Отметим, что в ряде случаев мультиколлинеарность не является таким уж серьезным «злом», чтобы прилагать существенные усилия по ее выявлению и устранению. В основном, все зависит от целей исследования.
Если основная задача модели — прогноз будущих значений зависимой переменной, то при достаточно большом коэффициенте детерминации R2(gt; 0,9) наличие мультиколлинеарности обычно не сказывается на прогнозных качествах модели (если в будущем между коррелированными переменными будут сохраняться те же отношения, что и ранее).
Если необходимо определить степень влияния каждой из объясняющих переменных на зависимую переменную, то мультиколлинеарность, приводящая к увеличению стандартных ошибок, скорее всего, исказит истинные зависимости между переменными. В этой ситуации мультиколлинеарность является серьезной проблемой.
Единого метода устранения мультиколлинеарности, годного в любом случае, не существует. Это связано с тем, что причины и последствия мультиколлинеарности неоднозначны и во многом зависят от результатов выборки.
Исключение переменной(ых) из модели
Простейшим методом устранения мультиколлинеарности является исключение из модели одной или ряда коррелированных переменных. При применении данного метода необходима определенная осмотрительность. В данной ситуации возможны ошибки спецификации, поэтому в прикладных эконометрических моделях желательно не исключать объясняющие переменные до тех пор, пока мультиколлинеарность не станет серьезной проблемой.
Получение дополнительных данных или новой выборки
Поскольку мультиколлинеарность напрямую зависит от выборки, то, возможно, при другой выборке мультиколлинеарности не будет либо она не будет столь серьезной. Иногда для уменьшения мультиколлинеарности достаточно увеличить объем выборки. Например, при использовании ежегодных данных можно перейти к поквартальным данным. Увеличение количества данных сокращает дисперсии коэффициентов регрессии и тем самым увеличивает их статистическую значимость. Однако получение новой выборки или расширение старой не всегда возможно или связано с серьезными издержками. Кроме того, такой подход может усилить автокорреляцию. Эти проблемы ограничивают возможность использования данного метода.
Изменение спецификации модели
В ряде случаев проблема мультиколлинеарности может быть решена путем изменения спецификации модели: либо изменяется форма модели, либо добавляются объясняющие переменные, не учтенные в первоначальной модели, но существенно влияющие на зависимую переменную. Если данный метод имеет основания, то его использование уменьшает сумму квадратов отклонений, тем самым сокращая стандартную ошибку регрессии. Это приводит к уменьшению стандартных ошибок коэффициентов.
Использование предварительной информации о некоторых параметрах
Иногда при построении модели множественной регрессии можно воспользоваться предварительной информацией, в частности известными значениями некоторых коэффициентов регрессии.
Вполне вероятно, что значения коэффициентов, рассчитанные для каких-либо предварительных (обычно более простых) моделей либо для аналогичной модели по ранее полученной выборке, могут быть использованы для разрабатываемой в данный момент модели.
Отбор наиболее существенных объясняющих переменных. Процедура последовательного присоединения элементов
Переход к меньшему числу объясняющих переменных может уменьшить дублирование информации, доставляемой сильно взаимозависимыми признаками. Именно с этим мы сталкиваемся в случае мультиколлинеарности объясняющих переменных.
36. способы выявления мультиколлиарности. частная корреляция
Наибольшие затруднения в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторных переменных, когда более чем два фактора связаны между собой линейной зависимостью.
Мультиколлинеарностью для линейной множественной регрессии называется наличие линейной зависимости между факторными переменными, включёнными в модель.
Мультиколлинеарность – нарушение одного из основных условий, лежащих в основе построения линейной модели множественной регрессии.
Мультиколлинеарность в матричном виде – это зависимость между столбцами матрицы факторных переменных Х:
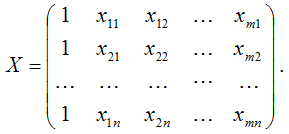
Если не учитывать единичный вектор, то размерность данной матрицы равна n*n. Если ранг матрицы Х меньше n, то в модели присутствует полная или строгая мультиколлинеарность. Но на практике полная мультиколлинеарность почти не встречается.
Можно сделать вывод, что одной из основных причин присутствия мультиколлинеарности в модели множественной регрессии является плохая матрица факторных переменных Х.
