Любой сходящийся интеграл от неотрицательной функции порождает непрерывное распределение. Именно, если  j(x) dx = I, то роль плотности играет
j(x) dx = I, то роль плотности играет
p (x)= j(x), если x Î A,
0, если x Ï A.
Любая конечная сумма или сходящийся ряд с неотрицательными слагаемыми порождает дискретное распределение. Именно: если  qk = S, то роль дискретных вероятностей играют pk =
qk = S, то роль дискретных вероятностей играют pk =  qk, а в качестве xk можно взять любые числа; наиболее простой выбор: xk = k.
qk, а в качестве xk можно взять любые числа; наиболее простой выбор: xk = k.
Рассмотрим конкретные примеры.
1°. Равномерное распределение. Его порождает интеграл  dx = b - a.
dx = b - a.
p (x)= 
, если x Î[ a, b ],
0, если x Ï[ a, b ].
Этот закон распределения будем обозначать R (a, b); числа a и b называются параметрами распределения. Тот факт, что случайная величина X равномерно распределена на отрезке [ a, b ], будем обозначать следующим образом: X ~ R (a, b).
В частности, плотность случайной величины X ~ R (0, 1) имеет наиболее простой вид:
p (x)=1, если x Î[0, 1],
0, если x Ï[0, 1].
Функция распределения такой случайной величины равна:
F (x)=0, если x <0,
x, если 0£ x £1,
1, если x >0.
Если мы наугад выбираем точку на отрезке [0, 1], то её абсцисса x является конкретным значением случайной величины X ~ R (0, 1). Слово ''наугад" имеет в теории вероятностей терминологическое значение и говорится с целью подчеркнуть, что соответствующая непрерывная случайная величина распределена равномерно, или дискретная случайная величина имеет конечное число N возможных равновероятных значений.
2°. Экспоненциальное распределение.
Его порождает интеграл  e -m x dx =
e -m x dx =  , m>0.
, m>0.
Плотность вероятности, очевидно, равна
p (x)=m e -m x , если x ³0,
0, если x <0,
а
F (x)=
функция распределения:
1-m e -m x , если x ³0,
0, если x <0.
То обстоятельство, что случайная величина распределена по экспоненциальному закону, будем записывать так: X ~ Exp (m), m называется параметром распределения (m>0).
5°. Нормальное распределение. Его порождает интеграл Пуассона:
I = 
 dx =
dx =  .
.
Распределение с плотностью
p (x)=  , x Î(-¥; +¥)
, x Î(-¥; +¥)
называется стандартным нормальным законом и обозначается N (0, 1).
Ему соответствует функция распределения:
F 0(x)=  dx.
dx.
Обычно принято табулировать интеграл
F(x)= 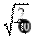
 dx,
dx,
называемый интегралом ошибок или интегралом Лапласа. Функция распределения стандартного нормального закона просто выражается через этот интеграл:
F 0(x)=  +
+  F(x).
F(x).
Если в интеграл Пуассона ввести параметры масштаба и сдвига с помощью замены переменной, заменив x на 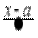 , то он примет вид:
, то он примет вид:
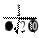
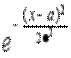 dx =1.
dx =1.
Случайную величину с плотностью вероятности
p (x)= , x Î(-¥; +¥),
называют нормально распределённой случайной величиной или просто нормальной. Соответствующий ей закон распределения обозначают N (a, s), a и s – параметры распределения (s>0, a – любое вещественное число).
Биномиальная случайная величина появляется, например, в схеме Бернулли, называемой также схемой последовательных независимых испытаний. Состоит она в следующем: осуществляется некоторый комплекс условий, при котором мы имеем одно и только одно из двух событий: либо "успех", либо "неудачу", причём вероятность "успеха" равна p, вероятность "неудачи" равна q =
=1- p; эта попытка независимым образом повторяется n раз. Считая опытом все n попыток, можем считать элементарным событием опыта цепочку длины n, полученных в результате опыта "успехов" (У) и "неудач" (Н): УУУННУ
Н¼У.
