняемые действия (для одних и тех же исходных данных должен получаться один и тот же результат);
• дискретности — алгоритм должен представлять действие в виде последовательности составных частей;
• результативности — алгоритм долже