Рассмотрим подробнее метод главных компонент – вариант метода главных факторов. Основная модель метода главных компонент записывается в матричном виде следующим образом:
Z = A P,
где Z – матрица стандартизованных исходных данных,
A – факторное отображение,
P – матрица значений факторов.
Матрица Z имеет размер т х п, матрица A имеет размер т х r, матрица P имеет размер r х п,
где т – количество переменных (векторов данных),
n – количество индивидуумов (элементов одного вектора),
r – количество выделенных факторов.
Как видно из приведенного выше выражения, модель компонентного анализа содержит только общие для имеющихся векторов факторы.
Матрица стандартизованных исходных данных определяется из матрицы исходных данных Y (ее размер т х п) по формуле
 , i = 1, 2, …, m, j = 1, 2, …, n,
, i = 1, 2, …, m, j = 1, 2, …, n,
где  – элемент матрицы исходных данных,
– элемент матрицы исходных данных,
 – среднее значение,
– среднее значение,
 – стандартное отклонение.
– стандартное отклонение.
Для вычисления корреляционной матрицы – основного элемента факторного анализа – имеет место простое соотношение
 ,
,
где R – корреляционная матрица; она имеет размер т х т,
' – символ транспонирования.
На главной диагонали матрицы R стоят значения, равные 1. Эти значения называются общностями и обозначаются как 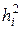 , являясь мерой полной дисперсии переменной.
, являясь мерой полной дисперсии переменной.
Неизвестными являются матрицы A и P. Матрица A может быть найдена из основной теоремы факторного анализа
R = A C A'
где C – корреляционная матрица, отражающая связь между факторами.
Если C = I, то говорят об ортогональных факторах, если С ≠ I, говорят о косоугольных факторах. Здесь I – единичная матрица. Для матрицы C справедливо соотношение
 .
.
Нами рассматривается только случай ортогональных факторов, для которых
R = A A'
Модель классического факторного анализа содержит ряд общих факторов и по одному характерному фактору на каждую переменную.
Первая из приведенных в разделе формул является основной моделью факторного анализа для метода главных компонент. Число главных компонент всегда меньше либо равно числу переменных.
ПРОБЛЕМА ВРАЩЕНИЯ
Оси координат, соответствующие выделенным факторам, ортогональны, и их направления устанавливаются последовательно, по максимуму оставшейся дисперсии. Но полученные таким образом координатные оси большей частью содержательно не интерпретируются. Поэтому получают более предпочтительное положение системы координат путем вращения этой системы вокруг ее начала. Пространственная конфигурация векторов в результате применения этой процедуры остается неизменной. Целью вращения является нахождение одной из возможных систем координат для получения так называемой простой факторной структуры. Применяется популярный метод вращения VARIMAX.
КРИТЕРИИ МАКСИМАЛЬНОГО ЧИСЛА ФАКТОРОВ
Существует несколько критериев оценки максимального числа удерживаемых факторов. Критерии, основанные на анализе определителей (детерминантов) исходной и воспроизведенной корреляционной матриц, не показывают стабильности. Критерии, основанные на величине собственных значений корреляционной матрицы, в конечном счете приводят к анализу процента дисперсии, выделенной факторами. Все общие факторы, число которых равно числу параметров, выделяют 100% дисперсии. Если сумма процентов дисперсии превышает величину 100%, то это означает: при вычислении собственных значений корреляционной матрицы были получены отрицательные собственные значения и, как следствие, комплексные собственные вектора, что может означать некорректную редукцию исходной корреляционной матрицы.
ВИЗУАЛИЗАЦИЯ РЕЗУЛЬТАТОВ ФАКТОРНОГО АНАЛИЗА
Пусть в эксперименте получены некоторые опытные данные, представляющие собой измерения трех параметров, обозначенных цифрами 1, 2 и 3. В результате проведенных расчетов были выделены два фактора (две главные компоненты), обозначенные буквами A и B.
Из рис. VII.3 видно, что вектора данных четко распадаются на две группы: одну группу, включающую в себя параметр 1 и параметр 2 и другую группу, включающую в себя параметр 3. Таким образом, по результатам расчета можно выдвинуть гипотезы:
1. Параметр 1 и параметр 2 имеют сильную взаимную линейную корреляцию.
2. Параметр 3 слабо зависит от параметров 1 и 2 в рассматриваемых сериях эксперимента.
Указание
В эксперименте достаточно измерять не три параметра, а только два: параметр 1 (или 2) и параметр 3. Это послужит снижению стоимости эксперимента практически без потери точности выводов.