Определим случайную величину X, задав её как число успехов в одном опыте. Событию { X = k } благоприятствуют те элементарные события, которые содержат "успех" ровно k раз, а "неудачу" – остальные n - k раз. Число таких благоприятствующих событию { X = k } элементарных событий, равно, очевидно,  , а вероятности всех их одинаковы и по теореме умножения для независимых событий равны pkqn - k . Окончательно получаем: P { X = k }=
, а вероятности всех их одинаковы и по теореме умножения для независимых событий равны pkqn - k . Окончательно получаем: P { X = k }=  pkqn - k , а возможными значениями случайной величины X оказываются числа xk = k, k =
pkqn - k , а возможными значениями случайной величины X оказываются числа xk = k, k =
=0, 1, 2, ¼ n. Таким образом, число успехов X в схеме Бернулли – биномиальная случайная величина: X ~ B (n, p).
Пусть имеется вероятностное пространство (W, Å, P (×)) и рассматривается некоторое событие A. Обозначим его вероятность P (A)= p. Пусть испытание независимым образом повторяется n раз, причём событие A в этих n последовательных попытках наблюдалось k раз. Число k называется абсолютной частотой события A. Оно является конкретным значением случайной величины X, определённой на серии из n независимых испытаний. Ничто не мешает объявить событие A "успехом", а событие 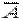 – "неудачей". Это превращает последовательность из n испытаний в схему Бернулли, а абсолютная частота события A оказывается распределённой по закону Бернулли.
– "неудачей". Это превращает последовательность из n испытаний в схему Бернулли, а абсолютная частота события A оказывается распределённой по закону Бернулли.
Геометрическое распределение также просто связано со схемой Бернулли: будем повторять попытку до появления первого "успеха". Элементарным событием в таком опыте является цепочка, у которой "успех" расположен только на последнем (k -м) месте, а на всех предыдущих местах (а их k -1) – только "неудачи": ННННН¼НУ. Свяжем с этим опытом случайную величину X – общее число попыток в опыте. Очевидно, значениями этой случайной величины могут быть xk = k, k =1, 2, 3, ¼, а их вероятности pk = qk -1 p, что и совпадает с геометрическим распределением G (p).
Числовые характеристики случайных величин:
математическое ожидание, дисперсия,
коэффициент корреляции
Наиболее полная информация о случайной величине содержится в законе её распределения. Более бедную, но зато и более конкретную информацию о ней дают её числовые характеристики. Простейшей из них является математическое ожидание, которое интерпретируется как среднее значение случайной величины. Если посмотреть на закон распределения как на распределение единичной вероятностной массы между значениями случайной величины, то в качестве среднего значения можно взять координаты центратяжести этой массы. По известным из анализа и механики формулам получаем формулы для вычисления абсциссы центра тяжести:
xp (x) dx – в непрерывном случае,
xkpk – в дискретном случае.
Вернёмся к изучению числовых характеристик случайных величин.
1°. Выше мы ввели понятие математического ожидания для дискретной и непрерывной случайных величин.
Пусть теперь ^ X – случайная величина с функцией распределения F (x). Возьмём произвольную функцию j(x).
Назовём математическим ожиданием функции j от случайной величины X число M j(X), определяемое равенством:
M j(X)= j(x) dF (x).
В частности, для непрерывной случайной величины с плотностью вероятности p (x) получаем:
M j(X)= j(x) p (x) dx,
а для дискретной случайной величины с распределением pk = P { X = xk }:
M j(X)= j(xk) pk.
В случае, когда j(x)= x, последние три формулы принимают вид:
MX = xdF (x) – в общем случае,
MX = xp (x) dx – в непрерывном случае,
MX = xkpk – в дискретном случае.
Формулы для непрерывного и дискретного случаев совпали с формулами для абсциссы центра тяжести распределения вероятностной массы, и тем самым оправдывается истолкование математического ожидания случайной величины X как среднего значения.
Для корректности определения математического ожидания следует обсудить вопрос о его существовании и единственности.
Вопрос о единственности M j(X) возникает потому, что j(X) сама является случайной величиной со своей функцией распределения F j(x) и в соответствии с нашим определением её математическое ожидание равно xdF j(x).
Для однозначности определения необходимо выполнение равенства
j(x) p (x) dx = xdF j(x)
и такое равенство действительно можно доказать: оно даёт правило замены переменных в интеграле Стилтьеса. Мы здесь вынуждены принять его без доказательства.
Вопрос о существовании математического ожидания: ясно, что в непрерывном и дискретном случае любая ограниченная случайная величина имеет математическое ожидание. Если же X может принимать сколь угодно большие значения, то в дискретном случае сумма, определяющая MX, становится бесконечным рядом, а в непрерывном – интеграл становится несобственным, причём оба могут расходиться. Очевидно, в непрерывном случае достаточным условием существования среднего значения у случайной величины является
p (x)= O ( ) при x ®±¥ (e>0),
) при x ®±¥ (e>0),
а в дискретном случае:
xkpk = O (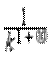 ) при k ®¥ (e>0).