Чем сильнее мультиколлинеарность факторных переменных, тем менее надежной является оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов.
Включение в модель мультиколлинеарных факторов нежелательно по нескольким причинам:
1) основная гипотеза о незначимости коэффициентов множественной регрессии может подтвердиться, но сама модель регрессии при проверке с помощью F-критерия оказывается значимой, что говорит о завышенной величине коэффициента множественной корреляции;
2) полученные оценки коэффициентов модели множественной регрессии могут быть неоправданно завышены или иметь неправильные знаки;
3) добавление или исключение из исходных данных одного-двух наблюдений оказывает сильное влияние на оценки коэффициентов модели;
4) мультиколлинеарные факторы, включённые в модель множественной регрессии, способны сделать её непригодной для дальнейшего применения.
Конкретных методов обнаружения мультиколлинеарности не существует, а принято применять ряд эмпирических приёмов. В большинстве случаев множественный регрессионный анализ начинается с рассмотрения корреляционной матрицы факторных переменных R или матрицы (ХТХ).
Корреляционной матрицей факторных переменных называется симметричная относительно главной диагонали матрица линейных коэффициентов парной корреляции факторных переменных:

где rij – линейный коэффициент парной корреляции между i-м и j-ым факторными переменными,

На диагонали корреляционной матрицы находятся единицы, потому что коэффициент корреляции факторной переменной с самой собой равен единице.
При рассмотрении данной матрицы с целью выявления мультиколлинеарных факторов руководствуются следующими правилами:
1) если в корреляционной матрице факторных переменных присутствуют коэффициенты парной корреляции по абсолютной величине большие 0,8, то делают вывод, что в данной модели множественной регрессии существует мультиколлинеарность;
2) вычисляют собственные числа корреляционной матрицы факторных переменных λmin и λmax. Если λmin‹10-5, то в модели регрессии присутствует мультиколлинеарность. Если отношение

то также делают вывод о наличии мультиколлинеарных факторных переменных;
3) вычисляют определитель корреляционной матрицы факторных переменных. Если его величина очень мала, то в модели регрессии присутствует мультиколлинеарность.
37. пути решения проблемы мультиколлиарности
Если оцененную модель регрессии предполагается использовать для изучения экономических связей, то устранение мультиколлинеарных факторов является обязательным, потому что их наличие в модели может привести к неправильным знакам коэффициентов регрессии.
При построении прогноза на основе модели регрессии с мультиколлинеарными факторами необходимо оценивать ситуацию по величине ошибки прогноза. Если её величина является удовлетворительной, то модель можно использовать, несмотря на мультиколлинеарность. Если же величина ошибки прогноза большая, то устранение мультиколлинеарных факторов из модели регрессии является одним из методов повышения точности прогноза.
К основным способам устранения мультиколлинеарности в модели множественной регрессии относятся:
1) один из наиболее простых способов устранения мультиколлинеарности состоит в получении дополнительных данных. Однако на практике в некоторых случаях реализация данного метода может быть весьма затруднительна;
2) способ преобразования переменных, например, вместо значений всех переменных, участвующих в модели (и результативной в том числе) можно взять их логарифмы:
lny=β0+β1lnx1+β2lnx2+ε.
Однако данный способ также не способен гарантировать полного устранения мультиколлинеарности факторов;
Если рассмотренные способы не помогли устранить мультиколлинеарность факторов, то переходят к использованию смещённых методов оценки неизвестных параметров модели регрессии, или методов исключения переменных из модели множественной регрессии.
Если ни одну из факторных переменных, включённых в модель множественной регрессии, исключить нельзя, то применяют один из основных смещённых методов оценки коэффициентов модели регрессии – гребневую регрессию или ридж (ridge).
При использовании метода гребневой регрессии ко всем диагональным элементам матрицы (ХТХ) добавляется небольшое число τ: 10-6 ‹ τ ‹ 0.1. Оценивание неизвестных параметров модели множественной регрессии осуществляется по формуле:

где ln – единичная матрица.
Результатом применения гребневой регрессии является уменьшение стандартных ошибок коэффициентов модели множественной регрессии по причине их стабилизации к определённому числу.
