В методе МНК предполагается ряд ограничений на поведение случайного слагаемого e (условия Гаусса – Маркова).
1.Нулевое математическое ожидание: М(ei) = 0, i=1,2,…,n.
2.Равные дисперсии ошибок для всех наблюдений: D(ei) = s2, i=1,2,…,n.
3.Ошибки модели ei при разных наблюдениях независимы. В частности, корреляционный момент или как его чаще называют ковариация между ei и ej при i ¹ j равен 0: cov(ei, ej) = 0 для i ≠ j, i,j=1,2,…,n.
4.Для всех i = 1, 2, 3 … n случайные ошибки ei распределены по нормальному закону.
Отметим, что сформулированные выше условия называют условиями Гаусса- Маркова.
Одним из показателей качества построенного уравнения регрессии является коэффициент детерминации R2. По определению
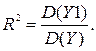 (2.6)
(2.6)
Покажем, что, в свою очередь, D(Y)= D(Y1)+D(  ). В самом деле,
). В самом деле,

Но 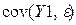 =
= 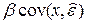 = 0. Что и требовалось. Отсюда
= 0. Что и требовалось. Отсюда
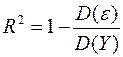 . (2.7)
. (2.7)
Таким образом, коэффициент детерминации можно интерпретировать как часть общей дисперсии Y, которая объяснена с помощью уравнения регрессии, точнее, с помощью расчетной переменной Y1 уравнения регрессии. Максимальное значение коэффициента детерминации R2 равно 1. Это произойдет тогда, когда все остатки eI = 0, а уравнение прямой регрессии ляжет точно на экспериментальные точки Yi. Таким образом, желательно максимизировать при построении регрессии коэффициент детерминации R2. Но оказывается, что это и делается при применении метода наименьших квадратов, так как из формулы (2.7) вытекает, что максимум R2 достигается при минимуме D(e).
Проведем дисперсионный анализ уравнения регрессии, построенного выше:  = 0,924 + 0,658 xi. По данным табл. 2.1, используя возможности пакета STATISTICA, имеем:
= 0,924 + 0,658 xi. По данным табл. 2.1, используя возможности пакета STATISTICA, имеем:
Таблица 2.4

Итак, D( ) = 35,7; D(
) = 35,7; D( ) = 2,525; D(Y) = 38,226. Отсюда,
) = 2,525; D(Y) = 38,226. Отсюда,  2 = 35,7/38,226 = 0,934.
2 = 35,7/38,226 = 0,934.
Значение 2 близко к единице. Это указывает на хорошее (адекватное) описание объясняемой переменной Y полученным уравнением регрессии.
Сейчас наступил момент, когда следует признать, что истинных значений коэффициентов a и b модели нам никогда не удастся найти. Найденные по методу МНК коэффициенты являются лишь выборочными оценками истинных коэффициентов. Поэтому, в отличие от параметров a и b, мы их обозначили a и b. Выборочные оценки a и b являются случайными величинами, так как зависят от выборки xi и Yi, а также от выбранного метода расчета. Поэтому, как это принято в математической статистике, возникает вопрос о несмещенности, эффективности и состоятельности оценок a и b, полученных по МНК. Следует также рассмотреть вопрос о построении доверительных интервалов для a и b.
Из формул (2.5) теперь следует, что
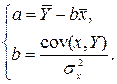 (2.8)
(2.8)
Так как Y= a+bx+e, то cov(x,Y)= cov(x, a+bx+e)= cov(x, bx)+ cov(x, e)=
= bcov(x, x)+ cov(x, e)==bD(x)+ cov(x, e). Следовательно,
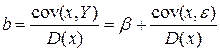 . (2.9)
. (2.9)
Итак, выборочный коэффициент регрессии представляется в виде суммы двух слагаемых: истинного значения b и случайной составляющей, зависящей от cov(x, e). Аналогично, коэффициент a можно разложить на сумму истинного коэффициента a и случайной составляющей:
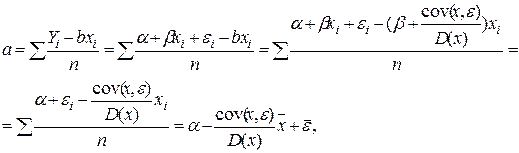 (2.10)
(2.10)
где  , i=1,2,…,n.
, i=1,2,…,n.
Из формул (2.9) и (2.10) вытекает важное следствие. Если случайную ошибку e увеличить в k раз, то есть заменить ошибкой ke, то ошибка при определении параметров a и b тоже увеличится в k раз. Это вытекает из соотношения
cov(x, ke) = k cov(x, e).
Если нет возможности проверить качество полученного уравнения регрессии на независимой выборке, то проводят оценку значимости уравнения регрессии по F-критерию Фишера. Выдвигается нулевая гипотеза, что коэффициент регрессии b = 0, то есть Y и x независимы. Конкурирующая гипотеза — b ¹ 0. Обратимся к равенству
D(Y)= D(a + b x)+D(e), (2.11)
В условиях нулевой гипотезы: D(Y) = D(a) + b2D(x) + D(e) = D(e). Следовательно, нулевая гипотеза эквивалентна гипотезе R2 = 0.
Рассмотрим линейное уравнение регрессии МНК i = a + bxi, используя формулы (2.8):
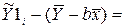
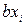 или
или 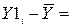
 .
.
Последнее равенство возведем в квадрат и просуммируем по всем наблюдениям i = 1, 2, … n. Получаем

