Оптическое распознавание текста
Проблема распознавания текста обычно решается в три этапа:
1) Выделение текста из изображения — включает в себя определение угла наклона страницы, выделение абзацев, удаление декоративной графики, определение таблиц и так далее
2) Распознавание символов текста — собственно OCR, включает в себя выделение характерных черт и классификацию образов
3) Распознавание слов текста — составление слов из распознанных символов
На каждом этапе для решения проблемы требуются разные средства, которые в совокупности образуют систему распознавания текста. В зависимости от специфики задачи (печатный или рукописный текст, язык текста и т.д.) разные средства применяются на разных этапах.
Понимание изображения документа
Большинство техник анализа изображения можно разделить на несколько групп, основываясь на используемых в них основных подходах:
1)Анализ проекционных профилей
2)Преобразование Хафа
3)Кластеризация связанных компонентов
4)Корелляция строк
5)Другие
Существуют также техники, основанные на градиентном анализе, анализе спектра Фурье, использовании морфологических преобразований и на обнаружении пустых строк.
Приведённые подходы применяются для определения угла наклона текста и декомпозиции страницы (деления страницы на регионы).
Анализ проекционных профилей
Этот подход отталкивается от предположения о том, что текст выстроен вдоль параллельных прямых линий. Принципиальная схема предполагает расчёт проекционного профиля по каждому углу наклона, определение функции премиума и выбор такого угла, который приводит её в оптимальное состояние. Подход требует относительно большое количество вычислительной мощности, поэтому было предложено несколько упрощённых вариантов, которые либо уменьшают время расчёта профилей, или оптимизируют стратегию поиска оптимума.
Преобразование Хафа
Эти техники основаны на наблюдении того, что текст отличается выравниванием символов, и что строки обычно параллельны друг другу. Для каждого чёрного пикселя  изображения находится соответствующая кривая в параметрическом пространстве
изображения находится соответствующая кривая в параметрическом пространстве  , пространстве Хафа, с помощью преобразования
, пространстве Хафа, с помощью преобразования 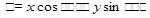 . Угловое разрешение метода зависит от разрешения оси. Сложность — линейна относительно числа преобразовывающихся точек и требуемого углового разрешения.
. Угловое разрешение метода зависит от разрешения оси. Сложность — линейна относительно числа преобразовывающихся точек и требуемого углового разрешения.
Срихари (Srihari) и Говиндараю (Govindaraju) применяют эту технику к бинарному изображению участка документа, который гарантированно содержит лишь текст, и только под одним углом наклона. Каждый чёрный пиксель отображается в пространство Хафа, и наклон определяется как угол в параметрическом пространстве, дающий максимальную сумму квадратов градиента по.
Для ускорения расчётов был предложен ряд вариантов, в которых происходит меньшее число отображений. Это достигается либо ограничением области анализа, либо ограничением пикселей неким подмножеством представителей.
Кластеризация ближайших соседей
Методы этого класса нацелены на использование общего предположения о том, что символы в строке выровнены и расположены близко друг к другу. Они характеризуется обработкой снизу вверх, которая начинается с множества объектов, связанных компонентов или представляющих их точек, и используют их взаимные расстояния и пространственные отношения для оценки угла наклона.
Корреляция строк
Делая предположение о том, что повёрнутые текстовые регионы представляют собой гомогенную горизонтальную структуру, эти подходы нацелены на оценку наклона путём измерения вертикального отклонения в изображении.
Акияма (Akiyama) и Хагита (Hagita) описывают быстрый метод определения наклона: документ делится на несколько вертикальных полос одинаковой ширины. Вычисляются горизонтальные проекционные профили полос, а также сдвиги, дающие лучшую корреляцию одной проекции с последующей. Наклон определяется как обратный тангенс отношения среднего сдвига и ширины полосы.
Другие методы
Также существуют методы, основанные на градиентном направленном анализе, преобразовании Фурье, на открытых и закрытых морфологических преобразованиях, техники основанные на размытии, техники классификации блоков и другие.