Метод главных компонент является одним из основных методов исключения переменных из модели множественной регрессии.
Данный метод используется для исключения или уменьшения мультиколлинеарности факторных переменных модели регрессии. Суть метода заключается в сокращении числа факторных переменных до наиболее существенно влияющих факторов. Это достигается с помощью линейного преобразования всех факторных переменных xi (i=0,…,n) в новые переменные, называемые главными компонентами, т. е. осуществляется переход от матрицы факторных переменных Х к матрице главных компонент F. При этом выдвигается требование, чтобы выделению первой главной компоненты соответствовал максимум общей дисперсии всех факторных переменных xi (i=0,…,n), второй компоненте – максимум оставшейся дисперсии, после того как влияние первой главной компоненты исключается и т. д.
Метод пошагового включения переменных состоит в выборе из всего возможного набора факторных переменных именно те, которые оказывают существенное влияние на результативную переменную.
Метод пошагового включения осуществляется по следующему алгоритму:
1) из всех факторных переменных в модель регрессии включаются те переменные, которым соответствует наибольший модуль линейного коэффициента парной корреляции с результативной переменной;
2) при добавлении в модель регрессии новых факторных переменных проверяется их значимость с помощью F-критерия Фишера. При том выдвигается основная гипотеза о необоснованности включения факторной переменной xk в модель множественной регрессии. Обратная гипотеза состоит в утверждении о целесообразности включения факторной переменной xk в модель множественной регрессии. Критическое значение F-критерия определяется как Fкрит(a;k1;k2), где а – уровень значимости, k1=1 и k2=n–l – число степеней свободы, n – объём выборочной совокупности, l – число оцениваемых по выборке параметров. Наблюдаемое значение F-критерия рассчитывается по формуле:

где q – число уже включённых в модель регрессии факторных переменных.
При проверке основной гипотезы возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл›Fкрит, то основная гипотеза о необоснованности включения факторной переменной xk в модель множественной регрессии отвергается. Следовательно, включение данной переменной в модель множественной регрессии является обоснованным.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл≤Fкрит, то основная гипотеза о необоснованности включения факторной переменной xk в модель множественной регрессии принимается. Следовательно, данную факторную переменную можно не включать в модель без ущерба для её качества
3) проверка факторных переменных на значимость осуществляется до тех пор, пока не найдётся хотя бы одна переменная, для которой не выполняется условие Fнабл›Fкрит.
38. фиктивные переменные. Тест чоу
Термин “фиктивные переменные” используется как противоположность “значащим” переменным, показывающим уровень количественного показателя, принимающего значения из непрерывного интервала. Как правило, фиктивная переменная — это индикаторная переменная, отражающая качественную характеристику. Чаще всего применяются бинарные фиктивные переменные, принимающие два значения, 0 и 1, в зависимости от определенного условия. Например, в результате опроса группы людей 0 может означать, что опрашиваемый — мужчина, а 1 — женщина. К фиктивным переменным иногда относят регрессор, состоящий из одних единиц (т.е. константу, свободный член), а также временной тренд.
Фиктивные переменные, будучи экзогенными, не создают каких-либо трудностей при применении ОМНК. Фиктивные переменные являются эффективным инструментом построения регрессионных моделей и проверки гипотез.
Предположим, что на основе собранных данных была построена модель регрессии. Перед исследователем стоит задача о том, стоит ли вводить в полученную модель дополнительные фиктивные переменные или базисная модель является оптимальной. Данная задача решается с помощью метода или теста Чоу. Он применяется в тех ситуациях, когда основную выборочную совокупность можно разделить на части или подвыборки. В этом случае можно проверить предположение о большей эффективности подвыборок по сравнению с общей моделью регрессии.
Будем считать, что общая модель регрессии представляет собой модель регрессии модель без ограничений. Обозначим данную модель через UN. Отдельными подвыборками будем считать частные случаи модели регрессии без ограничений. Обозначим эти частные подвыборки как PR.
Введём следующие обозначения:
PR1 – первая подвыборка;
PR2 – вторая подвыборка;
ESS(PR1) – сумма квадратов остатков для первой подвыборки;
ESS(PR2) – сумма квадратов остатков для второй подвыборки;
ESS(UN) – сумма квадратов остатков для общей модели регрессии.