) при k ®¥ (e>0).
Однако оба эти условия не являются необходимыми.
Легко также придумать примеры случайных величин, не имеющих среднего. Для непрерывного случая таким примером может служить распределение Коши. В дискретном подобный пример придумать ещё проще, если учесть, что вероятность pk можно приписать сколь угодно большим числам xk.
Если дана двумерная случайная величина (X, Y), то математическое ожидание функции j(X, Y) определяется равенствами
M j(X, Y)= j(x, y) p (x, y) dxdy – в непрерывном случае
(интеграл берётся по всей плоскости),
M j(X, Y)=j(xi, yj) pij – в дискретном случае
(сумма берётся по всем возможным значениям
двумерной случайной величины).
2°. Второй по важности числовой характеристикой случайной величины ^ X служит её дисперсия DX. Дисперсией называется
DX = M [(X - MX)2]= (x - MX)2 dF (x),
т. е. среднее значение квадрата отклонения случайной величины от её среднего. Эта формула в непрерывном случае переходит в
DX = (x - MX)2 p (x) dx,
а в дискретном в:
DX = (xk - MX)2 pk.
Если среднее есть не у всех случайных величин, то дисперсия и подавно. В дальнейшем все теоремы о MX и DX без особых оговорок формулируются лишь для тех X, которые их имеют.
Размерность дисперсии равна квадрату размерности случайной величины ^ X. Поэтому иногда удобно вместо DX рассматривать величину s X = 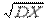 , называемую средним квадратичным отклонением случайной величины X или просто стандартом.
, называемую средним квадратичным отклонением случайной величины X или просто стандартом.
Дисперсия и стандарт мыслятся как меры разброса значений случайной величины вокруг её среднего.
3°. Докажем несколько простых утверждений:
Математическое ожидание постоянной C равно C: MC = C.
Постоянный множитель можно выносить за знак математического ожидания:
M (CX)= CMX.
Дисперсия постоянной равна нулю: DC =0.
Постоянный множитель выносится за знак дисперсии в квадрате:
D (CX)= C 2 DX.
Постоянную C можно рассматривать как частный случай дискретной случайной величины, принимающей единственное значение C с вероятностью, равной 1. Поэтому MC = C ×1= C.
Свойство M (CX)= CMX следует из определения математического ожидания как предела интегральных сумм: постоянный множитель можно выносить за знак суммы и знак интеграла.
О дисперсии:
DC = M [(C - MC)2]= M [(C - C)2]= M 0=0;
D (CX)= M [(CX - M (CX))2]= M [(CX - CM (X))2]=
= M [ C 2(C - MC)2]= C 2× M [(X - MX)2]= C 2 DX.
4°. Математическое ожидание суммы случайных величин равно сумме их математических ожиданий:
M (X + Y)= MX + MY.
6°. Ещё одна формула для дисперсии: DX = M (X 2)- M 2(X).
Действительно, DX = M [(X - MX)2]= M (X 2)- MX × MX + M [ M (X)2]=
= M (X 2)-2. M 2(X)+ M 2(X)= M (X 2)- M 2(X).
В частности, если MX =0, то DX = M (X 2).
7°. Нормированной случайной величиной X * назовём:
X *= 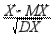 .
.
Это – безразмерная случайная величина, причём:
a) MX *=0, b) M (X *2)=1, c) DX *=1.
Действительно
MX *= M ()=  (MX - MX)=0,
(MX - MX)=0,
M (X *2)= M [  ]=
]= 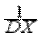 M [(X - MX)2]= DX =1,
M [(X - MX)2]= DX =1,
DX *= M (X *2)-(MX *)2=1-0=1.
8°. Если DX =0, то почти наверное X = const. Действительно,
DX = (x - MX)2 dF (x).
Интегрируемая функция (x - MX)2 неотрицательна, причём обращается в ноль, только в точке x = MX. Интегрирующая функция F (x) монотонно неубывающая, причём её наименьшее значение ³0, а наибольшее £1. Очевидно, равенство DX =0 возможно лишь в том случае, когда весь рост функции F (x) сосредоточен в точке MX, а это и означает, что X = const почти наверное.
9°. Пусть дана двумерная случайная величина (X, Y). Назовем коэффициентом корреляции двумерной случайной величины число
r = r (X, Y)= M (X *, Y *)=  .
