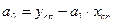 .
.
Воспользуемся этими формулами, а необходимые промежуточные результаты вычислений приведем в табл. 2.7.
Итак:
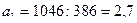 ,
,
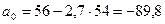 ,
,
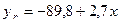 .
.
Расчетные значения определяются путем последовательной подстановки в эту модель значения фактора:
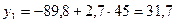
 и т.д.
и т.д.
Оценка качества модели на основе остаточной компоненты Еt дала следующие результаты: 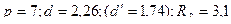 . Сопоставив эти значения с критическими уровнями, можно констатировать, что все свойства выполняются и, следовательно, построенная модель адекватна. Однако она имеет не очень хорошие точностные характеристики:
. Сопоставив эти значения с критическими уровнями, можно констатировать, что все свойства выполняются и, следовательно, построенная модель адекватна. Однако она имеет не очень хорошие точностные характеристики: 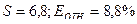 . Следовательно, данную модель можно использовать для анализа, но она недостаточно эффективна для получения прогнозных оценок.
. Следовательно, данную модель можно использовать для анализа, но она недостаточно эффективна для получения прогнозных оценок.
Пример 19.
Руководство предприятия поставило цель - в следующем году увеличить выручку от реализации продукции на 40 000 тыс. руб. за счет увеличения расходов на рекламу на 10 000 тыс. руб. Требуется проанализировать данную ситуацию и определить: будет ли выгодно для предприятия увеличить расходы на рекламу на указанную сумму, если известно, что коэффициент маржинальной прибыли на данном предприятии составляет 0,7.
Решение.
Зная коэффициент маржинальной прибыли, а также предполагаемый объем реализации, можно на основе формулы определить возможный прирост маржинальной прибыли (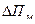 ):
):
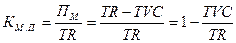 ,
,
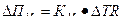
Где КМ — коэффициент маржинальной прибыли;
 - прирост выручки от реализации продукции.
- прирост выручки от реализации продукции.
Таким образом  = 0,7 • 40 000 = 28 000 тыс. руб.
= 0,7 • 40 000 = 28 000 тыс. руб.
Поскольку увеличение расходов на рекламу можно отнести к постоянным расходам, то используя формулу (3.4.8), определяется прирост чистой прибыли предприятия за счет возможного роста выручки от реализации продукции:
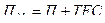 ,
,
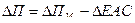
где 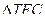 - увеличение расходов на рекламу.
- увеличение расходов на рекламу.
 = 28 000 - 10 000 = 18 000 тыс. руб.
= 28 000 - 10 000 = 18 000 тыс. руб.
Поскольку от увеличения расходов на рекламу на 10 000 тыс. руб. возможен рост прибыли на сумму 18 000 тыс. руб., для предприятия выгодно увеличить расходы на рекламу.
Пример 20.
Определить влияние рекламных мероприятий на изменение объема сбыта. Имеются следующие данные о бюджете имиджеобразующей рекламы (R) темпе продаж фирмы (Т), полученные в результате рекламной акции (табл. 1.24)
Таблица 1.24
| Темп продаж, % (Т) | 17,28 | 17,05 | 18,3 | 18,8 | 19,2 | 18,5 |
| Рекламный бюджет, тыс.руб. (R) |
Решение.
Предполагая, что между переменными R и Т существует линейная зависимость, найдем эмпирическую формулу вида Т=аR+b методом наименьших квадратов. Решение представим в виде табл. 1.25.
 Система нормальных уравнений в общем случае имеет вид:
Система нормальных уравнений в общем случае имеет вид:
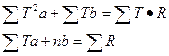
Таблица 1.25
| Т | R | T  R R
| Т2 |
| 17,28 | 9279,36 | 298,59 | |
| 17,05 | 9104,7 | 290,70 | |
| 18,3 | 10065,0 | 334,89 | |
| 18,8 | 10434,0 | 353,44 | |
| 19,2 | 10752,0 | 368,64 | |
| 18,5 | 10212,0 | 342,25 | |
| 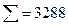
| 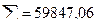
| 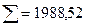
|
В нашем случае система уравнений примет вид:
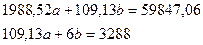
Её решение а=12,078, b= 328,32 дает искомую зависимость:
Т=12,08R+328,32.