Рис. VII.3. Изученные параметры 1, 2 и 3 в пространстве главных компонент, которым соответствуют фактор A и фактор B
ПРИМЕР VII.1
В одном из районов выявлено месторождение золота, приуроченное к зоне развития калиевых метасоматитов, а также ряд непромышленных по масштабу проявлений золоторудной и полиметаллической минерализации.
В рудах месторождения и окружающих их ореолах рассеяния золото ассоциирует с оловом и мышьяком, а на верхних горизонтах также с серебром, свинцом и сурьмой. Для окружающих неизмененных пород характерна положительная корреляционная связь между калием, ураном и торием. Непосредственно вблизи рудных тел в результате калиевого метасоматоза эта связь нарушается.
Данные особенности месторождения могут быть использованы для разбраковки многочисленных геохимических аномалий, выявленных в этом районе при проведении металлометрической съемки.
К перспективным объектам должны быть отнесены в первую очередь комплексные аномалии с характерными для месторождения ассоциациями элементов, пространственно совпадающие с участками проявления калиевого метасоматоза.
В табл. VII.1 приведены содержания химических элементов в пробах метасоматитов по одному из аномальных участков района.
Таблица VII.1. Содержание типоморфных элементов в метасоматитах
| № проб | Ag | Pb | Sn | As | Sb | Au | K | U | Th |
| 0,1 | 0,8 | 0,01 | |||||||
| 0,2 | |||||||||
| 0,2 | 0,8 | 0,5 | 0,1 | ||||||
| 0,5 | 0,1 | ||||||||
| 0,6 | 0,5 | 0,1 | |||||||
| 3,5 | 4,8 | 0,3 | 0,4 | 0,1 | |||||
| 0,5 | 0,2 | 0,8 | 0,3 | 0,2 | |||||
| 0,1 | 0,5 | ||||||||
| 0,3 | 0,5 | 0,1 | 0,5 | 0,1 | |||||
| 0,2 | 0,1 | 0,3 | 0,1 | 0,01 | |||||
| 0,2 | |||||||||
| 0,1 | 0,5 | 0,5 | 0,8 | 0,2 | |||||
| 0,1 | 0,7 | 0,1 | |||||||
| 0,5 | 0,1 | ||||||||
| 0,5 | 0,5 | 0,2 | 0,1 | ||||||
| 0,1 | |||||||||
| 0,7 | 0,3 | 0,1 | 0,2 | 0,01 | |||||
| 0,4 | 0,5 | 0,1 | 0,1 | 0,1 | |||||
| 0,1 | 0,5 | 0,5 | 0,3 | ||||||
| 0,5 | 0,1 | 0,1 | |||||||
| 0,2 | 0,1 | 0,8 | 0,2 | 0,4 | 0,01 | ||||
| 0,1 | 0,3 | 0,6 | 0,3 | 0,02 | 0,03 | ||||
| 0,1 | |||||||||
| 0,1 | 0,5 | 0,5 | 0,01 | 0,01 | |||||
| 0,2 | 0,3 | 0,1 | 0,5 | 0,1 | 0,1 | ||||
| 0,1 | 0,6 | 0,1 | 0,6 | 0,02 | 0,02 | ||||
| 0,3 | 0,1 | 0,2 | |||||||
| 0,2 | 0,1 | 0,1 | |||||||
| 0,6 | 0,1 | 0,2 | 0,2 | 0,5 | |||||
| 0,3 | 0,1 | 0,01 | |||||||
| 0,1 | 0,1 | 0,3 | 0,1 | ||||||
| 0,1 | |||||||||
| 0,6 | 0,2 | 0,5 | 0,5 | ||||||
| 0,2 | 0,5 | 0,2 | 0,1 | ||||||
| 0,7 |
Требуется
1) выявить геохимические ассоциации элементов;
2) определить, относятся ли данные метасоматиты к рудоносным;
3) оценить уровень эрозионного среза рудной зоны;
4) на поисковом профиле определить наиболее перспективные участки для первоочередного бурения.
Решение
1. Для выполнения корреляционного анализа введите в диапазон A1:I37 рабочей книги Excel названия столбцов и исходные данные из табл. VII.1 по столбцам: A – Ag, B – Pb, C – Sn, D – As, E – Sb, F – Au, G – K, H – U, I – Th.
Затем в меню Сервис выберите пункт Анализ данных и далее укажите строку Корреляция. В появившемся диалоговом окне укажите Входной интервал A1:I37. Укажите, что данные рассматриваются по столбцам. Установите флажок в поле Метки в первой строке. Укажите выходной диапазон. Для этого поставьте флажок в левое поле Выходной интервал и в правое поле ввода Выходной интервал введите K2. Нажмите кнопку OK.
Результаты анализа. В выходном диапазоне получаем корреляционную матрицу. Подразумевается, что в пустых клетках в правой верхней половине таблицы находятся те же коэффициенты корреляции, что и в нижней левой (симметрично расположенные относительно диагонали).
Интерпретация результатов. По данным расчета матрицы видно, что максимальная корреляция между содержанием Sn и As – 0.9837, то есть существует практически линейная связь между их содержанием. Для более удобной интерпретации корреляционной матрицы скопируйте из каждого столбца данные друг за другом в столбец O, начиная с O14, в столбец N поместите соответствующие обозначения элементов из крайнего левого столбца матрицы, а в столбец M поместите обозначение соответствующего элемента из верхней строки матрицы. Отсортируйте диапазон M14:O58 по столбцу O в порядке убывания. Коэффициенты корреляции с 0,983719 по 0,754787 – высокие, с 0,640942 по 0,501725 – средние, с 0,485918 по 0,381287 – низкие, с 0,298283 и ниже – незначимые (см. табл. VII.2).