– сумма квадратов остатков для наблюдений первой подвыборки в общей модели регрессии;
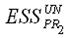
– сумма квадратов остатков для наблюдений второй подвыборки в общей модели регрессии.
Для частных моделей регрессии справедливы следующие неравенства:

Условие (ESS(PR1)+ESS(PR2))= ESS(UN) выполняется только в том случае, если коэффициенты частных моделей регрессии и коэффициенты общей модели регрессии без ограничений будут одинаковы, но на практике такое совпадение встречается очень редко.
Основная гипотеза формулируется как утверждение о том, что качество общей модели регрессии без ограничений лучше качества частных моделей регрессии или подвыборок.
Альтернативная или обратная гипотеза утверждает, что качество общей модели регрессии без ограничений хуже качества частных моделей регрессии или подвыборок
Данные гипотезы проверяются с помощью F-критерия Фишера-Снедекора.
Наблюдаемое значение F-критерия сравнивают с критическим значением F-критерия, которое определяется по таблице распределения Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n-2m-2.
Наблюдаемое значение F-критерия рассчитывается по формуле:где ESS(UN)– ESS(PR1)– ESS(PR2) – величина, характеризующая улучшение качества модели регрессии после разделения её на подвыборки;
m – количество факторных переменных (в том числе фиктивных);
n – объём общей выборочной совокупности.
При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл>Fкрит, то основная гипотеза отклоняется, и качество частных моделей регрессии превосходит качество общей модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т.е. Fнабл?Fкрит, то основная гипотеза принимается, и разбивать общую регрессию на подвыборки не имеет смысла.
Если осуществляется проверка значимости базисной регрессии или регрессии с ограничениями (restricted regression), то выдвигается основная гипотеза вида:
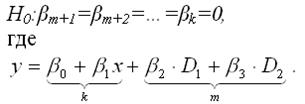
Справедливость данной гипотезы проверяется с помощью F-критерия Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n–k–1.
Наблюдаемое значение F-критерия преобразуется к виду:

При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл›Fкрит, то основная гипотеза отклоняется, и в модель регрессии необходимо вводить дополнительные фиктивные переменные, потому что качество модели регрессии с ограничениями выше качества базисной или ограниченной модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл?Fкрит, то основная гипотеза принимается, и базисная модель регрессии является удовлетворительной, вводить в модель дополнительные фиктивные переменные не имеет смысла.
39. система одновременных уравнений (эндогенные, экзогенные, лаговые переменные). Экономически значимые примеры систем одновременных уравнений
До сих пор мы рассматривали эконометрические модели, задаваемые уравнениями, выражающими зависимую (объясняемую) переменную через объясняющие переменные. Однако реальные экономические объекты, исследуемые с помощью эко-нометрических методов, приводят к расширению понятия эко-нометрической модели, описываемой системой регрессионных уравнений и тождеств1.
1 В отличие от регрессионных уравнений тождества не содержат подлежащих оценке параметров модели и не включают случайной составляющей.
Особенностью этих систем является то, что каждое из уравнений системы, кроме «своих» объясняющих переменных, может включать объясняемые переменные из других уравнений. Таким образом, мы имеем не одну зависимую переменную, а набор зависимых (объясняемых) переменных, связанных уравнениями системы. Такую систему называют также системой одновременных уравнений, подчеркивая тот факт, что в системе одни и те же переменные одновременно рассматриваются как зависимые в одних уравнениях и независимые в других.
Системы одновременных уравнений наиболее полно описывают экономический объект, содержащий множество взаимосвязанных эндогенных (формирующихся внутри функционирования объекта) и экзогенных (задаваемых извне) переменных. При этом в качестве эндогенных и экзогенных могут выступать лаговые (взятые в предыдущий момент времени) переменные.
Классическим примером такой системы является модель спроса Qd и предложения Qs (см. § 9.1), когда спрос на товар определятся его ценой Р и доходом потребителя /, предложение товара — его ценой Р и достигается равновесие между спросом и предложением:
Qd=Qs.
В этой системе экзогенной переменной выступает доход потребителя /, а эндогенными — спрос (предложение) товара Qd = Q»• = Q и цена товара (цена равновесия) Р.