Таким образом, с увеличением рекламного бюджета на 1 ден.ед сбыт фирмы растет на 12,08 %.
Стимулирование сбыта.
Пример 1.
Возьмем конкретные данные о затратах на стимулирование продаж по месяцам (Табл.2.1) и построим для них линейную модель.
Решение.
В табл. 2.1 приведены промежуточные вычисления и результаты использования линейной модели. В нижней строке записаны суммы значений в колонках.
Таблица 2.1
| t | Факт y | t - tcp | (t - tcp)2 | y - ycp | (t - tcp) (y-ycp) | Расчет yp | Отклонение Et |
| -4 -3 -2 -1 | -31 -22 -14 -5 -1 | 27,5 34,6 41,7 48,9 56,0 63,1 70,3 77,4 84,5 | -2,5 -0,6 0,3 2,1 -1,0 3,9 2,7 -1,4 -3,5 | ||||
Исходя из первых двух, легко определить: 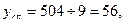
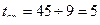 .
.
Параметры линейного уравнения рассчитаем по формулам:
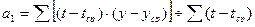 ,
,
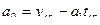
где tcp – среднее значение фактора времени;
ycp – среднее значение исследуемого показателя.
Подставляя рассчитанные значения в вышеприведенную формулу, получаем:
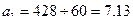 ,
,
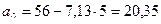 .
.
Таким образом линейная модель имеет вид:
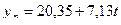
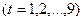 .
.
Последовательно подставляя в модель вместо фактора t его значения от 1 до N, получаем расчетные значения уровней yp:
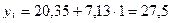 ,
,
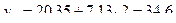 .
.
Вычислим отклонения расчетных значений от фактических наблюдений 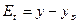 :
:
 ,
,
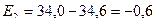 и т.д.
и т.д.
Отражает ли эта модель закономерность изменения исследуемого показателя, иными словами можно ли полученные значения yp рассматривать как тенденцию? Для ответа на этот вопрос оценим качество модели, или ее адекватность исследуемому процессу. Последняя характеризуется выполнением определенных статистических свойств и точностью, т. е. степенью близости к фактическим данным. Модель считается хорошей со статистической точки зрения, если она адекватна и достаточно точна.
Модель является адекватной, если математическое ожидание значений остаточного ряда близко или равно нулю, и если значения остаточного ряда случайны, независимы и подчинены нормальному закону распределения. Результаты исследования (оценка) адекватности вышеприведенной модели отражены в табл. 2.2.
Таблица 2.2
| t | Отклонение Et | Точка поворота | Et2 | Et-Et-1 | (Et-Et-1)2 | Et x Et-1 | Et: y x 100 |
| -2,5 -0,6 0,3 2,1 -1,0 3,9 2,7 -1,4 -3,5 | - - | 6,25 0,36 0,09 4,41 1,0 15,21 7,29 1,96 12,25 | - 1,9 0,9 1,8 -3,1 -4,9 -1,2 -4,1 -2,1 | - 3,61 0,81 3,24 9,61 24,01 1,44 16,81 4,41 | - 1,50 -0,18 0,63 -2,1 -3,9 10,53 -3,78 4,9 | 10,0 1,76 0,71 4,12 1,82 2,82 3,70 1,84 4,32 | |
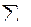
| 48,82 | - | 63,94 | 7,6 | 34,09 |
1. Проверка равенства математического ожидания уровней ряда остатков нулю осуществляется с использованием t-критерия Стьюдента:
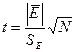 .
.
где 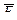 — среднее значение уровней остаточного ряда;
— среднее значение уровней остаточного ряда;
SЕ — среднее квадратическое отклонение уровней остаточного ряда.
Значение 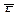 берется по модулю, без учета знака:
берется по модулю, без учета знака:
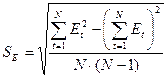 ,
,
Если 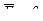 ,то
,то
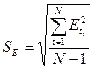 .
.
Гипотеза отклоняется, если t > t табл с заданным уровнем доверительной вероятности р.
При N = 9 и р = 70% t табл. = 1,05
В рассматриваемом примере = 0, поэтому гипотеза о равенстве математического ожидания значений остаточного ряда нулю выполняется.