.
Числитель здесь называется ковариацией случайных величин X и Y:
cov(X, Y)= M [(X - MX)(Y - MY)]= M (XY)- MX × MY.
Из определения коэффициента корреляции следует, что
cov(X, Y)= r × ×  .
.
Очевидно, коэффициент корреляции не меняется при линейном преобразовании случайных величин; в частности, r (X, Y)= r (X *, Y *).
Коэффициент корреляции – числовая характеристика пары случайных величин, определённых на одном и том же вероятностном пространстве, –заслужил репутацию меры линейной связи величин X и Y.
Основанием к этому служат последующие теоремы о коэффициенте корреляции.
10°. M (XY)= MX × MY +cov(X, Y) или M (XY)= MX × MY + r × × .
Действительно:
M (XY)= M {[(X - MX)+ MX ]×[(Y - MY)+ MY ]}=
= M [(X - MX)×(Y - MY)]+ MY × M (X - MX)+ MX × M (Y - MY)+ M (MX × MY)=
= MX × MY +cov(X, Y).
Если коэффициент корреляции равен нулю, то математическое ожидание произведения случайных величин равно произведению их математических ожиданий: r =0 Û M (X × Y)= MX × MY.
Случайные величины X и Y, коэффициент корреляции которых равен нулю, называются некоррелированными.
11°. Если случайные величины X и Y независимы, то M (XY)= MX × MY.
12°. Если случайные величины X и Y независимы, то они некоррелированы: r =0.
Это утверждение следует из формулы для коэффициента корреляции:
r = 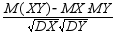 .
.
13°. Для двух произвольных случайных величин X и Y:
D (X ± Y)= DX + DY ±2 r
или
D (X ± Y)=s X 2+s Y 2±2 r s X s Y.
Для некоррелированных, тем более – для независимых случайных величин:
D (X ± Y)= DX + DY.
В частности, D (aX + b)= a 2 DX, D (X + c)= DX.
14°. Как частный случай теоремы 13° находим: D (X *± Y *)=2(1± r).
17°. Пусть наблюдается двумерная случайная величина (X, Y), при этом представляет интерес случайная величина Y, тогда как измерению доступны значения случайной величины X. Желательно по X предсказать (в каком-то смысле – наилучшим образом) Y. В качестве предсказания можно мыслить различные функции j(X): Y »j(X), а качество приближения оценивать среднеквадратической ошибкой: оптимальным считать такое приближение j(X), которое минимизирует математическое ожидание M [(Y -j(X))2].
Здесь мы найдём лучшее приближение среди всех линейных приближений, причём будем решать эту задачу для нормированных случайных величин X *, Y *, т. е. будем предполагать, что Y *» aX *± b.
Ищем такие a и b, которые минимизируют функцию
I (a, b)= M [(Y *- aX *- b)2].
Очевидно,
I (a, b)= M (Y *2)+ a 2(MX *)2+ b 2-2 aM (X * Y *)+2 bMY *+2 abMX *
и по теореме 7°:
I (a, b)=1+ a 2- b 2-2 ar.
Уравнения для нахождения экстремума:
 =2 a -2 r =0,
=2 a -2 r =0,
 =2 b =0.
=2 b =0.
Отсюда следует, что a = r, b =0 и наилучшее предсказание: Y *» rX * или:
 » r ,
» r ,
что можно переписать в виде:
Y » r  (X - MX)+ MY
(X - MX)+ MY
(именно эту формулу мы бы получили, если бы решали задачу для (X, Y), а не для (X *, Y *)).
Прямая
y = r (x - MX)+ MY
называется линией регрессии Y на X.
В частности, если X и Y – независимые случайной величины, то наша формула указывает следующее наилучшее предсказание: Y » MY и никакой информации о Y случайная величина X не содержит.
Приложение 1
Таблица – Успехи студентов учебной группы (форма)
| ФИО | Эссе 1 | Доклад и презентация 1 | Эссе 2 | Доклад и презентация 2 | Авторское исследование | Контроль 1 | Контроль 2 | Итого |
| Иванова | 10* | |||||||
| ** | ||||||||
| Блохин | ||||||||
| ……………………. | ||||||||
| ……………………… | ||||||||
| * - результаты выполнения индивидуальных заданий оцениваются преподавателем, максимальное количество баллов за каждое задание указано в верхней строке оценок студента. ** - в нижней строке – оценка работы студента в баллах, отражающая его успехи. |