В другой модели спроса и предложения в качестве объясняющей предложение Qf переменной может быть не только цена товара Р в данный момент времени /, т.е. Рь но и цена товара в предыдущий момент времени Ptь т.е. лаговая эндогенная переменная:
й'=Р4+Р5^+Рб^-1+Є2.
Обобщая изложенное, можно сказать, что эконометринеская модель позволяет объяснить поведение эндогенных переменных в зависимости от значений экзогенных и лаговых эндогенных переменных (иначе — в зависимости от предопределенных, т.е. заранее определенных, переменных).
Завершая рассмотрение понятия эконометрической модели, следует отметить следующее. Не всякая экономико-математическая модель, представляющая математико-статистическое описание исследуемого экономического объекта, может считаться эконометрической. Она становится эконометрической только в том случае, если будет отражать этот объект на основе характеризующих именно его эмпирических (статистических) данных.
40. косвенный метод наименьших квадратов
Если i -е стохастическое уравнение структурной формы идентифицируемо точно, то параметры этого уравнения (коэффициенты уравнения и дисперсия случайной ошибки) восстанавливаются по параметрам приведенной системы однозначно. Поэтому для оценивания параметров такого уравнения достаточно оценить методом наименьших квадратов коэффициенты каждого из уравнений приведенной формы методом наименьших квадратов (отдельно для каждого уравнения) и получить оценку ковариационной матрицы Q ошибок в приведенной форме, после чего воспользоваться соотношениями ПГ = В и Е = ГТQT, подставляя в них вместо П оцененную матрицу коэффициентов приведенной формы П и оцененную ковариационную матрицу ошибок в приведенной форме £2. Такая процедура называется косвенным методом наименьших квадратов (ILS indirect least squares). Полученные в результате оценки коэффициентов i -го стохастического уравнения структурной формы наследуют свойство состоятельности оценок приведенной формы. Однако они не наследуют таких свойств оценок приведенной формы как несмещенность и эффективность из-за того, что получаются в результате некоторых нелинейных преобразований. Соответственно, при небольшом количестве наблюдений даже у этих естественных оценок может возникать заметное смещение. В связи с этим при рассмотрении различных методов оценивания коэффициентов структурных уравнений в первую очередь заботятся об обеспечении именно состоятельности получаемых оценок.
41. проблемы идентифицируемости систем одновременных уравнений
При правильной спецификации модели задача идентификация системы уравнений сводится к корректной и однозначной оценке ее коэффициентов. Непосредственная оценка коэффициентов уравнения возможна лишь в системах внешне не связанных уравнений, для которых выполняются основные предпосылки построения регрессионной модели, в частности, условие некоррелированности факторных переменных с остатками.
В рекурсивных системах всегда возможно избавление от проблемы коррелированности остатков с факторными переменными путем подстановки в качестве значений факторных переменных не фактических, а модельных значений эндогенных переменных, выступающих в качестве факторных переменных. Процесс идентификации осуществляется следующим образом:
1. Идентифицируется уравнение, в котором в качестве факторных не содержатся эндогенные переменные. Находится расчетное значение эндогенной переменной этого уравнения.
2. Рассматривается следующее уравнение, в котором в качестве факторной включена эндогенная переменная, найденная на предыдущем шаге. Модельные (расчетные) значения этой эндогенной переменной обеспечивают возможность идентификации этого уравнения и т. д.
В системе уравнений в приведенной форме проблема коррелированности факторных переменных с отклонениями не возникает, так как в каждом уравнении в качестве факторных переменных используются лишь предопределенные переменные. Таким образом, при выполнении других предпосылок рекурсивная система всегда идентифицируема.
При рассмотрении системы одновременных уравнений возникает проблема идентификации.
Идентификация в данном случае означает определение возможности однозначного пересчета коэффициентов системы в приведенной форме в структурные коэффициенты.
Структурная модель (7.3) в полном виде содержит  параметров, которые необходимо определить. Приведенная форма модели в полном виде содержит
параметров, которые необходимо определить. Приведенная форма модели в полном виде содержит  параметров. Следовательно, для определения неизвестных параметров структурной модели можно составить уравнений. Такие системы являются неопределенными и параметры структурной модели в общем случае не могут быть однозначно определены.