2. Проверку случайности уровней ряда остатков проведем на основе критерия поворотных точек. В соответствии с ним каждый уровень ряда сравнивается с двумя рядом стоящими. Если он больше или меньше их, то эта точка считается поворотной. Далее подсчитывается сумма поворотных точек " р ". В случайном ряду чисел должно выполняться строгое неравенство:
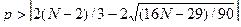 .
.
Квадратные скобки здесь означают, что от результата вычислений берется целая часть числа. При N = 9 в правой части неравенства имеем:
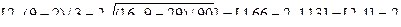 .
.
В табл. 2.2.2. в третьей графе для первого и последнего наблюдения проставим прочерк, ноль — если точка неповоротная, и единицу, если она поворотная. В нашем примере количество поворотных точек равно трем (р= =3), неравенство (2.10) выполняется, следовательно, свойство случайности выполняется.
3. При проверке независимости (отсутствия автокорреляции) опреде-ляется отсутствие в ряду остатков систематической составляющей. Это проверяется с помощью d-критерия Дарбина-Уотсона, в соответствии с которым вычисляется коэффициент d
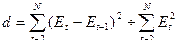 .
.
Вычисленная величина этого критерия сравнивается с двумя табличными уровнями (нижним d1 и верхним d2). Если d находится в интервале от нуля до d1, то уровни ряда остатков сильно автокоррелированы, а модель неадекватна. Если его значение попадает в интервал от d2 до 2, то уровни ряда являются независимыми. Если d превышает 2, то это свидетельствует об отрицательной корреляции и перед вводом в таблицу его величину надо преобразовать:
 . В нашем примере
. В нашем примере 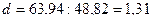 .
.
Для линейной модели при 9 наблюдениях можно взять в качестве критических табличных уровней величины d1=1,08 и d2=1,36 (см. Приложение 2). Следовательно, расчетное значение d попало в зону между d1 и d2, поэтому однозначного вывода сделать нельзя и необходимо применение других критериев, например, первого коэффициента автокорреляции, который вычисляется по формуле
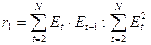 .
.
Если |r1| > rтабл . (при N < 15, r табл = 0,36), то присутствие в остаточном ряду существенной автокорреляции подтверждается. Для рассматриваемого примера r1 = 7,60: 48,82 = 0,16. Следовательно, по этому критерию выполняется свойство независимости уровней остаточной компоненты.
4. Соответствие ряда остатков нормальному закону распределения определим при помощи RS-критерия
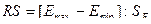 .
.
где Emax — максимальный уровень ряда остатков;
Emin — минимальный уровень ряда остатков;
SE — среднее квадратическое отклонение.
Если значение этого критерия попадает между табулированными границами с заданным уровнем вероятности, то гипотеза о нормальном распределении ряда остатков принимается. Для N = 10 и 5%-ного уровня значимости этот интервал равен (2,7—3,7)(см. Приложение 2).
В нашем примере: Еmах - 3,9 и Еmin = -3,5, а размах 7,4.
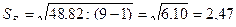
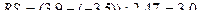 .
.
Расчетное значение попадает в интервал. Следовательно, свойство нормальности распределения выполняется, что позволяет строить доверительный интервал прогноза.
Для характеристики точности воспользуемся средней относительной ошибкой:
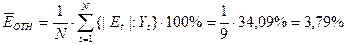
Величина менее 5 % свидетельствует о хорошем уровне точности модели (ошибка до 15 % считается приемлемой).
Точечный прогноз на k шагов вперед получается путем подстановки в модель параметра t = N + 1,..., N + k. При прогнозировании на два шага имеем:
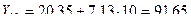 ,
,
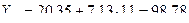 .
.
Доверительный интервал прогноза будет иметь следующие границы:
Верхняя граница прогноза = 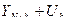 ,
,
Нижняя граница прогноза = 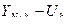 .
.
Величина Uk для линейной модели имеет вид:
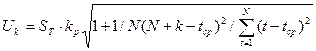
где ST — среднее квадратическое отклонение от линии тренда.
Если в качестве линии тренда используется уравнение прямой, то:
 или
или 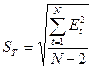 .
.
Для нашего примера
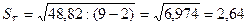 .
.