Таблица VII.2. Коэффициенты корреляции между элементами месторождения золота в порядке убывания
| Ag | Ag | ||
| Pb | Pb | ||
| Sn | Sn | ||
| As | As | ||
| Sb | Sb | ||
| Au | Au | ||
| K | K | ||
| U | U | ||
| Th | Th | ||
| Sn | As | 0,983719 | Высокие |
| Ag | Pb | 0,970995 | |
| Pb | Sb | 0,932534 | |
| Ag | Sb | 0,928558 | |
| U | Th | 0,873059 | |
| Au | K | 0,815275 | |
| Sn | Au | 0,764751 | |
| As | Au | 0,754787 | |
| Pb | K | 0,640942 | Средние |
| Ag | K | 0,602096 | |
| Ag | Au | 0,571473 | |
| Pb | Au | 0,558501 | |
| Sb | K | 0,54045 | |
| Sn | K | 0,520355 | |
| As | K | 0,501725 | |
| Sb | Au | 0,485918 | Низкие |
| As | Th | 0,444563 | |
| Sn | Th | 0,41351 | |
| K | Th | 0,381287 | |
| As | U | 0,298283 | Незначимые |
| Sn | U | 0,291818 | |
| Au | Th | 0,26272 | |
| K | U | 0,161386 | |
| Au | U | 0,102603 | |
| Pb | Th | -0,05304 | |
| Pb | Sn | -0,06861 | |
| Ag | Sn | -0,07128 | |
| Pb | As | -0,07188 | |
| Ag | As | -0,07419 | |
| Sb | Th | -0,11928 | |
| Ag | Th | -0,11955 | |
| Sn | Sb | -0,1316 | |
| As | Sb | -0,13211 | |
| Sb | U | -0,18041 | |
| Pb | U | -0,18825 | |
| Ag | U | -0,23653 |
Связь между золотом (Au) и оловом (Sn) – 0,7647 – высокий коэффициент корреляции, связь между золотом (Au) и мышьяком (As) – 0,7547 – высокий коэффициент корреляции; связь между золотом (Au) и серебром (Ag) – 0,5714 – средний коэффициент корреляции, связь между золотом (Au) и свинцом (Pb) – 0,5585 – средний коэффициент корреляции, связь между золотом (Au) и сурьмой (Sb) – 0,4859 – низкий коэффициент корреляции. Связь между калием (K) и ураном (U) – 0,1613 – незначимый коэффициент корреляции, между калием (K) и торием (Th) – 0,3812 – низкий коэффициент корреляции, между ураном (U) и торием (Th) – 0,8730 – высокий коэффициент корреляции.
Таким образом, можно заключить, что месторождение является рудоносным и рассматриваемый срез относится к верхним горизонтам; для определения на поисковом профиле наиболее перспективных участков для первоочередного бурения следует рассмотреть связь между калием, ураном и торием, так как к перспективным объектам должны быть отнесены в первую очередь комплексные аномалии с характерными для месторождения ассоциациями элементов, пространственно совпадающие с участками проявления калиевого метасоматоза.
2. Скопируйте диапазон A1:B37 в диапазон A41:B77. В столбце C рассчитайте квадраты разностей для значений в столбцах A и B по формуле =(A42-B42)^2 для строки 42. Скопируйте эту формулу методом автозаполнения в диапазон С42:С77. В ячейке С78 найдите через автосумму для диапазона С42:С77 общую сумму. В ячейке С79 найдите квадратный корень из этой суммы по формуле =КОРЕНЬ(C78). Это евклидова метрика для пары Ag–Pb. Аналогично можно рассчитать евклидовы метрики для всех остальных пар и расположить их в общую матрицу наподобие корреляционной – матрицу евклидовых метрик. На основании этой матрицы евклидовых метрик можно позднее вручную построить дендрограмму по результатам расчета, а также выделить заданное число кластеров по построенной дендрограмме. Эту процедуру удобнее осуществить в пакете STATISTICA.
3. Создать в программе Statistica файл данных, используя табл. VII.1.
4. Провести корреляционный анализ всей выборки. Для этого в меню с основными процедурами Statistics выбрать Basic Statistics/Tables, а в появившемся его меню – Correlation matrices.
В появившемся диалоговом окне Product-Moment and Partial Correlations: нажать на вкладке Quick кнопку Summary: Correlation Matrix и в диалоговом окне Select one or two variable lists указать для First variable list: 1–9. Далее нажать OK. Результатом будет расчет коэффициентов корреляции – рис. VII.4. Коэффициенты, указывающие на наличие связи между элементами – выделены красным цветом.