параметров. Следовательно, для определения неизвестных параметров структурной модели можно составить уравнений. Такие системы являются неопределенными и параметры структурной модели в общем случае не могут быть однозначно определены.
Чтобы получить единственно возможное решение необходимо предположить, что некоторые из структурных коэффициентов модели ввиду слабой их взаимосвязи с эндогенной переменной из левой части системы равны нулю. Тем самым уменьшится число структурных коэффициентов модели. Уменьшение числа структурных коэффициентов модели возможно и другими путями: например, путем приравнивания некоторых коэффициентов друг к другу, т. е. путем предположений, что их воздействие на формируемую эндогенную переменную одинаково и пр.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
· идентифицируемые;
· неидентифицируемые;
· сверхидентифицируемые.
Модель идентифицируема, если все структурные ее коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, т. е. если число параметров структурной модели равно числу параметров приведенной формы модели.
Модель неидентифицируема, если число коэффициентов приведенной модели меньше числа структурных коэффициентов, и в результате структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели.
Модель сверхидентифицируема, если число коэффициентов приведенной модели больше числа структурных коэффициентов. В этом случае на основе коэффициентов приведенной формы можно получить два или более значений одного структурного коэффициента. Сверхидентифицируемая модель в отличие от неидентифицируемой модели практически решаема, но требует для этого специальных методов нахождения параметров.
Чтобы определить тип структурной модели необходимо каждое ее уравнение проверить на идентифицируемость.
Модель считается идентифицируемой, если каждое уравнение системы идентифицируемо. Если хотя бы одно из уравнений системы неидентифицируемо, то и вся модель считается неидентифицируемой. Сверхидентифицируемая модель кроме идентифицируемых содержит хотя бы одно сверхидентифицируемое уравнение.
42. трехшаговый метод наименьших квадратов
Наиболее эффективная процедура оценивания систем регрессионных уравнений сочетает метод одновременного оценивания и метод инструментальных переменных. Соответствующий метод называется трехшаговым методом наименьших квадратов. Он заключается в том, что на первом шаге к исходной модели (9.2) применяется обобщенный метод наименьших квадратов с целью устранения корреляции случайных членов. Затем к полученным уравнениям применяется двухшаговый метод наименьших квадратов.
Очевидно, что если случайные члены (9.2) не коррелируют, трехшаговый метод сводится к двухшаговому, в то же время, если матрица В — единичная, трехшаговый метод представляет собой процедуру одновременного оценивания уравнений как внешне не связанных.
Применим трехшаговый метод к рассматриваемой модели (9.24):
ai=19,31; Pi=l,77; а2=19,98; р2=0,05; у=1,4. (6,98) (0,03) (4,82) (0,08) (0,016)
Так как коэффициент р2 незначим, то уравнение зависимости У от X имеет вид:
у =16,98 + 1,4х
Заметим, что оно практически совпадает с уравнением (9.23).
Как известно, очищение уравнения от корреляции случайных членов — процесс итеративный. В соответствии с этим при использовании трехшагового метода компьютерная программа запрашивает число итераций или требуемую точность. Отметим важное свойство трехшагового метода, обеспечивающего его наибольшую эффективность.
При достаточно большом числе итераций оценки трехшагового метода наименьших квадратов совпадают с оценками максимального правдоподобия.
Как известно, оценки максимального правдоподобия на больших выборках являются наилучшими.
43. понятие экономических рядов динамики. Общий вид мультипликативной и аддитивной модели временного ряда.


44. моделирование тенденции временного ряда, сезонных и циклических колебаний.
Существует несколько подходов к анализу структуры временных рядов, содержащих сезонные или циклические колебания.
1 ПОДХОД. Расчет значений сезонной компоненты методом скользящей средней и построение аддитивной или мультипликативной модели временного ряда.
Общий вид аддитивной модели: 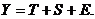 (Т - трендовая компонента, S - сезонная, Е - случайная).
(Т - трендовая компонента, S - сезонная, Е - случайная).
Общий вид мультипликативной модели: 
Выбор модели на основе анализа структуры сезонных колебаний (если амплитуда колебаний приблизительно постоянна – аддитивная, если возрастает/уменьшается – мультипликативная).
Построение моделей сводится к расчету значений T,S,E для каждого уровня ряда.