Коэффициент kр является табличным значением t-статистики Стьюдента. Если исследователь задает уровень вероятности попадания прогнозируемой величины внутрь доверительного интервала равный 70 %, то kр = 1,05, и, следовательно:
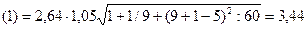 ,
,
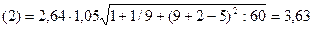 .
.
В табл. 2.6 сведены результаты расчетов прогнозных оценок по линейной модели по формуле (2.3.).
Таблица 2.3.
| Время t | Шаг k | Прогноз Yp | Нижняя граница | Верхняя граница |
| 91,65 98,78 | 88,21 95,15 | 95,09 102,41 |
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития, прогнозируемая величина попадает в интервал, образованный нижней и верхней границами. В нашем случае модель полностью адекватна исследуемому процессу и, следовательно, такое утверждение правомерно.
Паблисити
Пример 1
Фирма «Колгейт –Палмолив» обратилась к двум независимым экспертам для исследования десяти зубных щеток по предпочтениям потребителей.
1-Классика Плюс
2Зигзаг
3Премьер ультра
4 Массажер
5Сенсейшен
6 Навигатор
7Отбеливающая
8Вектор чистоты
9Электрическая з\щ Moushn
10 з\щ 360º
(По 10-ти бальной шкале)
Таблица 3.1.
| Эксперты | Товары | |||||||||
| 3,3 | 4,3 | 4,4 | 6,5 | 4,3 | 6,2 | 7,3 | 6,7 | 7,5 | 7,8 | |
| 2,4 | 5,5 | 5,2 | 7,2 | 5,5 | 4,9 | 5,5 | 6,1 | 6,7 | 8,4 |
Найдем степень согласия экспертов по оценке зубных щеток фирмы «Колгейт –Палмолив».
Решение:
Таблица 3.2.
| Эксперты | Товары | |||||||||
| 3,3 | 4,3 | 4,4 | 6,5 | 4,3 | 6,2 | 7,3 | 6,7 | 7,5 | 7,8 | |
| 2,4 | 5,5 | 5,2 | 7,2 | 5,5 | 4,9 | 5,5 | 6,1 | 6,7 | 8,4 | |
| di | 0,9 | -1,2 | -0,8 | -0,7 | -1.2 | 1,3 | 1,8 | 0.6 | 0,8 | -0,6 |
| di2 | 0,81 | 1,44 | 0,64 | 0,49 | 1,44 | 1,69 | 3,24 | 0,36 | 0,64 | 0,36 |
| R(di2) | 11,11 |
1. Определим расстояние между рангами d=?
d=r 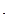 -r
-r 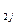
d 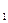 = 3,3-2,4=0,9
= 3,3-2,4=0,9
d  =4,3-5,5=-1,2
=4,3-5,5=-1,2
d  =4,4-5,2=-0,8
=4,4-5,2=-0,8
d =6,5-7,2=-0,7
d 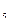 =4,3-5,5=-1,2
=4,3-5,5=-1,2
d 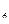 =6,2-4,9=1,44
=6,2-4,9=1,44
d  =7.3-5,5= 1,8
=7.3-5,5= 1,8
d 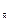 =6,7-6,1=0,6
=6,7-6,1=0,6
d 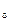 =7,5-6,7= 0,8
=7,5-6,7= 0,8
d 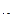 =7,8- 8,4=-0,6
=7,8- 8,4=-0,6
d 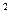 =0,9²=0,81
=0,9²=0,81
d 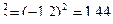 и т.д. до d
и т.д. до d 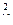
2.Определим этот ранг:
R(d²)= 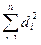
R(d²)= (0,81+1,44+0,64+0,49+1,44+1,69+3,24+0,36+0,64+0,36)=11,11
3.Находим коэффициенты парной ранговой корреляции:
P=1- 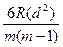 ,где m–число товаров, m=10 зубных щеток фирмы «Колгейт –Палмолив.
,где m–число товаров, m=10 зубных щеток фирмы «Колгейт –Палмолив.