Рис. VII.4. Расчет коэффициентов корреляции
5. Провести кластерный анализ для выделения ассоциаций химических элементов, используя графическую и табличную формы. Для этого в меню с основными процедурами S tatistics выбрать Multivariate Exploratory Techniques, а в появившемся его меню – Cluster Analysis.
В появившемся диалоговом окне Clustering Method (см. рис. VII.5) выбрать Joining (tree clustering).
Рис. VII.5. Выбор метода кластеризации
В появившемся диалоговом окне Cluster Analysis: Joining (Tree Clustering): на вкладке Quick нажать кнопку Variables (рис. VII.6) и появившемся диалоговом окне Select variables for the analysis нажать кнопку Select All (рис. VII.7). Вернуться в диалоговое окно Cluster Analysis: Joining (Tree Clustering): ина вкладке Advanced, используя установленные по умолчанию Variables (columns) из раздела Cluster, Complete Linkage (одиночная связь (метод ближайшего соседа)) в разделе Amalgamation (linkage) rule и Euclidean distance (евклидова метрика) в разделе Distance measures, далее нажать кнопку OK (рис. VII.8). В появившемся диалоговом окне Joining Results: установлен по умолчанию флажок Rectangular branches (прямоугольные ветви), нажать кнопку Vertical icicle plot (рис. VII.9). На рис. VII.10 представлена получившаяся в результате дендрограмма. При очищенном переключателе Rectangular branches результатом будет дендрограмма, представленная на рис. VII.11.