Построение модели:
1.выравнивание исходного ряда методом скользящей средней;
2.расчет значений компоненты S;
3.Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных (T+E) в аддитивной или (T*E) в мультипликативной модели.
4.Аналитическое выравнивание уровней (T+E) или (T*E) и расчет значения Т с использованием полученного уровня тренда.
5.Расчет полученных по модели значений (T+S) или (T*S).
6.Расчет абсолютных и/или относительных ошибок.
Если полученные значения ошибок не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок Е для анализа взаимосвязи исходного ряда и др. временных рядов.
2 ПОДХОД. Построение модели регрессии с включением фактора времени и фиктивных переменных. Количество фиктивных переменных в такой модели должно быть на единицу меньше числа моментов (периодов) времени внутри одного цикла колебаний. Например, при моделировании поквартальных данных модель должна включать четыре независимые переменные – фактор времени и три фиктивные переменные. Каждая фиктивная переменная отражает сезонную (циклическую) компоненту временного ряда для какого-либо одного периода. Она равна единице (1) для данного периода и нулю (0) для всех остальных. Недостаток модели с фиктивными переменными – наличие большого количества переменных.
45. автокорреляционная функция. Ее использование для выявления наличия или отсутствия трендовой и циклической компоненты
Автокорреляция уровней временного ряда.
При наличии во временном ряде тенденции и циклических колебаний каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда.
Количественно автокорреляцию уровней ряда измеряют с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутые на несколько шагов во времени.
Пусть, например, дан временной ряд 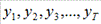 . Определим коэффициент корреляции между рядами
. Определим коэффициент корреляции между рядами  и
и  .
.
Одна из рабочих формул расчета коэффициента корреляции имеет вид:
 ,
, 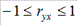 (1)
(1)
где 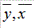 - средние значения соответствующих переменных, а
- средние значения соответствующих переменных, а  и
и  - их среднеквадратические отклонения.
- их среднеквадратические отклонения.
 ,
,  ,
, 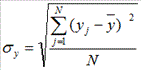 ,
,  (2)
(2)
В нашем случае  ,
, 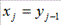 и изменение параметра
и изменение параметра  надо начинать с 2, чтобы в обоих рядах соответствующие члены были определены. С учетом этих замечаний, получим:
надо начинать с 2, чтобы в обоих рядах соответствующие члены были определены. С учетом этих замечаний, получим:
 ,
,  ,
,
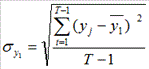 ,
,  .
.
С учетом того, что при больших значениях  отношение
отношение  близко к 1, приведенная выше формула имеет вид:
близко к 1, приведенная выше формула имеет вид:
 (3)
(3)
Эту величину называют коэффициентом автокорреляции уровней временного ряда первого порядка, т.к. он измеряет зависимость между соседними уровнями временного ряда и  , т.е. при лаге 1. Лагом называют число периодов, по которым рассчитывается коэффициент автокорреляции.
, т.е. при лаге 1. Лагом называют число периодов, по которым рассчитывается коэффициент автокорреляции.
Аналогично можно определять коэффициенты автокорреляции второго и более высоких порядков. Так коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями и  временного ряда, т.е. при лаге 2. Он определяется по формуле:
временного ряда, т.е. при лаге 2. Он определяется по формуле:
 (4)
(4)
где 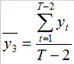 ,
,  .
.
Заметим, что с увеличением лага число пар значений, по которым рассчитывается коэффициент корреляции, уменьшается. Обычно лаг не допускается равным числу, превышающему четверть числа наблюдений.
Отметим два важных свойства коэффициентов автокорреляции.
Во-первых, коэффициенты автокорреляции считаются по аналогии с линейным коэффициентом корреляции, т.е. они характеризуют только тесноту линейной связи двух рассматриваемых уровней временного ряда. Поэтому по коэффициенту автокорреляции можно судить только о наличии линейной (или близкой к линейной) тенденции. Для временных рядов, имеющих сильную нелинейную тенденцию (например, экспоненту), коэффициент автокорреляции уровней может приближаться к нулю.
Во-вторых, по знаку коэффициента автокорреляции нельзя делать вывод о возрастающей, или убывающей тенденции в уровнях временного ряда. Знач