P=1- 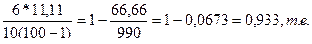
p 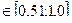 - низкий риск, независимые эксперты компетентны, можно доверять
- низкий риск, независимые эксперты компетентны, можно доверять
p 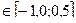 -высокий риск,независимые эксперты не компетентны
-высокий риск,независимые эксперты не компетентны
Ответ: Фирма «Колгейт –Палмолив» может доверять и верить мнению независимых экспертов и полагаться на эти данные в дальнейшем
Пример 2
Фирме «Колгейт Палмолив» недостаточно мнения 2-х экспертов, и она пригласила восемь разных независимых экспертов для исследования потребительского предпочтения по десяти зубным щеткам (см. задачу 1)
Найдем степень согласия экспертов по оценке зубных щеток фирмы «Колгейт Палмолив».
(По 10-ти бальной шкале).
Таблица 3.3.
| Эксперты | Товары | |||||||||
| 1-й | 3,3 | 4,3 | 4,4 | 6,5 | 4,3 | 6,2 | 7,3 | 6,7 | 7,5 | 7,8 |
| 2-й | 2,4 | 5,5 | 5,2 | 7,2 | 5,5 | 4,9 | 5,5 | 6,1 | 6,7 | 8,4 |
| 3-й | 2,5 | 4,5 | 6,1 | 7,4 | ||||||
| 4-й | 2,2 | 4,9 | 5,1 | 7,1 | 4,8 | 6,7 | 6,8 | 8,1 | ||
| 5-й | 2,4 | 4,5 | 4,5 | 6,1 | 7,2 | 6,3 | 6,5 | |||
| 6-й | 2,8 | 4,7 | 4,9 | 5,9 | 4,2 | 5,3 | 5,9 | 6,5 | 7,1 | 8,2 |
| 7-й | 2,1 | 5,1 | 4,6 | 6.3 | 5,4 | 5,3 | 5,9 | 6,9 | 7,8 | |
| 8-й | 1,8 | 4,3 | 4,8 | 7,2 | 4,8 | 5,9 | 5,8 | 6,4 | 7,2 | 7,9 |
Решение:
Таблица 3.4.
| Эксперты | Товары | |||||||||
| 1-й | 3,3 | 4,3 | 4,4 | 6,5 | 4,3 | 6,2 | 7,3 | 6,7 | 7,5 | 7,8 |
| 2-й | 2,4 | 5,5 | 5,2 | 7,2 | 5,5 | 4,9 | 5,5 | 6,1 | 6,7 | 8,4 |
| 3-й | 2,5 | 4,5 | 6,1 | 7,4 | ||||||
| 4-й | 2,2 | 4,9 | 5,1 | 7,1 | 4,8 | 6,7 | 6,8 | 8,1 | ||
| 5-й | 2,4 | 4,5 | 4,5 | 6,1 | 7,2 | 6,3 | 6,5 | |||
| 6-й | 2,8 | 4,7 | 4,9 | 5,9 | 4,2 | 5,3 | 5,9 | 6,5 | 7,1 | 8,2 |
| 7-й | 2,1 | 5,1 | 4,6 | 6.3 | 5,4 | 5,3 | 5,9 | 6,9 | 7,8 | |
| 8-й | 1,8 | 4,3 | 4,8 | 7,2 | 4,8 | 5,9 | 5,8 | 6,4 | 7,2 | 7,9 |
| ri | 19,5 | 37,3 | 38.5 | 53,3 | 37,7 | 43,2 | 49,0 | 50,6 | 55,7 | 63,6 |
| di | -24,5 | -6,7 | -5,5 | 9,3 | -6,3 | -0,8 | 5,0 | 6,6 | 11,7 | 19,6 |
| di2 | 600,25 | 44,89 | 30,25 | 86,49 | 39,69 | 0,64 | 25,00 | 43,56 | 136,89 | 384,16 |
| R(di2) | 1391,82 |
1.Определим ранг:
r 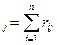
r = (3,3+2,4+2,5+2,2+2,4+2,8+2,1+1,8)=19,5
r = (4,3+5,5+4+4,9+4,5+4,7+5,1+4,3)=37,3…… и т.д. до r 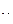
2.Рассчитаем среднее число:
а= 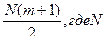 - число экспертов, m-число зубных щеток
- число экспертов, m-число зубных щеток
а= 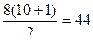
3.Определим ранг:
d 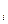 =
= 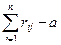
d =19,5- 44=-24,5