Рис. VII.6. Диалоговое окно Cluster Analysis: Joining (Tree Clustering):

Рис. VII.7. Выбор переменных для кластерного анализа

Рис. VII.8. Выбор метода объединения и метрики

Рис. VII.9. Диалоговое окно Joining Results:

Рис. VII.10. Прямоугольная дендрограмма ассоциаций элементов

Рис. VII.11. Дендрограмма ассоциаций элементов
Вы можете масштабировать дендрограмму к стандартизированному масштабу dlink/dmax*100 переключателем. Когда выбираете этот переключатель, горизонтальная ось (или вертикальная ось для вертикальных графиков) будет масштабироваться в процентах, определенных, как dlink/dmax*100. Таким образом, это процент от диапазона от максимального до минимального расстояния в данных. Если этот переключатель очищен, то масштаб будет основан на предварительно выбранной мере расстояния.
Полученная дендрограмма позволяет выделить следующие ассоциации элементов: Au–Sb, Au–Sb–Ag, As–Sn, Au–Sb–Ag–As–Sn, Au–Sb–Ag–As–Sn–Th, Au–Sb–Ag–As–Sn–Th–U, Au–Sb–Ag–As–Sn–Th–U–K.
Вернуться в диалоговое окно Joining Results:, нажать кнопку Amalgamation schedule на вкладке Advanced. На рис. VII.12 представлена получившаяся в результате электронная таблица результатов. Amalgamation schedule перечисляет по строкам объекты (элементы), которые соединены вместе на соответствующих расстояниях (в крайнем левом столбце электронной таблицы).
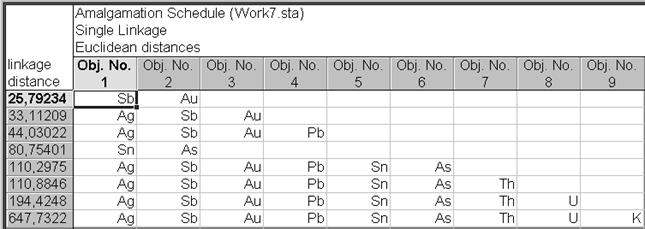
Рис. VII.12. Результат выполнения Amalgamation schedule
Вернуться в диалоговое окно Joining Results:, нажать кнопку Graph of amalgamation schedule. На рис. VII.13 представлен получившийся в результате график. Этот график может быть очень полезен, предлагая сокращение дендрограммы. В дендрограмме все большие и большие кластеры формируются из большего и большего разнообразия в пределах кластера. Этот же график показывает ровное плато, и это означает, что кластеры были сформированы по существу на одном и том же расстоянии. Это расстояние может быть оптимально сокращено при решении вопроса о том, сколько оставить кластеров, чтобы интерпретировать результаты.

Рис. VII.13. Результат выполнения Graph of amalgamation schedule.
В диалоговом окне Joining Results: нажать кнопку Distance matrix. На рис. VII.14 представлена матрица дистанционных расстояний, рассчитанная на основе евклидовой метрики. Кнопка Descriptive Statistic диалогового окна Joining Results: выводит дескриптивную статистику – средние и стандартные отклонения для изменений (рис. VII.15). Кнопка Matrix диалогового окна Joining Results: выводит дистанционную матрицу и дескриптивную статистику (рис. VII.16). Сравните результат расчета коэффициентов дистанционной матрицы с получившимися в электронных таблицах Excel евклидовыми метриками для соответствующих пар элементов.

Рис. VII.14. Матрица дистанционных расстояний

Рис. VII.15. Дескриптивная статистика

Рис. VII.16. Результат выполнения Matrix
Итак, имеем 3 кластера: (Au–Sb–Ag–Pb), (As–Sn–Th–U) и (K).
6. Провести кластерный анализ для выделения ассоциаций химических элементов методом K-средних. Для этого в меню с основными процедурами Statistics выбрать Multivariate Exploratory Techniques, а в появившемся его меню – Cluster Analysis.
В появившемся диалоговом окне Clustering Method (см. рис. VII.17) выбрать K-means clustering.
Рис. VII.17. Выбор метода кластеризации
В появившемся диалоговом окне Cluster Analysis: K-means clustering: на вкладке Quick нажать кнопку Variables и появившемся диалоговом окне Select variables for the analysis нажать кнопку Select All. Вернуться в диалоговое окно Cluster Analysis: K-means clustering: и на вкладке Advanced, используя установленную по умолчанию в списке Cluster: строку Variables (columns), установить в разделе Number of clusters количество кластеров – 3 (рис. VII.18).

Рис. VII.18. Установка параметров Cluster Analysis: K-means clustering:
Раздел Initial cluster centers – выборы в этой группе управляют способом, которым вычисляются начальные центры кластера. По умолчанию в этом разделе установлен переключатель Sort distances and take observations at constant intervals. Если Вы выбираете этот переключатель, расстояния между всеми объектами будут сначала сортироваться и затем, выраженные в постоянных величинах, будет выбраны как начальные центры кластера.