 (2.12)
(2.12)
Из формулы (2.12) вытекает, что расчетное значение  является функцией единственного параметра
является функцией единственного параметра 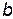 - коэффициента регрессии. Этот факт означает, что сумма квадратов
- коэффициента регрессии. Этот факт означает, что сумма квадратов 
 , стоящая в числителе D() имеет одну степень свободы.
, стоящая в числителе D() имеет одну степень свободы.
Хорошо известно, что число степеней свободы для суммы квадратов, стоящей в числителе дисперсии n независимых наблюдений равно n – 1. Далее, из теории дисперсионного анализа известно, что разложение суммы квадратов на слагаемые влечет соответствующее разложение для степеней свободы слагаемых. Поэтому число степеней свободы суммы квадратов стоящей в числителе D(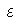 ) равно n – 1 – 1 = n – 2. Далее используем обычную процедуру сравнения дисперсий с различными степенями свободы по F-критерию Фишера. Построим исправленные суммы квадратов:
) равно n – 1 – 1 = n – 2. Далее используем обычную процедуру сравнения дисперсий с различными степенями свободы по F-критерию Фишера. Построим исправленные суммы квадратов:
 ;
; 
 ; (2.13)
; (2.13)
 . (2.14)
. (2.14)
По таблицам критических значений Фишера (приложение 5) находим критическое значение критерия  где g - выбранный заранее уровень значимости критерия (то есть вероятность признать регрессию значимой, в то время как регрессия незначима). Если регрессия значима, то
где g - выбранный заранее уровень значимости критерия (то есть вероятность признать регрессию значимой, в то время как регрессия незначима). Если регрессия значима, то 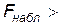
 в противном случае
в противном случае 
 Уровень значимости g обычно выбирают равным 0,1; 0,05; 0,01; 0,001. Но при использовании компьютерных расчетов удобнее не выбирать фиксированное g, а произвести расчет вероятности ошибочно признать регрессию значимой при данном значении
Уровень значимости g обычно выбирают равным 0,1; 0,05; 0,01; 0,001. Но при использовании компьютерных расчетов удобнее не выбирать фиксированное g, а произвести расчет вероятности ошибочно признать регрессию значимой при данном значении  . Так в табл. 2.4 посчитаны значения
. Так в табл. 2.4 посчитаны значения  ;
;  ,
, 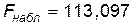 и вероятность того, что регрессия незначима P=0,000005. Поэтому вывод о значимости уравнения регрессии можно считать вполне обоснованным.
и вероятность того, что регрессия незначима P=0,000005. Поэтому вывод о значимости уравнения регрессии можно считать вполне обоснованным.
Несмещенность коэффициентов регрессии. Как известно из курса математической статистики, несмещенность выборочной оценки qвыб параметра генеральной совокупности qген означает, что математическое ожидание qвыб равно qген. Докажем несмещенность МНК оценок коэффициентов a и b. Надо показать, что М(a) = a и М(b) = b. Из (2.9), (2.10), свойств математического ожидания и условия 1 Гаусса-Маркова, получаем
 ;
;
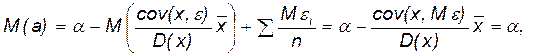
что и требовалось.
В курсе математической статистики определяется теоретический коэффициент корреляции, являющийся мерой линейной связи между случайными величинами x и y:
 . (2.15)
. (2.15)
Соответственно определяется выборочный коэффициент корреляции r(x, y):
 . (2.16)
. (2.16)
Из формулы (2.8) вытекает, что
 , (2.17)
, (2.17)
а уравнение линейной регрессии можно записать в виде:
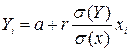 , i = 1, 2, … n. (2.18)
, i = 1, 2, … n. (2.18)
Покажем, что теоретический коэффициент детерминации равен квадрату теоретического коэффициента корреляции между фактическими Y и теоретическими прогнозными значениями Y1=a + bx = M():
r(Y, Y1) = 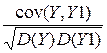 =
= 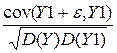 =
= 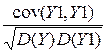 =
= 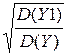 .
.
Далее, для построения доверительных интервалов для коэффициентов a и b нам понадобятся формулы для расчета дисперсий коэффициентов модели a и b. Имеем
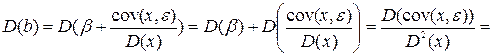
 .
.
Но, 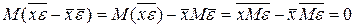 . Следовательно,
. Следовательно,
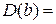



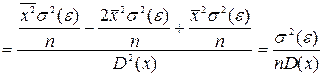 .
.
Окончательно,

 . (2.19)
. (2.19)
Аналогично получаем, что
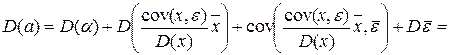
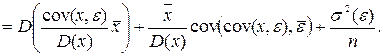
Но
 =
= 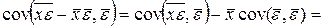
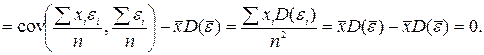
Наконец, ранее было доказано, что
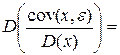
 , поэтому
, поэтому  =
=  .
.
Окончательно,
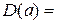
 =
=  (2.20)
(2.20)
Из формул (2.19) и (2.20) можно заключить, что теоретическая дисперсия коэффициентов регрессии зависит от отношения дисперсий случайных ошибок и фактора x. С ростом числа наблюдений n к бесконечности дисперсии коэффициентов стремятся к нулю, что вместе с доказанной выше несмещенностью оценок a и b влечет состоятельность МНК коэффициентов регрессии.
В теории регрессионного анализа также доказывается, что a и b в условиях Гаусса-Маркова являются эффективными оценками, то есть имеют минимальную дисперсию.
На практике теоретическую оценку дисперсии коэффициентов a и b получить невозможно, так как неизвестно точное значение дисперсии случайной ошибки  , но, оценив дисперсию остатков, можно получить выборочную дисперсию случайных ошибок.
, но, оценив дисперсию остатков, можно получить выборочную дисперсию случайных ошибок.
Как уже отмечалось выше, число степеней свободы суммы квадратов стоящей в числителе D(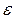 ) равно n – 2. Следовательно, исправленная выборочная дисперсия случайных ошибок равна:
) равно n – 2. Следовательно, исправленная выборочная дисперсия случайных ошибок равна:

 .
.
Из (2.19), (2.20) получаем исправленные выборочные оценки стандартных отклонений (ошибок) МНК коэффициентов регрессии:
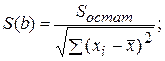
 (2.21)
(2.21)
Если были бы известны стандартные отклонения s(a) и s(b), то величины Za = (a – a)/s(a), и Zb = (b – b)/s(b) были бы распределены по нормальному закону с нулевым математическим ожиданием и единичной дисперсией: Za ~ N (0, 1); Zb ~ N (0, 1). Но так как нам известны только выборочные значения стандартных отклонений (стандартные ошибки) S(b) и S(a), то соответствующие соотношения ta = (a - a)/S(a), и tb = (b - b)/S(b) распределены по закону Стьюдента с числом степеней свободы n = n - 2.
Заметим, что при n > 30 распределение Стьюдента практически не отличается от нормального распределения (Приложение 4). С учетом сказанного можно построить доверительные интервалы для коэффициентов a и b и, если окажется, что в доверительный интервал попадает 0, то соответствующий коэффициент регрессии объявляется незначимым.
Чаще всего незначимые коэффициенты исключают из уравнения регрессии. При расчете уравнения регрессии на компьютере для проверки значимости коэффициентов регрессии вычисляются наблюдаемые значения критерия Стьюдента ta и tb при a = 0; b = 0 и вероятности pa, pb того, что случайная величина, распределенная по критерию Стьюдента, превысит наблюдаемые значения ta и tb по абсолютной величине. Если эти вероятности малы (меньше выбранного уровня значимости, например, 0,05), то коэффициенты считаются значимыми. В противном случае – незначимыми. Так, построив регрессию 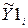 = 0,924 + 0,658 xi по данным табл. 2.1, получаем
= 0,924 + 0,658 xi по данным табл. 2.1, получаем
Таблица 2.5

S(b) = 0,061856, tb = 10,63472, pb = 0,000005; S(a) = 0,383809; ta = 2,40696; pa = 0,04271.
Из полученных результатов следует значимость коэффициентов a и b при уровне значимости 0,05. Как правило, в уравнении регрессии значения стандартных ошибок S(a) и S(b) записывают в скобках под соответствующими коэффициентами. Иногда ниже записывают тоже в скобках значения t-критерия:
= 0,924 + 0,658 x.
S (0,383809) (0,061856)
t (2,40696) (10,63472)